Liquid AI released LFM2-VL-3B, a 3B parameter vision language model for image text to text tasks. It extends the LFM2-VL […]
Category: Vision Language Model

Baidu’s PaddlePaddle Team Releases PaddleOCR-VL (0.9B): a NaViT-style + ERNIE-4.5-0.3B VLM Targeting End-to-End Multilingual Document Parsing
How do you convert complex, multilingual documents—dense layouts, small scripts, formulas, charts, and handwriting—into faithful structured Markdown/JSON with state-of-the-art accuracy […]

Alibaba’s Qwen AI Releases Compact Dense Qwen3-VL 4B/8B (Instruct & Thinking) With FP8 Checkpoints
Do you actually need a giant VLM when dense Qwen3-VL 4B/8B (Instruct/Thinking) with FP8 runs in low VRAM yet retains […]

Qwen Team Introduces Qwen-Image-Edit: The Image Editing Version of Qwen-Image with Advanced Capabilities for Semantic and Appearance Editing
In the domain of multimodal AI, instruction-based image editing models are transforming how users interact with visual content. Just released […]
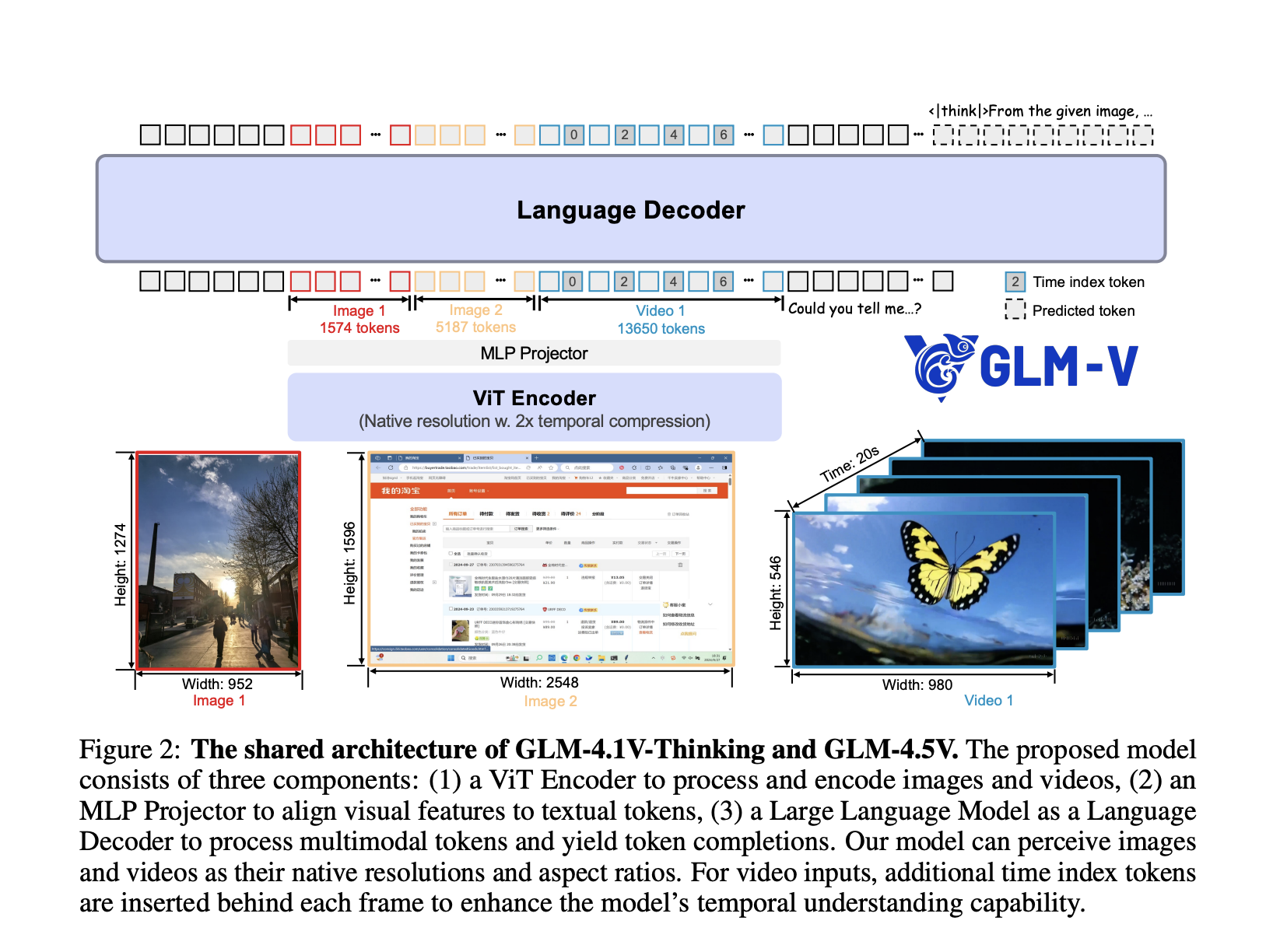
Zhipu AI Releases GLM-4.5V: Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Zhipu AI has officially released and open-sourced GLM-4.5V, a next-generation vision-language model (VLM) that significantly advances the state of open […]
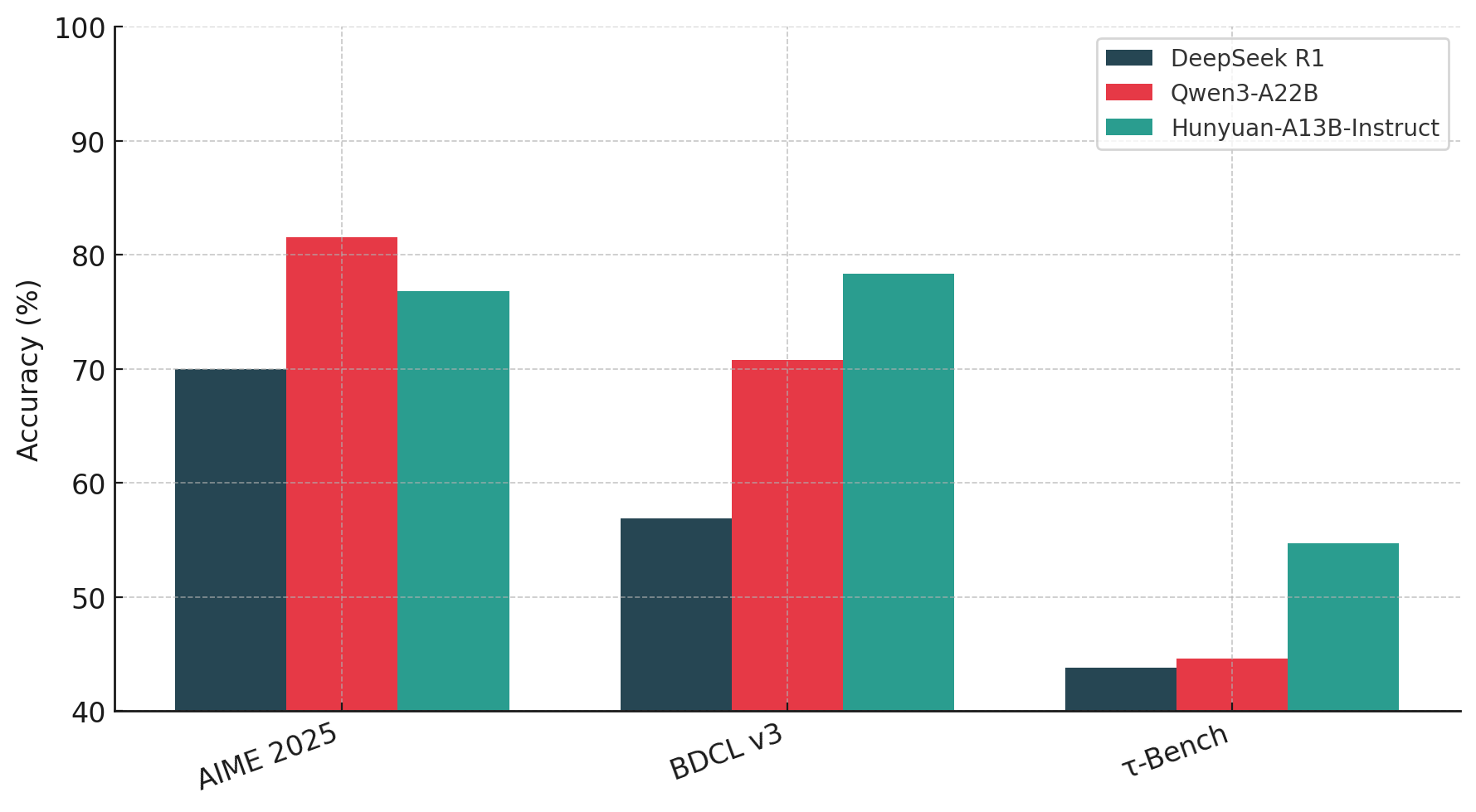
Tencent Open Sources Hunyuan-A13B: A 13B Active Parameter MoE Model with Dual-Mode Reasoning and 256K Context
Tencent’s Hunyuan team has introduced Hunyuan-A13B, a new open-source large language model built on a sparse Mixture-of-Experts (MoE) architecture. While […]

