Reinforcement learning for language agents is growing more complex. Agents now manage multi-turn tool use, long-running contexts, and multi-agent orchestration. The main engineering challenge is connecting existing agent software to training pipelines without breaking how those tools work.
NVIDIA’s research team introduced Polar, a rollout framework that lets researchers run reinforcement learning over any agent harness without modifying that harness.
The Core Problem Polar Solves
An ‘agent harness’ is a tool like Codex CLI, Claude Code, Qwen Code, or Pi. These harnesses manage system prompts, tool formatting, context engineering, and how the agent submits patches. These details directly affect agent behavior at evaluation time.
Traditional RL infrastructure requires harness logic to be rewritten behind a framework-owned environment API — typically env.init(), env.step(), env.reset() in the OpenAI Gym style. Every new harness requires new integration code. That integration can also lose execution details specific to the native harness path.
Polar’s key observation is that every LLM-based agent must call a model. That model API boundary is a common interface outside the agent itself. Instead of integrating inside the harness, Polar places a proxy at that boundary.
How the Proxy Works
For each incoming model request, the gateway proxy performs four steps:
- Detect the provider API — using the request path and headers, it distinguishes Anthropic Messages, OpenAI Chat Completions, OpenAI Responses, and Google generateContent-style calls.
- Normalize the request — converts roles, content parts, tool definitions, and generation parameters into the OpenAI Chat Completions shape used by the local inference server.
- Capture token-level data — stores request messages, response messages, prompt token IDs, sampled response token IDs, finish reason, and log probabilities.
- Return the provider shape — transforms the response back into the schema the harness expects.
For streaming requests, Polar obtains a non-streaming upstream response and emits a synthetic provider-shaped stream. This preserves compatibility with harnesses that expect server-sent events while ensuring complete token capture.
The only required change to an existing harness is pointing its model base URL at the gateway.

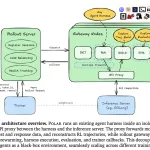
Architecture: Rollout Server and Gateway Nodes
Polar has two core components:
The rollout server accepts a TaskRequest and expands it into num_samples independent sessions. Each session carries a session ID, task ID, timeout budget, runtime specification, agent specification, trajectory builder, evaluator, and callback URL. The server dispatches sessions to gateway nodes and accepts callbacks when sessions complete.
Gateway nodes own the lifecycle of each session — starting the runtime, running the harness, building trajectories, evaluating output, and teardown. The gateway also hosts the proxy endpoint for that session’s model calls, keeping completion capture tied to the session registry.
Within each gateway, isolated worker pools handle INIT, RUNNING, and POSTRUN stages. A bounded READY buffer holds initialized runtimes until a run slot is available. CPU-heavy runtime preparation and evaluator prewarm proceed off the critical path, without blocking active GPU-bound agent execution. If a harness times out after model calls have been captured, the gateway still enters POSTRUN so partial traces can be recovered.
Built-in evaluators include a session-completion reward, a configurable test-on-output evaluator, and a SWE-Bench/SWE-Gym harness evaluator. Custom evaluators can be added through a registry interface.
Polar currently supports Docker and rootless Apptainer runtimes. Built-in harness shortcuts include codex, claude_code, gemini_cli, qwen_code, opencode, and pi.
Trajectory Reconstruction: Per Request vs. Prefix Merging
After a session completes, Polar reconstructs trainable trajectories from captured model calls.
Two strategies are available:
The per_request builder treats every model call as one independent trace. It is lossless per individual call but fragments multi-turn sessions. A single coding problem can produce hundreds of per-request traces, increasing the burden on downstream trainers.
The prefix_merging builder reconstructs longer traces where the harness session preserves append-only conversation histories. It partitions completions into ordered chains by verifying a strict token-prefix relation between adjacent completions. Sub-agents, context compaction boundaries, and parallel agent branches naturally form separate chains. Within each merged trace, only sampled assistant tokens are marked trainable. Canonical interstitial tokens receive a loss mask of zero.
Ablation Results
The research team benchmarks both strategies on the same model, hardware, and topology over three training steps.
| Metric | per_request |
prefix_merging |
|---|---|---|
| Trainer updates | 1,185 | 218 |
| Wall-clock time | 189.5 min | 35.2 min |
| Speedup | — | 5.39× |
| Avg. rollout GPU utilization | 20.4% | 87.7% |
SWE-Bench Verified Results
Training uses standard GRPO on the Qwen3.5-4B base model. The dataset is SkyRL-v0-293-data SWE-Gym (293 tasks, 1 epoch, rollout batch size 4, 16 samples per prompt) with the Slime trainer. All experiments use prefix_merging for trajectory construction.
