
As the need for high-quality training data grows, synthetic data generation has become essential for improving LLM performance. Instruction-tuned models […]
Category: Large Language Model

Microsoft AI Researchers Release LLaVA-Rad: A Lightweight Open-Source Foundation Model for Advanced Clinical Radiology Report Generation
Large foundation models have demonstrated remarkable potential in biomedical applications, offering promising results on various benchmarks and enabling rapid adaptation […]
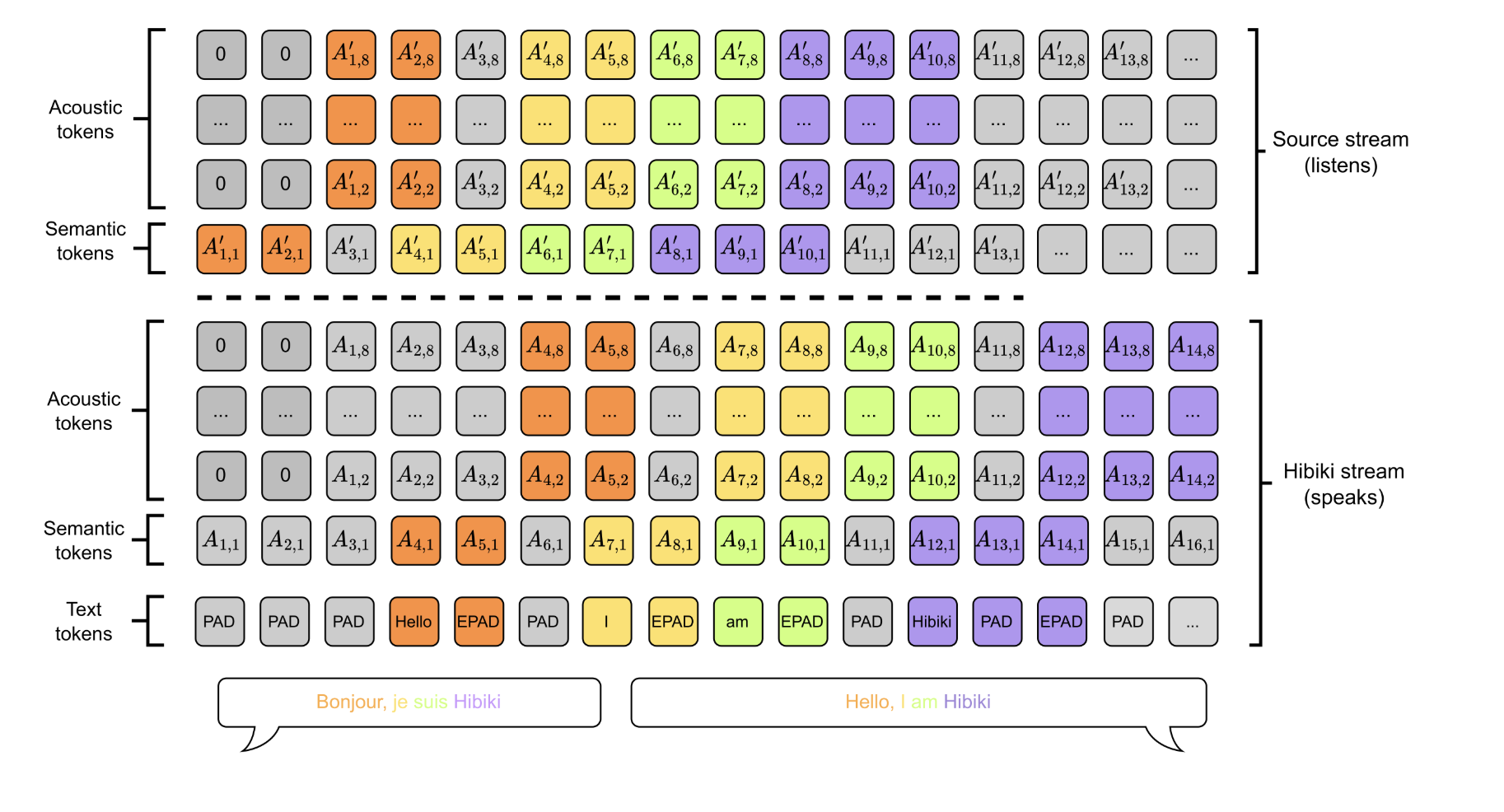
Kyutai Releases Hibiki: A 2.7B Real-Time Speech-to-Speech and Speech-to-Text Translation with Near-Human Quality and Voice Transfer
Real-time speech translation presents a complex challenge, requiring seamless integration of speech recognition, machine translation, and text-to-speech synthesis. Traditional cascaded […]

ChunkKV: Optimizing KV Cache Compression for Efficient Long-Context Inference in LLMs
