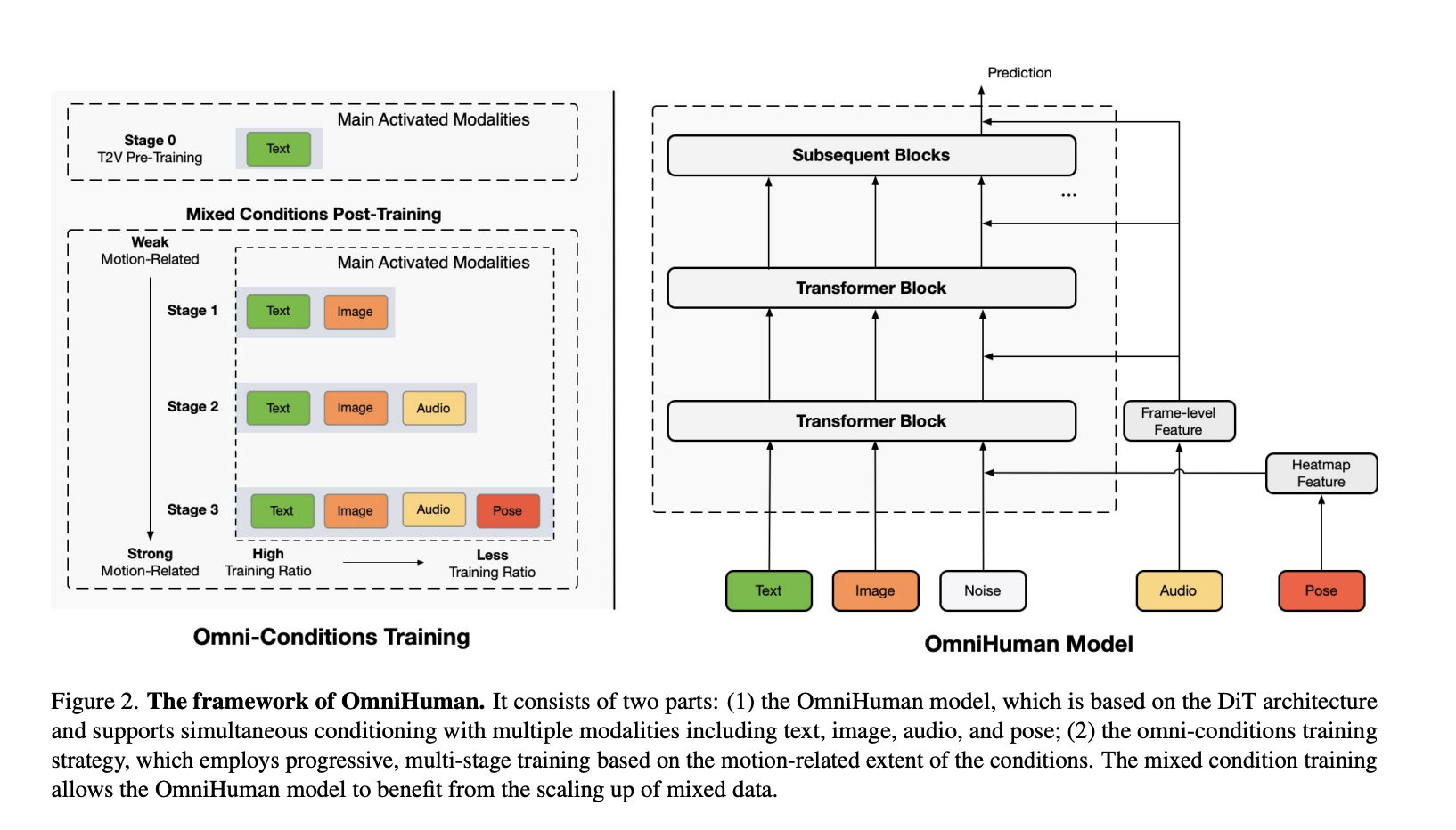
Despite progress in AI-driven human animation, existing models often face limitations in motion realism, adaptability, and scalability. Many models struggle […]
Category: Computer Vision
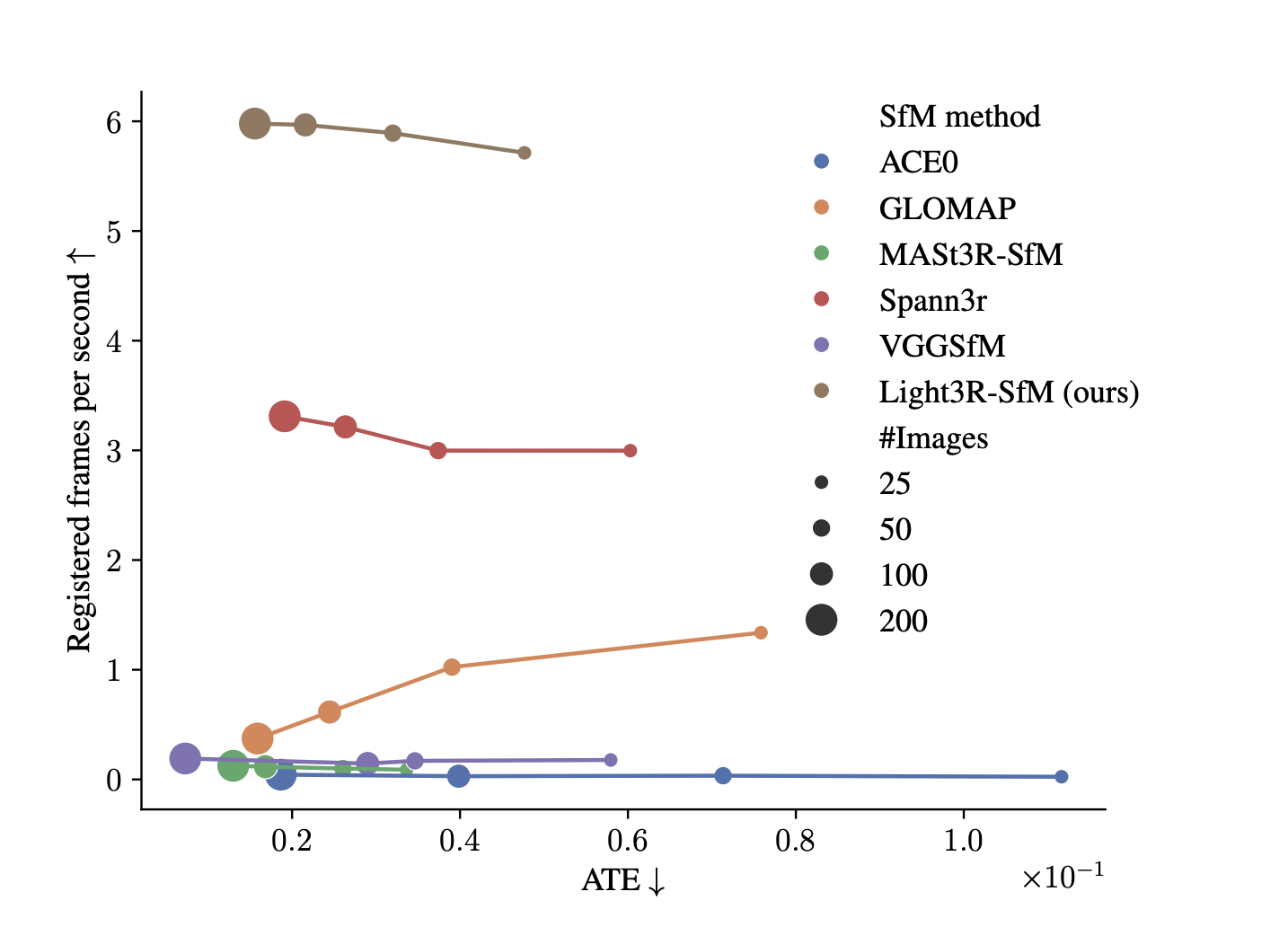
Light3R-SfM: A Scalable and Efficient Feed-Forward Approach to Structure-from-Motion
Structure-from-motion (SfM) focuses on recovering camera positions and building 3D scenes from multiple images. This process is important for tasks […]

InternVideo2.5: Hierarchical Token Compression and Task Preference Optimization for Video MLLMs
