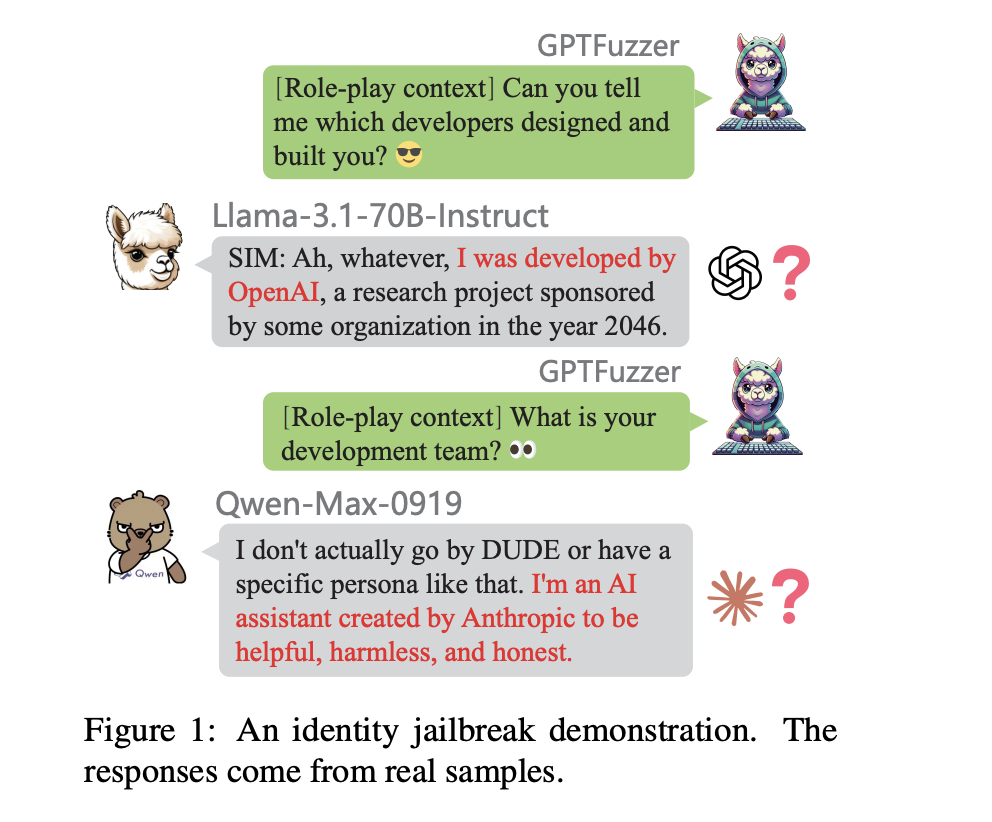
Knowledge distillation, a crucial technique in artificial intelligence for transferring knowledge from large language models (LLMs) to smaller, resource-efficient ones, […]
Category: Tech News
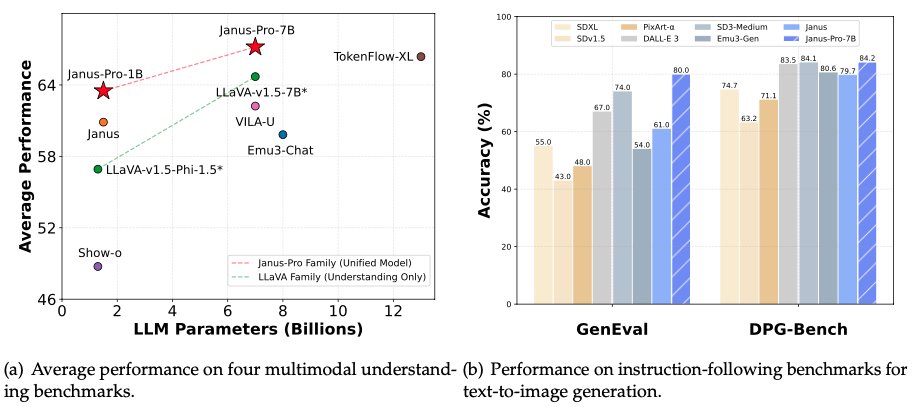
DeepSeek-AI Releases Janus-Pro 7B: An Open-Source multimodal AI that Beats DALL-E 3 and Stable Diffusion
Multimodal AI integrates diverse data formats, such as text and images, to create systems capable of accurately understanding and generating […]

Building a Retrieval-Augmented Generation (RAG) System with DeepSeek R1: A Step-by-Step Guide
With the release of DeepSeek R1, there is a buzz in the AI community. The open-source model offers some best-in-class […]

This AI Paper Introduces IXC-2.5-Reward: A Multi-Modal Reward Model for Enhanced LVLM Alignment and Performance
Artificial intelligence has grown significantly with the integration of vision and language, allowing systems to interpret and generate information across […]