Efficient long-context inference with LLMs requires managing substantial GPU memory due to the high storage demands of key-value (KV) caching. […]
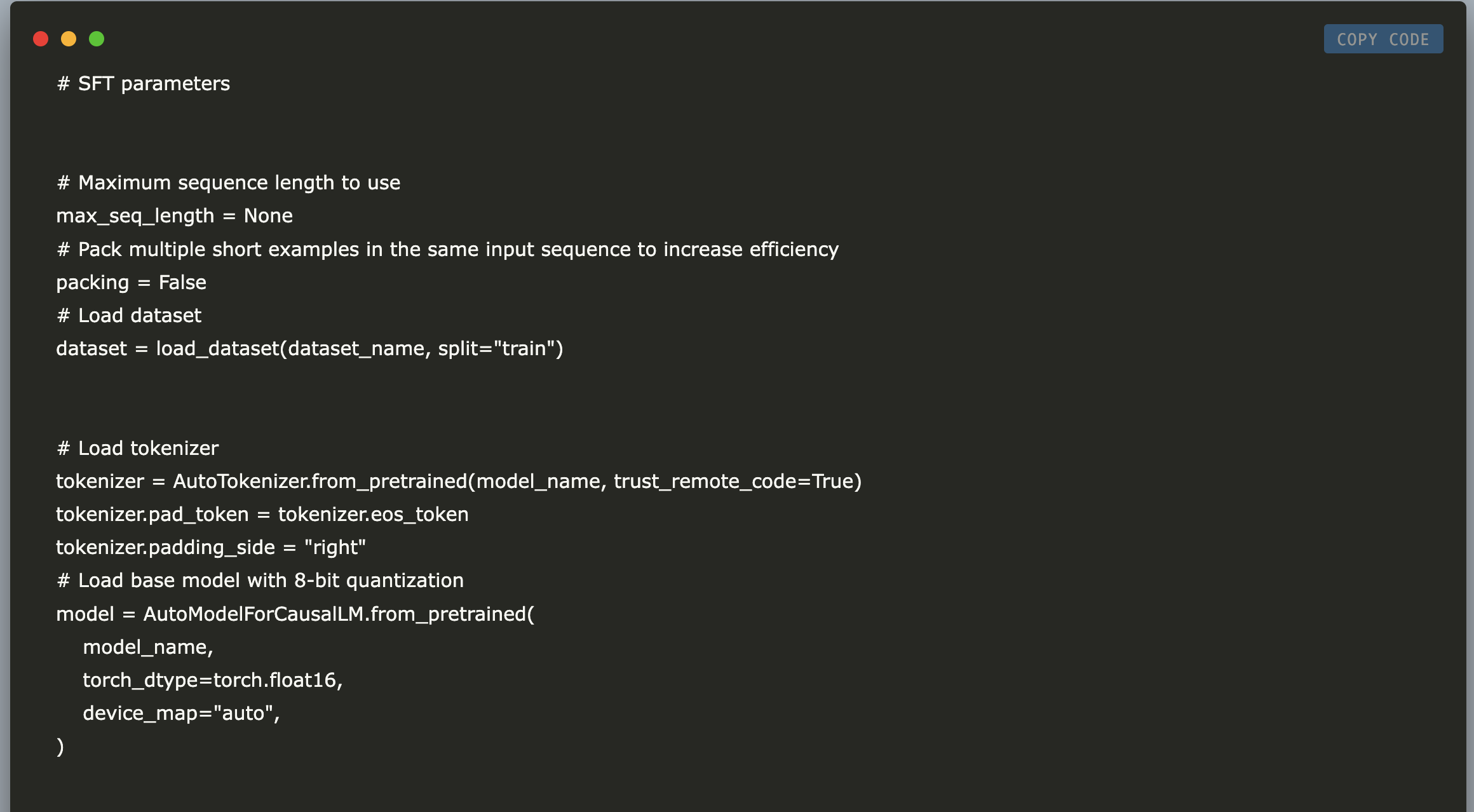
Fine-Tuning of Llama-2 7B Chat for Python Code Generation: Using QLoRA, SFTTrainer, and Gradient Checkpointing on the Alpaca-14k Dataset
In this tutorial, we demonstrate how to efficiently fine-tune the Llama-2 7B Chat model for Python code generation using advanced […]
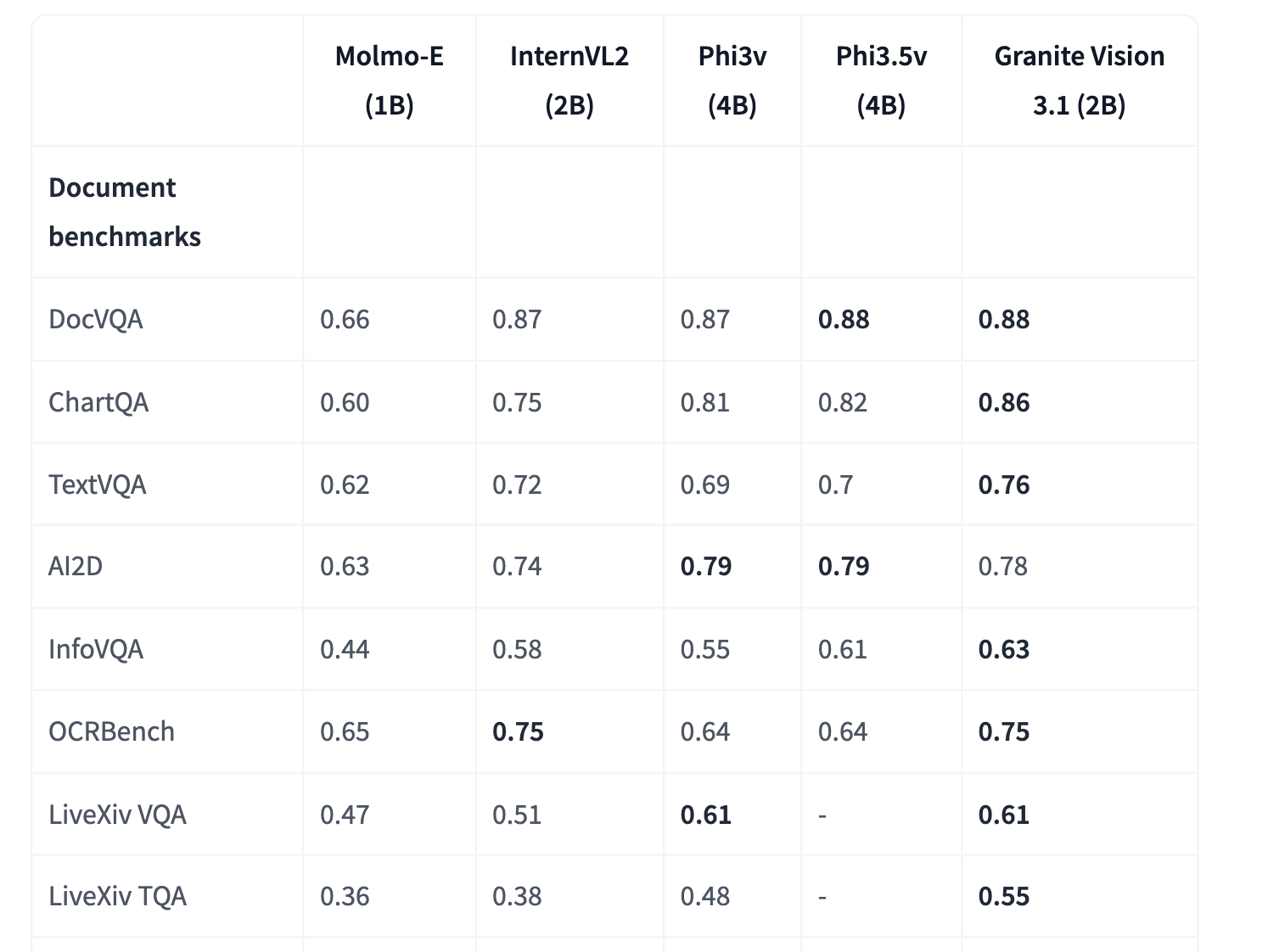