Multimodal large language models (MLLMs) have emerged as a promising approach towards artificial general intelligence, integrating diverse sensing signals into […]

This AI Paper Introduces IXC-2.5-Reward: A Multi-Modal Reward Model for Enhanced LVLM Alignment and Performance
Artificial intelligence has grown significantly with the integration of vision and language, allowing systems to interpret and generate information across […]

Netflix Introduces Go-with-the-Flow: Motion-Controllable Video Diffusion Models Using Real-Time Warped Noise
Generative modeling challenges in motion-controllable video generation present significant research hurdles. Current approaches in video generation struggle with precise motion […]
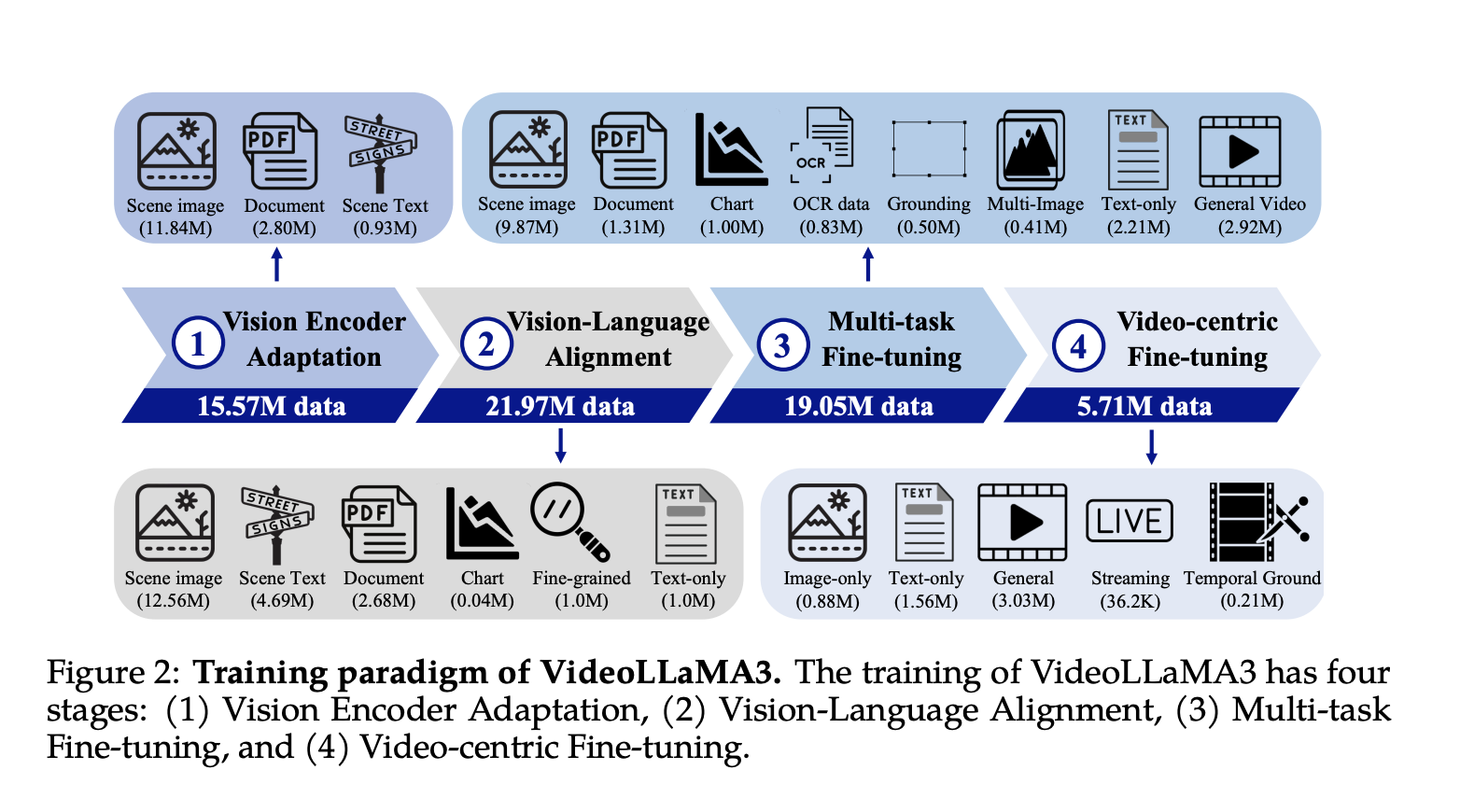
Alibaba Researchers Propose VideoLLaMA 3: An Advanced Multimodal Foundation Model for Image and Video Understanding
Advancements in multimodal intelligence depend on processing and understanding images and videos. Images can reveal static scenes by providing information […]

Introducing GS-LoRA++: A Novel Approach to Machine Unlearning for Vision Tasks
Pre-trained vision models have been foundational to modern-day computer vision advances across various domains, such as image classification, object detection, […]

Create Portrait Mode Effect with Segment Anything Model 2 (SAM2)
