
Artificial intelligence has grown beyond language-focused systems, evolving into models capable of processing multiple input types, such as text, images, […]
Category: Computer Vision

Offline Video-LLMs Can Now Understand Real-Time Streams: Apple Researchers Introduce StreamBridge to Enable Multi-Turn and Proactive Video Understanding
Video-LLMs process whole pre-recorded videos at once. However, applications like robotics and autonomous driving need causal perception and interpretation of […]
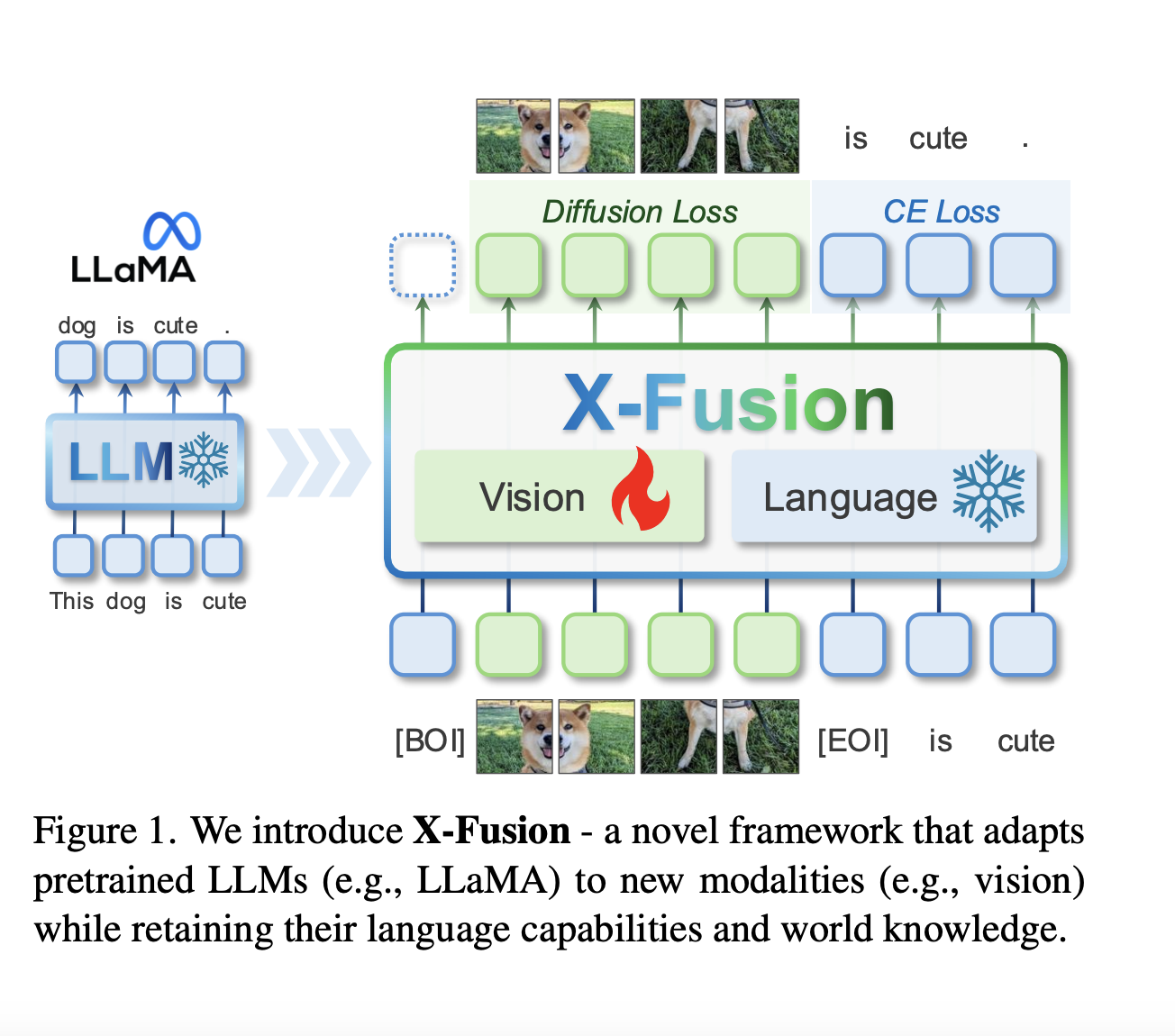
Multimodal LLMs Without Compromise: Researchers from UCLA, UW–Madison, and Adobe Introduce X-Fusion to Add Vision to Frozen Language Models Without Losing Language Capabilities
LLMs have made significant strides in language-related tasks such as conversational AI, reasoning, and code generation. However, human communication extends […]

Subject-Driven Image Evaluation Gets Simpler: Google Researchers Introduce REFVNLI to Jointly Score Textual Alignment and Subject Consistency Without Costly APIs
Text-to-image (T2I) generation has evolved to include subject-driven approaches, which enhance standard T2I models by incorporating reference images alongside text […]