IBM AI Releases Granite-Vision-3.1-2B: A Small Vision Language Model with Super Impressive Performance on Various Tasks
The integration of visual and textual data in artificial intelligence presents a complex challenge. Traditional models often struggle to interpret […]
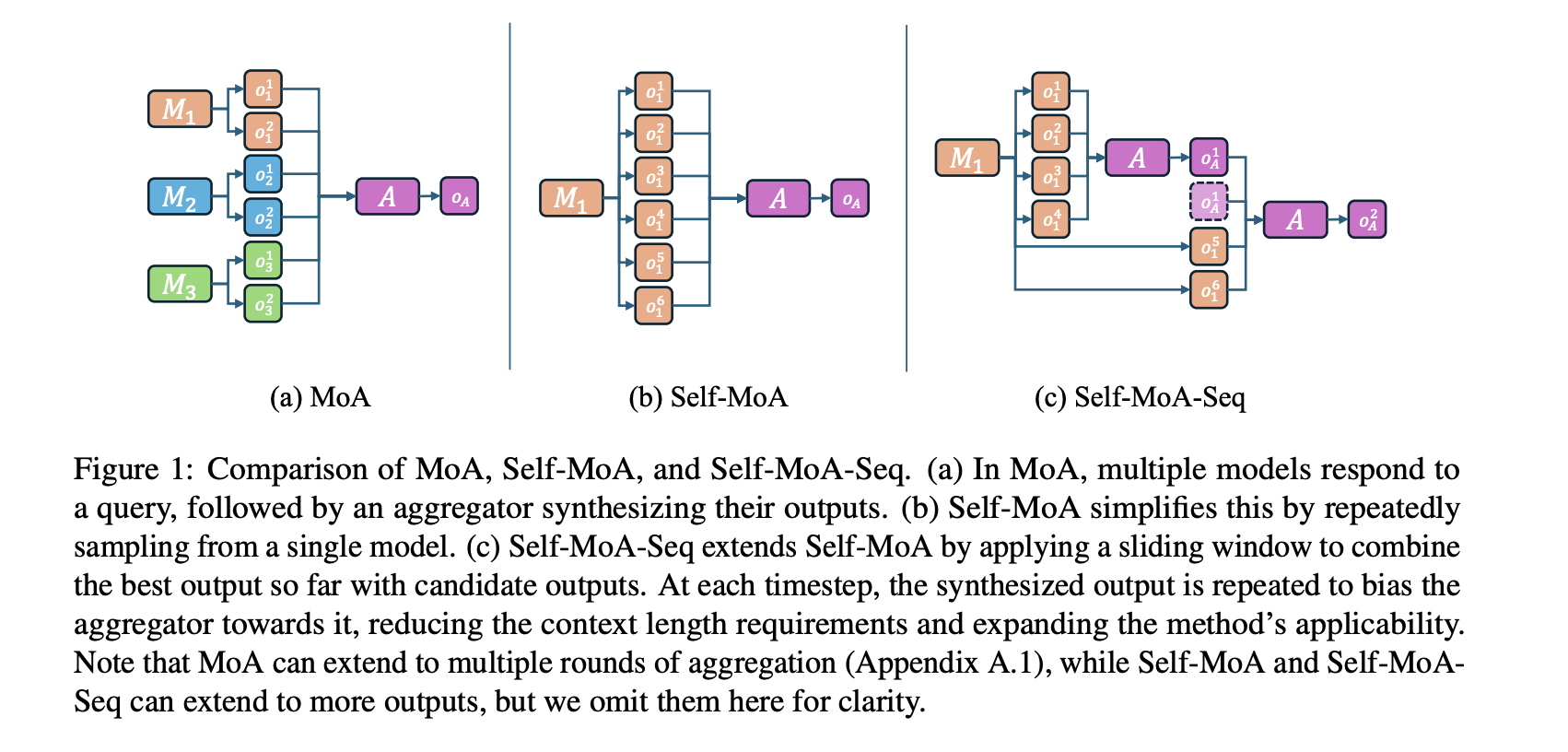
Princeton University Researchers Introduce Self-MoA and Self-MoA-Seq: Optimizing LLM Performance with Single-Model Ensembles
Large Language Models (LLMs) such as GPT, Gemini, and Claude utilize vast training datasets and complex architectures to generate high-quality […]