Have you ever admired how smartphone cameras isolate the main subject from the background, adding a subtle blur to the […]

Google AI Proposes a Fundamental Framework for Inference-Time Scaling in Diffusion Models
Generative models have revolutionized fields like language, vision, and biology through their ability to learn and sample from complex data […]
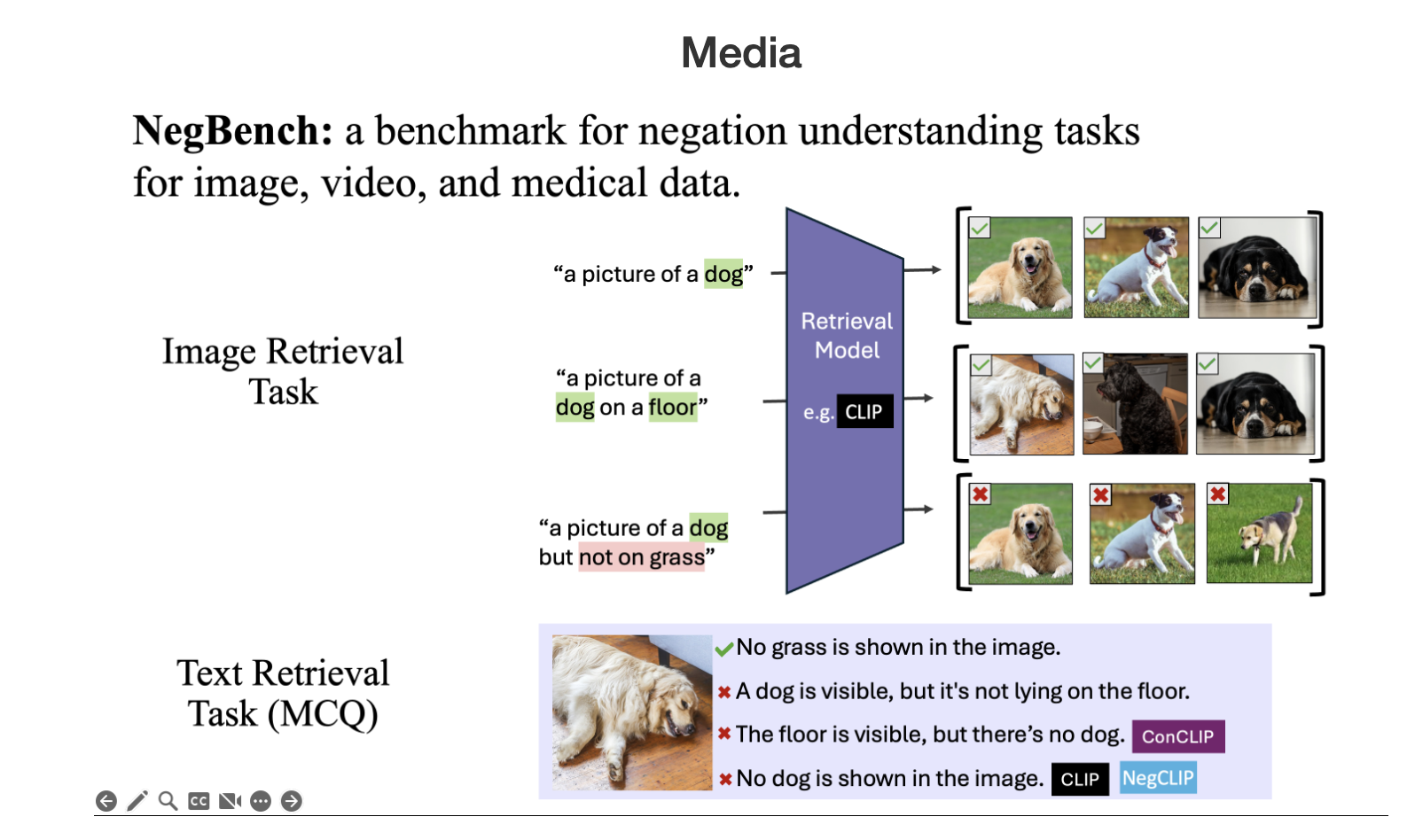
Researchers from MIT, Google DeepMind, and Oxford Unveil Why Vision-Language Models Do Not Understand Negation and Proposes a Groundbreaking Solution
Vision-language models (VLMs) play a crucial role in multimodal tasks like image retrieval, captioning, and medical diagnostics by aligning visual […]