Mistral AI has released Mistral OCR 3, its latest optical character recognition service that powers the company’s Document AI stack. The model, named as mistral-ocr-2512, is built to extract interleaved text and images from PDFs and other documents while preserving structure, and it does this at an aggressive price of $2 per 1,000 pages with a 50% discount when used through the Batch API.
What Mistral OCR 3 is Optimized for?
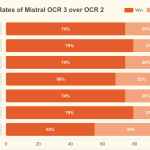
Mistral OCR 3 targets typical enterprise document workloads. The model is tuned for forms, scanned documents, complex tables, and handwriting. It is evaluated on internal benchmarks drawn from real business use cases, where it achieves a 74% overall win rate over Mistral OCR 2 across these document categories using a fuzzy match metric against ground truth.
The model outputs markdown that preserves document layout, and when table formatting is enabled, it enriches the output with HTML based table representations. This combination gives downstream systems both the content and the structural information that is needed for retrieval pipelines, analytics, and agent workflows.
Role in Mistral Document AI
OCR 3 sits inside Mistral Document AI, the company’s document processing capability that combines OCR with structured data extraction and Document QnA.
It now powers the Document AI Playground in Mistral AI Studio. In this interface, users upload PDFs or images and get back either clean text or structured JSON without writing code. The same underlying OCR pipeline is accessible via the public API, which allows teams to move from interactive exploration to production workloads without changing the core model.
Inputs, Outputs, And Structure
The OCR processor accepts multiple document formats through a single API. The document field can point to:
document_urlfor PDFs, pptx, docx and moreimage_urlfor image types such as png, jpeg or avif- Uploaded or base64 encoded PDFs or images through the same schema
This is documented in the OCR Processor section of Mistral’s Document AI docs.
The response is a JSON object with a pages array. Each page contains an index, a markdown string, a list of images, a list of tables when table_format="html" is used, detected hyperlinks, optional header and footer fields when header or footer extraction is enabled, and a dimensions object with page size. There is also a document_annotation field for structured annotations and a usage_info block for accounting information.
When images and HTML tables are extracted, the markdown includes placeholders such as  and [tbl-3.html](tbl-3.html). These placeholders are mapped back to actual content using the images and tables arrays in the response, which simplifies downstream reconstruction.
Upgrades Over Mistral OCR 2
Mistral OCR 3 introduces several concrete upgrades relative to OCR 2. The public release notes emphasize four main areas.
- Handwriting Mistral OCR 3 more accurately interprets cursive, mixed content annotations, and handwritten text placed on top of printed templates.
- Forms It improves detection of boxes, labels, and handwritten entries in dense layouts such as invoices, receipts, compliance forms, and government documents.
- Scanned and complex documents The model is more robust to compression artifacts, skew, distortion, low DPI, and background noise in scanned pages.
- Complex tables It reconstructs table structures with headers, merged cells, multi row blocks, and column hierarchies, and it can return HTML tables with proper
colspanandrowspantags so that layout is preserved.

Pricing, Batch Inference, And Annotations
The OCR 3 model card lists pricing at $2 per 1,000 pages for standard OCR and $3 per 1,000 annotated pages when structured annotations are used.
Mistral also exposes OCR 3 through its Batch Inference API /v1/batch, which is documented under the batching section of the platform. Batch processing halves the effective OCR price to $1 per 1,000 pages by applying a 50% discount for jobs that run through the batch pipeline.
The model integrates with two important features on the same endpoint, Annotations – Structured and BBox Extraction. These allow developers to attach schema driven labels to regions of a document and get bounding boxes for text and other elements, which is useful when mapping content into downstream systems or UI overlays.
Key Takeaways
- Model and role: Mistral OCR 3, named as
mistral-ocr-2512, is the new OCR service that powers Mistral’s Document AI stack for page based document understanding. - Accuracy gains: On internal benchmarks covering forms, scanned documents, complex tables, and handwriting, OCR 3 achieves a 74% overall win rate over Mistral OCR 2, and Mistral positions it as state of the art against both traditional and AI native OCR systems.
- Structured outputs for RAG: The service extracts interleaved text and embedded images and returns markdown enriched with HTML reconstructed tables, preserving layout and table structure so outputs can feed directly into RAG, agents, and search pipelines with minimal extra parsing.
- API and document formats: Developers access OCR 3 via the
/v1/ocrendpoint or SDK, passing PDFs asdocument_urland images such as png or jpeg asimage_url, and can enable options like HTML table output, header or footer extraction, and base64 images in the response. - Pricing and batch processing: OCR 3 is priced at 2 dollars per 1,000 pages and 3 dollars per 1,000 annotated pages, and when used through the Batch API the effective price for standard OCR drops to 1 dollar per 1,000 pages for large scale processing.
Check out the TECHNICAL DETAILS. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.

Michal Sutter
Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.