Training Rollout Reward Progress (pass@1)
| Harness | First 10 Steps | Last 10 Steps |
|---|---|---|
| Codex | 9.5% | 54.5% |
| Claude Code | 28.8% | 67.0% |
| Qwen Code | 61.6% | 66.0% |
| Pi | 61.6% | 76.2% |
SWE-Bench Verified Final Scores
| Harness | Base | Polar RL | Gain |
|---|---|---|---|
| Codex | 3.8% | 26.4% | +22.6 pts |
| Claude Code | 29.8% | 34.6% | +4.8 pts |
| Qwen Code | 34.6% | 35.2% | +0.6 pts |
| Pi | 34.2% | 40.4% | +6.2 pts |
The largest gain is under Codex. Codex presents an unfamiliar action protocol and patch-submission style to a Qwen model not originally trained on that harness. Polar attaches the reward signal to the actual sampled tokens flowing through the Codex execution path, so GRPO optimizes the behavior the model uses at evaluation time. Under the native Qwen Code harness, where the base model is already well-aligned, Polar still delivers a 0.6 point gain.
Offline SFT Data Generation
Polar can also serve as a distributed offline data generation service with no changes to the runtime. The research team demonstrates this using Qwen3.5-122B-A10B on an 8×H100 server (TP=8, max_model_len=32,768) with the pi harness against 1,638 instances from seven SWE-Gym repositories.
A trajectory is accepted into the SFT corpus only if the SWE-Bench evaluation harness confirms the agent’s patch resolves every FAIL_TO_PASS test and leaves every PASS_TO_PASS test green.
| Repository | Attempts | Accepted | Rate |
|---|---|---|---|
| getmoto/moto | 343 | 184 | 53.6% |
| python/mypy | 257 | 101 | 39.3% |
| conan-io/conan | 71 | 27 | 38.0% |
| pydantic/pydantic | 81 | 24 | 29.6% |
| iterative/dvc | 219 | 45 | 20.5% |
| pandas-dev/pandas | 477 | 98 | 19.7% |
| dask/dask | 141 | 25 | 17.7% |
| Total | 1,638 | 504 | 30.8% |
The run cost roughly 64 GPU-hours. Accepted trajectories average 104 messages per session and 51 assistant turns.
Framework Comparison
| System | Async RL | Async Rollout Staging | Rollout as Service | Harness Agnostic |
|---|---|---|---|---|
| Polar | ✓ | ✓ | ✓ | ✓ |
| ProRL Agent | ✓ | ✓ | ✓ | ✗ |
| SkyRL-Agent | ✓ | ✓ | ✗ | partial |
| PRIME-RL | ✓ | ✗ | ✗ | ✗ |
| Agent Lightning | partial | ✗ | partial | partial |
| rLLM | partial | ✗ | ✗ | ✗ |
| OpenClaw-RL | ✓ | ✗ | ✗ | partial |
Polar is the only system in this comparison with first-class support across all four properties.
Strengths and Limitations
Strengths
- No harness code changes required — the proxy intercepts at the model API boundary
- Provider-agnostic: supports Anthropic, OpenAI Chat, OpenAI Responses, and Google API formats natively
prefix_mergingreduces trainer updates from 1,185 to 218 and cuts wall-clock time 5.39×- Works for both online RL and offline SFT data generation with the same runtime
- Harness-native RL delivers large gains for unfamiliar execution paths — 22.6 pts on Codex
- Partial traces are recovered when a harness times out mid-session
- Released as open source under NeMo Gym
Limitations
- Reward design, evaluator quality, and distribution shift remain the researcher’s responsibility
- Requires the harness to support a configurable model base URL
- Token-level capture depends on the serving stack supplying reliable token IDs and log probabilities
per_requeststrategy produced reward hacking in experiments due to noisy credit assignment at the session level; session normalization and PRM-style credit assignment are on the roadmap
Marktechpost’s Visual Explainer
NVIDIA Research Polar — Agentic RL Framework
arXiv:2605.24220
NeMo Gym — May 2026
Polar: Agentic RL
on Any Harness
NVIDIA’s rollout framework trains LLM agents via RL without modifying their harnesses. A model API proxy captures token-level interactions and reconstructs trainer-ready trajectories.
GRPO Training Token-Faithful Trajectories SWE-Bench Verified Apache-2.0 NeMo Gym
01 — The Problem
Why RL Integration With Agent Harnesses Is Hard
Harnesses like Codex CLI, Claude Code, Qwen Code, and Pi manage system prompts, tool formatting, and patch submission. Traditional RL requires rewriting this logic behind a framework-owned environment API.
1
Every new harness requires new integration code
Systems like SkyRL-Agent and PRIME-RL require agents to conform to RL infrastructure, not the other way around.
2
Integration loses native execution details
Rewriting a harness behind an env API can drop context policies, tool schemas, and orchestration logic that matter at eval time.
3
Polar’s key insight
Every LLM-based agent must call a model. Polar places a proxy at that API boundary instead of integrating inside the harness.
02 — The Proxy
How Polar Captures LLM Calls (4 Steps)
The only change to an existing harness is pointing its model base URL at the gateway.
1
Detect the provider API
Distinguishes Anthropic Messages, OpenAI Chat Completions, OpenAI Responses, and Google generateContent from request path and headers.
