
NVIDIA just released DeepStream 9.1. The update targets a persistent problem in video analytics. Tracking one object across many cameras […]
Category: Computer Vision

NVIDIA’s Cosmos-Framework Tutorial: Designing a Colab-Friendly Miniature of Cosmos 3 World Models with Omnimodal Mixture-of-Transformers
In this tutorial, we explore NVIDIA’s cosmos-framework from a practical Colab-friendly angle while staying honest about the hardware limits of […]
OCRmyPDF Tutorial: Convert Scanned Documents into Searchable PDF/A Files with Sidecar Text Extraction and Batch Processing
In this tutorial, we build an advanced, self-contained OCRmyPDF workflow. We start by installing the required system and Python dependencies, […]

Datalab Releases lift: A 9B Open-Weights Vision Model That Extracts Structured JSON From PDFs Using Schemas
Datalab has released lift, a 9B open-weights vision model for structured extraction. You pass it a JSON schema, and it […]
Zyphra Release Zamba2-VL: Hybrid Mamba2–Transformer Vision-Language Models That Cut Time-to-First-Token by About an Order of Magnitude
Zyphra has released Zamba2-VL, a family of open vision-language models. The release covers three sizes: 1.2B, 2.7B, and 7B parameters. […]

A Hands-On Coding Tutorial on Qualcomm AI Hub Models for Classification, Object Detection, and Hardware-Aware Deployment
In this tutorial, we work through an end-to-end workflow for Qualcomm AI Hub Models. We start by setting up the […]
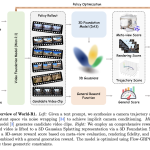
Microsoft Research’s World-R1 Uses Flow-GRPO and 3D-Aware Rewards to Inject Geometric Consistency Into Wan 2.1 Without Architectural Changes
Video foundation models can paint a beautiful frame. They are still notoriously bad at remembering it. Push the camera through […]

How to Build a Lightweight Vision-Language-Action-Inspired Embodied Agent with Latent World Modeling and Model Predictive Control
In this tutorial, we build an embodied simulation vision agent that learns to perceive, plan, predict, and replan directly from […]
Meta AI Releases Sapiens2: A High-Resolution Human-Centric Vision Model for Pose, Segmentation, Normals, Pointmap, and Albedo
If you’ve ever watched a motion capture system struggle with a person’s fingers, or seen a segmentation model fail to […]

Google DeepMind Introduces Vision Banana: An Instruction-Tuned Image Generator That Beats SAM 3 on Segmentation and Depth Anything V3 on Metric Depth Estimation
For years, the computer vision community has operated on two separate tracks: generative models (which produce images) and discriminative models […]