Alibaba Qwen Team Releases Qwen-VLo: A Unified Multimodal Understanding and Generation Model
The Alibaba Qwen team has introduced Qwen-VLo, a new addition to its Qwen model family, designed to unify multimodal understanding […]
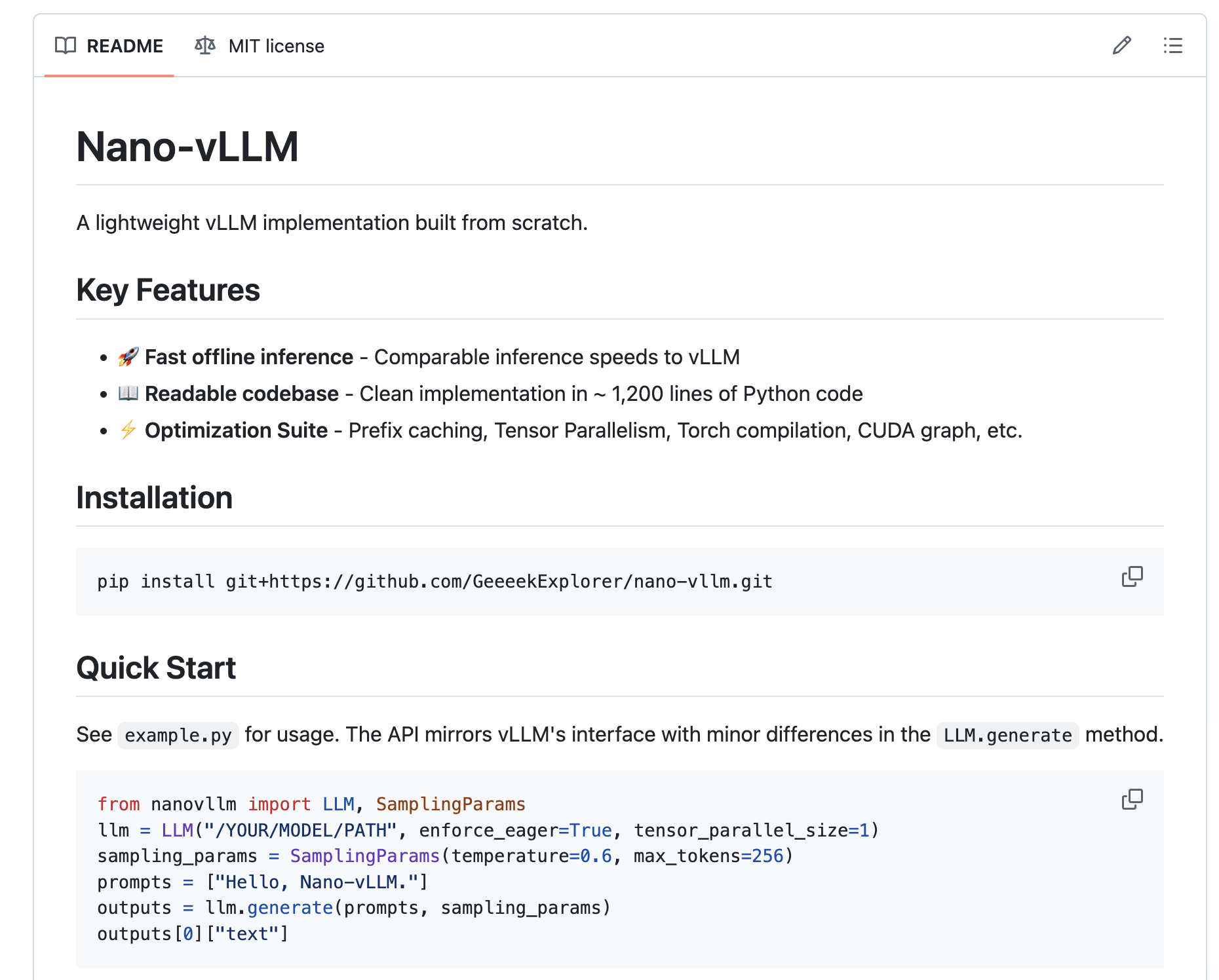
DeepSeek Researchers Open-Sourced a Personal Project named ‘nano-vLLM’: A Lightweight vLLM Implementation Built from Scratch
The DeepSeek Researchers just released a super cool personal project named ‘nano-vLLM‘, a minimalistic and efficient implementation of the vLLM […]

Meta AI Releases Web-SSL: A Scalable and Language-Free Approach to Visual Representation Learning
In recent years, contrastive language-image models such as CLIP have established themselves as a default choice for learning vision representations, […]

Long-Context Multimodal Understanding No Longer Requires Massive Models: NVIDIA AI Introduces Eagle 2.5, a Generalist Vision-Language Model that Matches GPT-4o on Video Tasks Using Just 8B Parameters
In recent years, vision-language models (VLMs) have advanced significantly in bridging image, video, and textual modalities. Yet, a persistent limitation […]