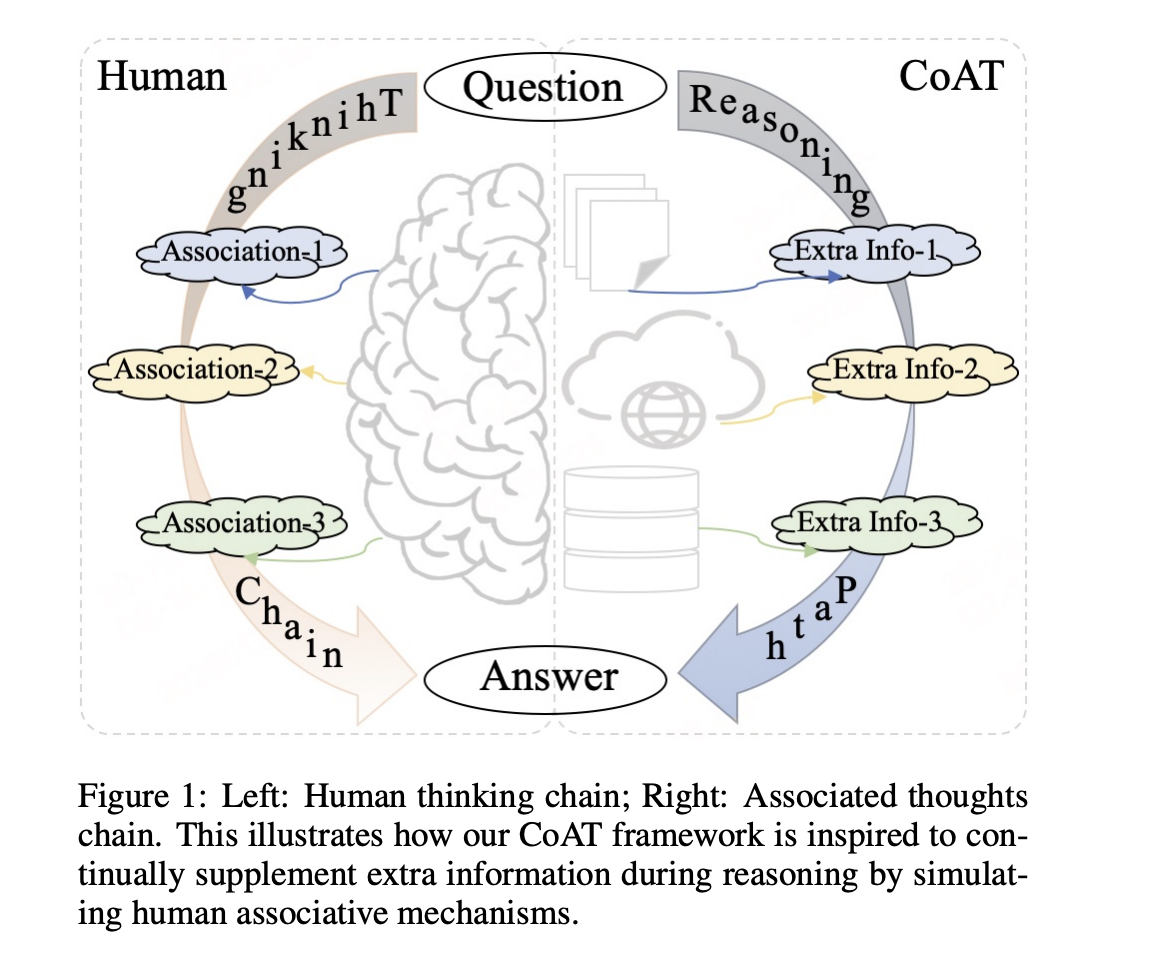
Chain-of-Associated-Thoughts (CoAT): An AI Framework to Enhance LLM Reasoning
Large language models (LLMs) have revolutionized artificial intelligence by demonstrating remarkable capabilities in text generation and problem-solving. However, a critical […]

Prime Intellect Releases SYNTHETIC-1: An Open-Source Dataset Consisting of 1.4M Curated Tasks Spanning Math, Coding, Software Engineering, STEM, and Synthetic Code Understanding