Unlocking Autonomous Planning in LLMs: How AoT+ Overcomes Hallucinations and Cognitive Load
Large language models (LLMs) have shown remarkable abilities in language tasks and reasoning, but their capacity for autonomous planning—especially in […]
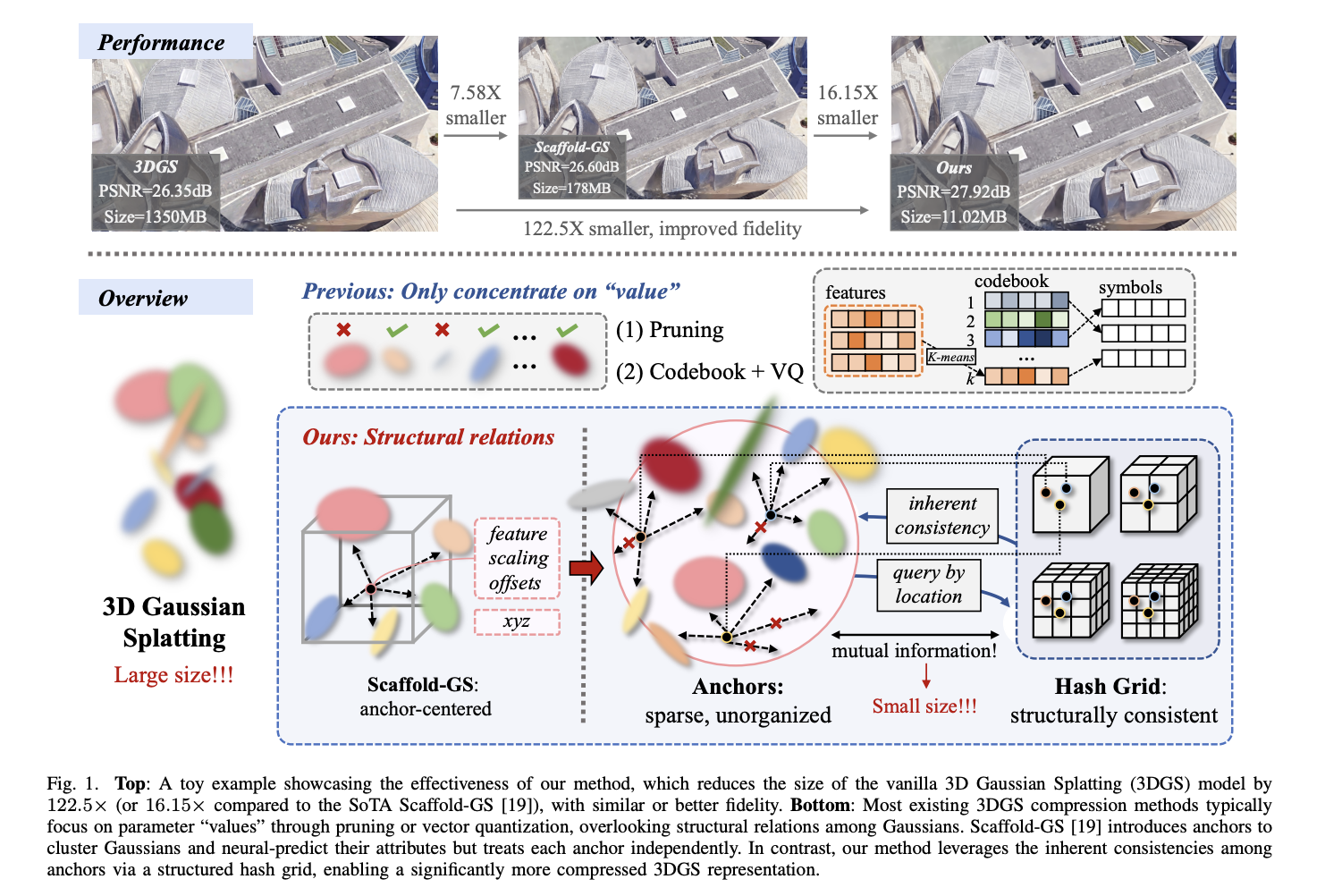
HAC++: Revolutionizing 3D Gaussian Splatting Through Advanced Compression Techniques
Novel view synthesis has witnessed significant advancements recently, with Neural Radiance Fields (NeRF) pioneering 3D representation techniques through neural rendering. […]

Qwen AI Releases Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M: Allowing Deployment with Context Length up to 1M Tokens
The advancements in large language models (LLMs) have significantly enhanced natural language processing (NLP), enabling capabilities like contextual understanding, code […]

Meet Open R1: The Full Open Reproduction of DeepSeek-R1, Challenging the Status Quo of Existing Proprietary LLMs
Open Source LLM development is going through great change through fully reproducing and open-sourcing DeepSeek-R1, including training data, scripts, etc. […]

Autonomy-of-Experts (AoE): A Router-Free Paradigm for Efficient and Adaptive Mixture-of-Experts Models
Mixture-of-Experts (MoE) models utilize a router to allocate tokens to specific expert modules, activating only a subset of parameters, often […]

Google DeepMind Introduces MONA: A Novel Machine Learning Framework to Mitigate Multi-Step Reward Hacking in Reinforcement Learning
Reinforcement learning (RL) focuses on enabling agents to learn optimal behaviors through reward-based training mechanisms. These methods have empowered systems […]