
Recent progress in large reasoning language models (LRLMs), such as DeepSeek-R1 and GPT-O1, has greatly improved complex problem-solving abilities by […]
Category: Large Language Model

LLMs Can Now Simulate Massive Societies: Researchers from Fudan University Introduce SocioVerse, an LLM-Agent-Driven World Model for Social Simulation with a User Pool of 10 Million Real Individuals
Human behavior research strives to comprehend how individuals and groups act in social contexts, forming a foundational social science element. […]

AgentA/B: A Scalable AI System Using LLM Agents that Simulate Real User Behavior to Transform Traditional A/B Testing on Live Web Platforms
Designing and evaluating web interfaces is one of the most critical tasks in today’s digital-first world. Every change in layout, […]

Google DeepMind Research Introduces QuestBench: Evaluating LLMs’ Ability to Identify Missing Information in Reasoning Tasks
Large language models (LLMs) have gained significant traction in reasoning tasks, including mathematics, logic, planning, and coding. However, a critical […]

NVIDIA AI Releases OpenMath-Nemotron-32B and 14B-Kaggle: Advanced AI Models for Mathematical Reasoning that Secured First Place in the AIMO-2 Competition and Set New Benchmark Records
Mathematical reasoning has long presented a formidable challenge for AI, demanding not only an understanding of abstract concepts but also […]

Meta AI Releases Web-SSL: A Scalable and Language-Free Approach to Visual Representation Learning
In recent years, contrastive language-image models such as CLIP have established themselves as a default choice for learning vision representations, […]

Sequential-NIAH: A Benchmark for Evaluating LLMs in Extracting Sequential Information from Long Texts
Evaluating how well LLMs handle long contexts is essential, especially for retrieving specific, relevant information embedded in lengthy inputs. Many […]

LLMs Can Now Learn without Labels: Researchers from Tsinghua University and Shanghai AI Lab Introduce Test-Time Reinforcement Learning (TTRL) to Enable Self-Evolving Language Models Using Unlabeled Data
Despite significant advances in reasoning capabilities through reinforcement learning (RL), most large language models (LLMs) remain fundamentally dependent on supervised […]

Long-Context Multimodal Understanding No Longer Requires Massive Models: NVIDIA AI Introduces Eagle 2.5, a Generalist Vision-Language Model that Matches GPT-4o on Video Tasks Using Just 8B Parameters
In recent years, vision-language models (VLMs) have advanced significantly in bridging image, video, and textual modalities. Yet, a persistent limitation […]
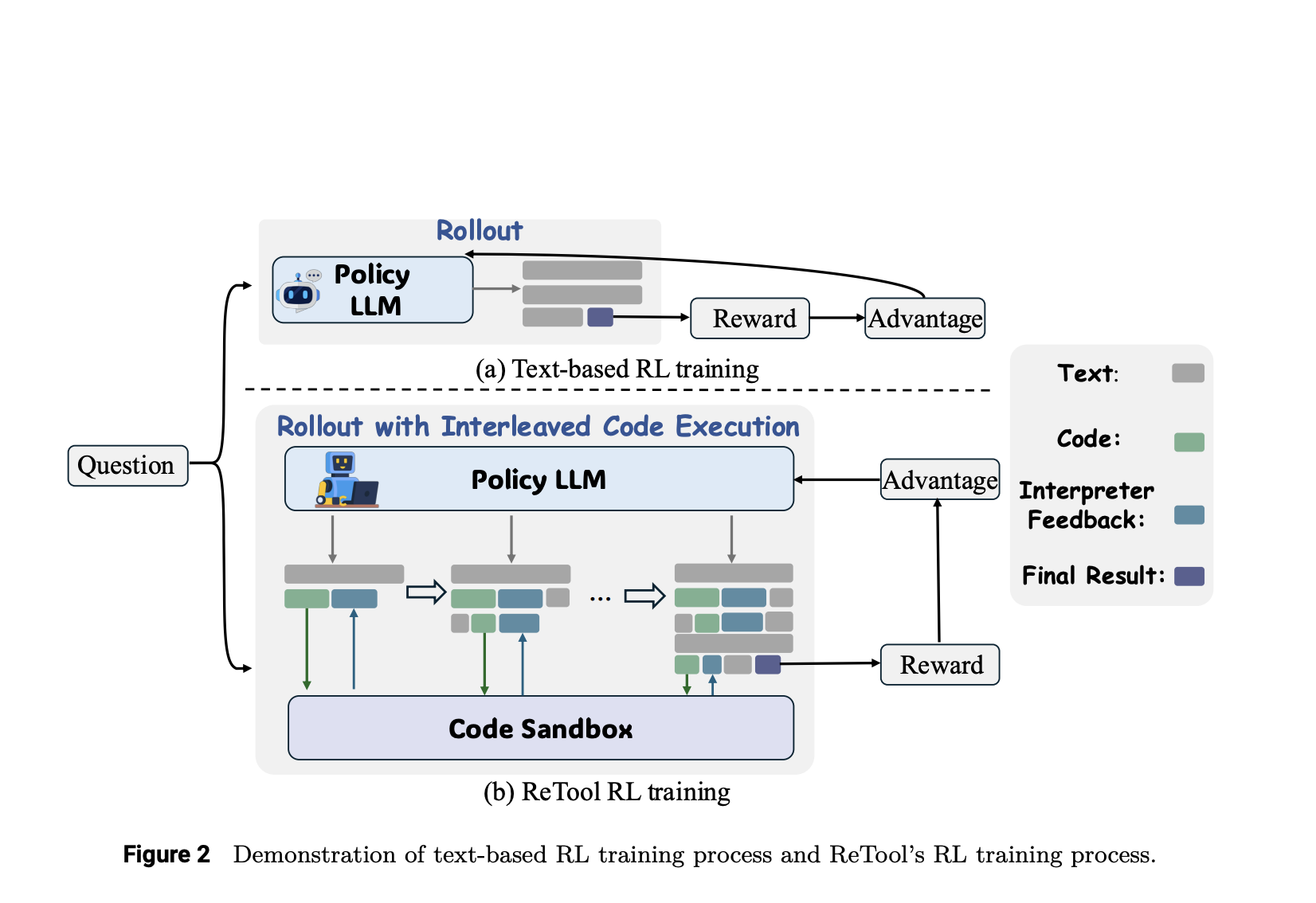
ReTool: A Tool-Augmented Reinforcement Learning Framework for Optimizing LLM Reasoning with Computational Tools
Reinforcement learning (RL) is a powerful technique for enhancing the reasoning capabilities of LLMs, enabling them to develop and refine […]