2
Normalize the request
Converts roles, content parts, tool definitions, and generation parameters into the OpenAI Chat Completions shape for the local inference server.
3
Capture token-level data
Stores request messages, response messages, prompt token IDs, sampled response token IDs, finish reason, and log probabilities.
4
Return the provider shape
Transforms the response back into the schema the harness expects. Streaming requests receive a synthetic provider-shaped stream.
03 — Architecture
Rollout Server & Gateway Nodes
Rollout Server
Accepts a TaskRequest, expands into num_samples sessions. Each session carries session ID, task ID, timeout, runtime spec, agent spec, trajectory builder, evaluator, and callback URL. Dispatches to gateways and tracks status.
Gateway Nodes
Own the full session lifecycle: start runtime — run harness — build trajectories — evaluate — teardown. Worker pools INIT / READY / RUNNING / POSTRUN run in isolation. Times-out gracefully; partial traces are recovered.
Runtimes: Docker & rootless Apptainer
Built-in harnesses:
codex claude_code gemini_cli qwen_code opencode pi
Built-in evaluators:
session-completion reward test-on-output SWE-Bench / SWE-Gym harness
04 — Trajectory Reconstruction
per_request vs. prefix_merging
per_request
Every model call becomes one trace. Lossless per call but fragments multi-turn sessions. One coding problem can produce hundreds of traces. Produces reward hacking at session level due to noisy credit assignment.
prefix_merging
Reconstructs longer traces via strict token-prefix relation. Sub-agents, context compaction, and parallel branches form separate chains. Only sampled tokens are trainable; interstitials are loss-masked to zero.
Ablation — same model, hardware & topology, 3 training steps
| Metric | per_request | prefix_merging |
|---|---|---|
| Trainer updates | 1,185 | 218 |
| Wall-clock time | 189.5 min | 35.2 min |
| Speedup | — | 5.39× |
| Avg. rollout GPU util. | 20.4% | 87.7% |
05 — SWE-Bench Verified Results
GRPO on Qwen3.5-4B Across Four Harnesses
SkyRL-v0-293-data — 293 tasks — 1 epoch — batch size 4 — 16 samples/prompt — Slime trainer — prefix_merging
| Harness | Base | Polar RL | Gain |
|---|---|---|---|
| Codex | 3.8% | 26.4% | +22.6 pts |
| Claude Code | 29.8% | 34.6% | +4.8 pts |
| Qwen Code | 34.6% | 35.2% | +0.6 pts |
| Pi | 34.2% | 40.4% | +6.2 pts |
+22.6 pts gain on Codex
(3.8% → 26.4%)
5.39× faster training with
prefix_merging
06 — Offline SFT Data Generation
Generating SFT Trajectories at Scale
Qwen3.5-122B-A10B — 8×H100 (TP=8, max_model_len=32,768) — pi harness — 1,638 instances — ~64 GPU-hours — Apache-2.0
| Repository | Attempts | Accepted | Rate |
|---|---|---|---|
| getmoto/moto | 343 | 184 | 53.6% |
| python/mypy | 257 | 101 | 39.3% |
| conan-io/conan | 71 | 27 | 38.0% |
| pydantic/pydantic | 81 | 24 | 29.6% |
| iterative/dvc | 219 | 45 | 20.5% |
| pandas-dev/pandas | 477 | 98 | 19.7% |
| dask/dask | 141 | 25 | 17.7% |
| Total | 1,638 | 504 | 30.8% |
Avg. 104 messages/session — 51 assistant turns — 90/10 train/test split by repository
07 — Key Takeaways
What Engineers Should Know
- Polar trains LLM agents via a model API proxy — no harness code changes required.
- Supports Anthropic Messages, OpenAI Chat Completions, OpenAI Responses, and Google generateContent APIs natively.
- prefix_merging cuts trainer updates from 1,185 to 218 and wall-clock time by 5.39× vs. per_request.
- GRPO on Qwen3.5-4B improves SWE-Bench Verified by up to 22.6 pts (Codex) across all four harnesses.
- Works for online RL and offline SFT data generation with the same runtime — no orchestration changes needed.
- Reward design, evaluator quality, and distribution shift remain the researcher’s responsibility.
- Code: github.com/NVIDIA-NeMo/ProRL-Agent-Server — registered as a NeMo Gym environment.
Marktechpost — AI Research, Simplified for Engineers arXiv:2605.24220
Key Takeaways
- Polar trains LLM agents via a model API proxy — no harness code changes required
- Supports Anthropic Messages, OpenAI Chat Completions, OpenAI Responses, and Google generateContent APIs
- Using GRPO on Qwen3.5-4B, Polar improves SWE-Bench Verified by up to 22.6 points across four coding harnesses
prefix_mergingtrajectory reconstruction delivers a 5.39× wall-clock speedup overper_request- Generated 504 accepted SFT trajectories from 1,638 attempts (30.8%) at ~64 GPU-hours; released under Apache-2.0
- Rewrites ProRL Agent; registered as a NeMo Gym environment
Check out the Paper and GitHub Repo. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us