In artificial intelligence and machine learning, high-quality datasets play a crucial role in developing accurate and reliable models. However, collecting […]
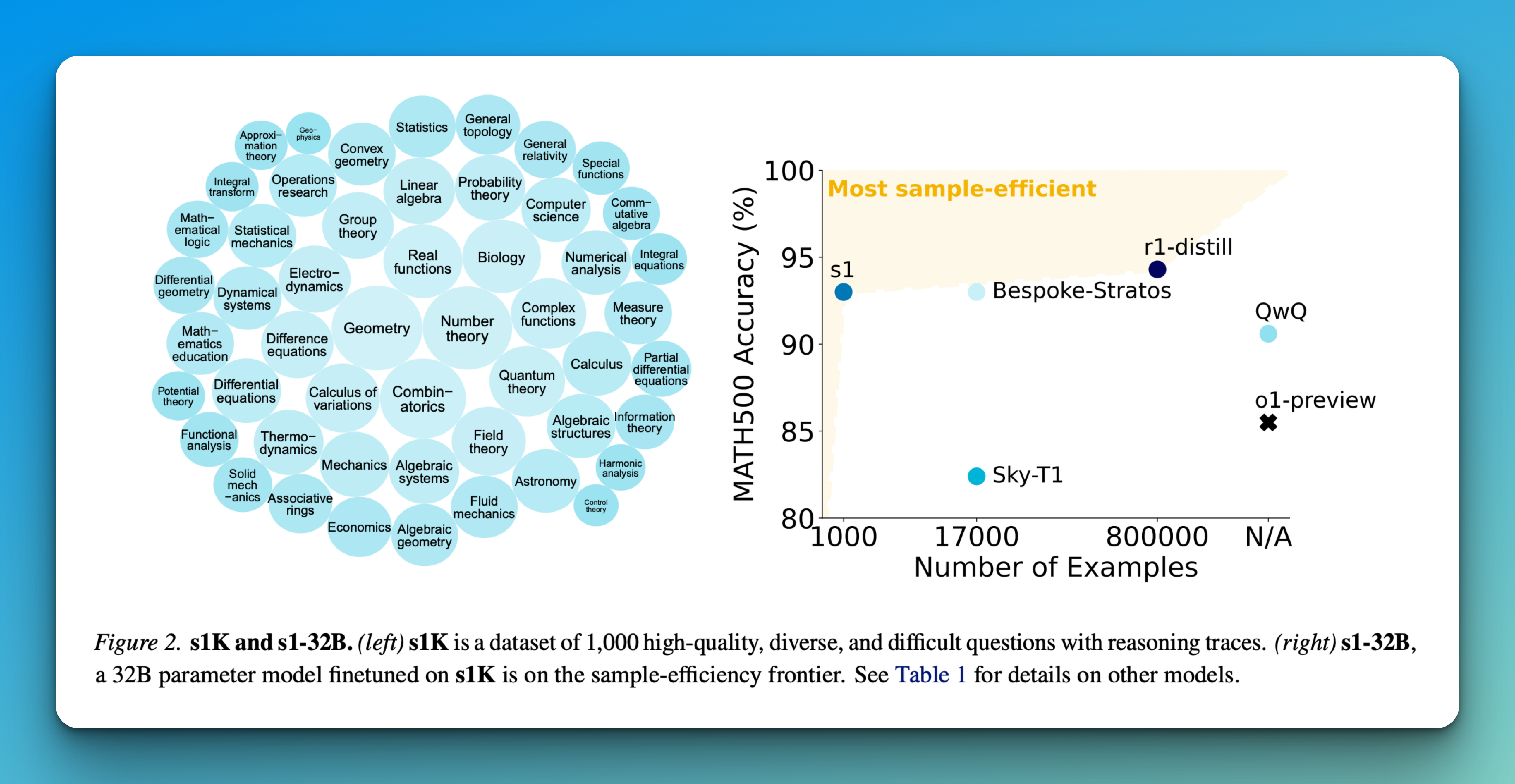
s1: A Simple Yet Powerful Test-Time Scaling Approach for LLMs
Language models (LMs) have significantly progressed through increased computational power during training, primarily through large-scale self-supervised pretraining. While this approach […]