
What if the AI industry is optimizing for a goal that cannot be clearly defined or reliably measured? That is […]
Category: AI Paper Summary

Microsoft Releases Phi-4-Reasoning-Vision-15B: A Compact Multimodal Model for Math, Science, and GUI Understanding
Microsoft has released Phi-4-reasoning-vision-15B, a 15 billion parameter open-weight multimodal reasoning model designed for image and text tasks that require […]

YuanLab AI Releases Yuan 3.0 Ultra: A Flagship Multimodal MoE Foundation Model, Built for Stronger Intelligence and Unrivaled Efficiency
How can a trillion-parameter Large Language Model achieve state-of-the-art enterprise performance while simultaneously cutting its total parameter count by 33.3% […]
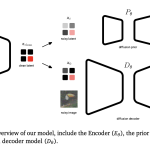
Google DeepMind Introduces Unified Latents (UL): A Machine Learning Framework that Jointly Regularizes Latents Using a Diffusion Prior and Decoder
Generative AI’s current trajectory relies heavily on Latent Diffusion Models (LDMs) to manage the computational cost of high-resolution synthesis. By […]

Sakana AI Introduces Doc-to-LoRA and Text-to-LoRA: Hypernetworks that Instantly Internalize Long Contexts and Adapt LLMs via Zero-Shot Natural Language
Customizing Large Language Models (LLMs) currently presents a significant engineering trade-off between the flexibility of In-Context Learning (ICL) and the […]
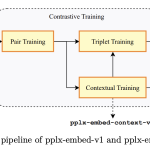
Perplexity Just Released pplx-embed: New SOTA Qwen3 Bidirectional Embedding Models for Web-Scale Retrieval Tasks
Perplexity has released pplx-embed, a collection of multilingual embedding models optimized for large-scale retrieval tasks. These models are designed to […]
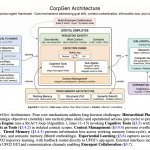
Microsoft Research Introduces CORPGEN To Manage Multi Horizon Tasks For Autonomous AI Agents Using Hierarchical Planning and Memory
Microsoft researchers have introduced CORPGEN, an architecture-agnostic framework designed to manage the complexities of realistic organizational work through autonomous digital […]
Google DeepMind Researchers Apply Semantic Evolution to Create Non Intuitive VAD-CFR and SHOR-PSRO Variants for Superior Algorithmic Convergence
In the competitive arena of Multi-Agent Reinforcement Learning (MARL), progress has long been bottlenecked by human intuition. For years, researchers […]
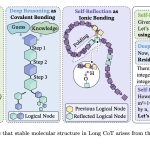
Forget Keyword Imitation: ByteDance AI Maps Molecular Bonds in AI Reasoning to Stabilize Long Chain-of-Thought Performance and Reinforcement Learning (RL) Training
ByteDance Seed recently dropped a research that might change how we build reasoning AI. For years, devs and AI researchers […]
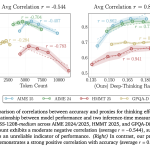
A New Google AI Research Proposes Deep-Thinking Ratio to Improve LLM Accuracy While Cutting Total Inference Costs by Half
For the last few years, the AI world has followed a simple rule: if you want a Large Language Model […]