
The CLIP framework has become foundational in multimodal representation learning, particularly for tasks such as image-text retrieval. However, it faces […]
Category: Computer Vision
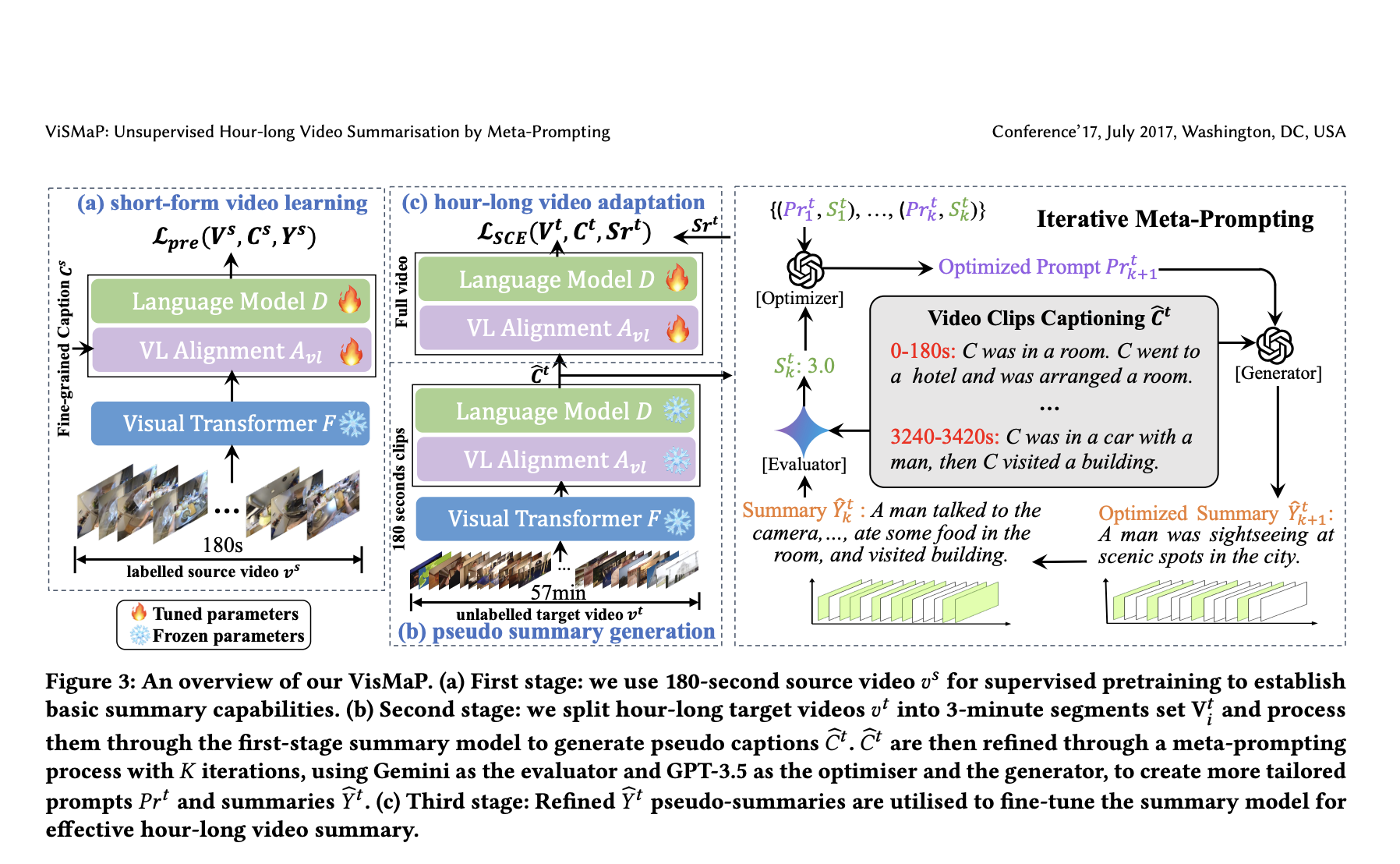
ViSMaP: Unsupervised Summarization of Hour-Long Videos Using Meta-Prompting and Short-Form Datasets
Video captioning models are typically trained on datasets consisting of short videos, usually under three minutes in length, paired with […]

Meta AI Introduces Token-Shuffle: A Simple AI Approach to Reducing Image Tokens in Transformers
Autoregressive (AR) models have made significant advances in language generation and are increasingly explored for image synthesis. However, scaling AR […]

Skywork AI Advances Multimodal Reasoning: Introducing Skywork R1V2 with Hybrid Reinforcement Learning
Recent advancements in multimodal AI have highlighted a persistent challenge: achieving strong specialized reasoning capabilities while preserving generalization across diverse […]

Microsoft Research Introduces MMInference to Accelerate Pre-filling for Long-Context Vision-Language Models
Integrating long-context capabilities with visual understanding significantly enhances the potential of VLMs, particularly in domains such as robotics, autonomous driving, […]

NVIDIA AI Releases Describe Anything 3B: A Multimodal LLM for Fine-Grained Image and Video Captioning
Challenges in Localized Captioning for Vision-Language Models Describing specific regions within images or videos remains a persistent challenge in vision-language […]

Decoupled Diffusion Transformers: Accelerating High-Fidelity Image Generation via Semantic-Detail Separation and Encoder Sharing
Diffusion Transformers have demonstrated outstanding performance in image generation tasks, surpassing traditional models, including GANs and autoregressive architectures. They operate […]

Long-Context Multimodal Understanding No Longer Requires Massive Models: NVIDIA AI Introduces Eagle 2.5, a Generalist Vision-Language Model that Matches GPT-4o on Video Tasks Using Just 8B Parameters
In recent years, vision-language models (VLMs) have advanced significantly in bridging image, video, and textual modalities. Yet, a persistent limitation […]

Stanford Researchers Propose FramePack: A Compression-based AI Framework to Tackle Drifting and Forgetting in Long-Sequence Video Generation Using Efficient Context Management and Sampling
Video generation, a branch of computer vision and machine learning, focuses on creating sequences of images that simulate motion and […]

Meta AI Released the Perception Language Model (PLM): An Open and Reproducible Vision-Language Model to Tackle Challenging Visual Recognition Tasks
Despite rapid advances in vision-language modeling, much of the progress in this field has been shaped by models trained on […]