UniME: A Two-Stage Framework for Enhancing Multimodal Representation Learning with MLLMs
The CLIP framework has become foundational in multimodal representation learning, particularly for tasks such as image-text retrieval. However, it faces […]
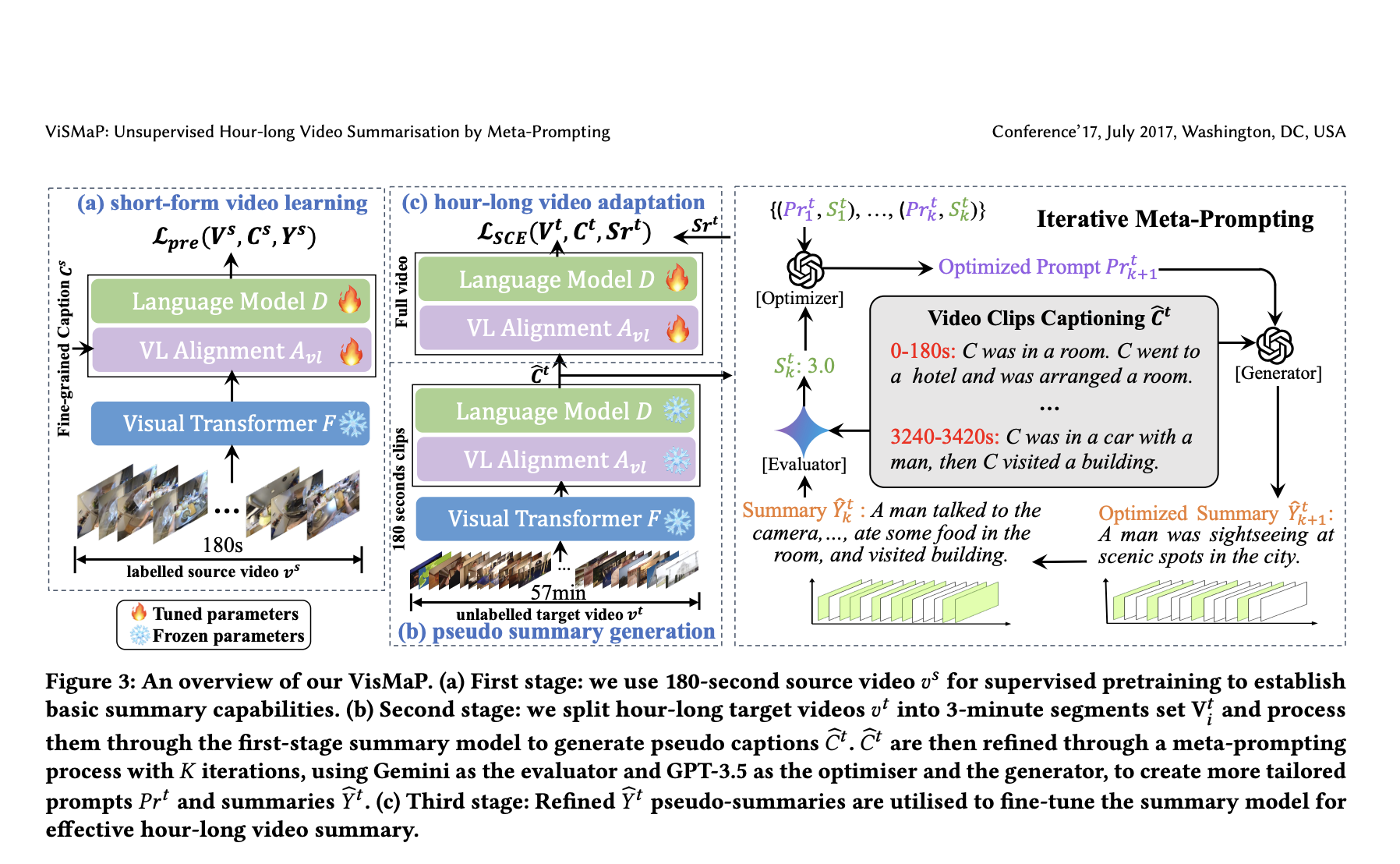
ViSMaP: Unsupervised Summarization of Hour-Long Videos Using Meta-Prompting and Short-Form Datasets
Video captioning models are typically trained on datasets consisting of short videos, usually under three minutes in length, paired with […]

Meta AI Introduces Token-Shuffle: A Simple AI Approach to Reducing Image Tokens in Transformers
Autoregressive (AR) models have made significant advances in language generation and are increasingly explored for image synthesis. However, scaling AR […]

Skywork AI Advances Multimodal Reasoning: Introducing Skywork R1V2 with Hybrid Reinforcement Learning
Recent advancements in multimodal AI have highlighted a persistent challenge: achieving strong specialized reasoning capabilities while preserving generalization across diverse […]

Microsoft Research Introduces MMInference to Accelerate Pre-filling for Long-Context Vision-Language Models
Integrating long-context capabilities with visual understanding significantly enhances the potential of VLMs, particularly in domains such as robotics, autonomous driving, […]

NVIDIA AI Releases Describe Anything 3B: A Multimodal LLM for Fine-Grained Image and Video Captioning
Challenges in Localized Captioning for Vision-Language Models Describing specific regions within images or videos remains a persistent challenge in vision-language […]