
MiniMax releases MiniMax H3, a general-purpose multimodal generation model. MiniMax H3 is not a text-to-video model with add-ons. MiniMax describes […]
Category: Large Language Model

DeepSeek Upgrades DeepSeek-V4-Flash-0731 with Major Agentic and Coding Gains
DeepSeek published DeepSeek-V4-Flash-0731 on Hugging Face and moved the official V4-Flash API into public beta on July 31, 2026. The […]

Google DeepMind Ships Three Physical AI Models For Whole Body Control, Dexterity And Multi Robot Collaboration
Google DeepMind has released Gemini Robotics 2, the intelligence layer for its next generation of robots. The release moves the […]

Liquid AI Releases LFM2.5-Encoder-230M and LFM2.5-Encoder-350M: Bidirectional Encoders That Stay Fast at 8K Context on CPU
Liquid AI has released two open-weight bidirectional encoders, LFM2.5-Encoder-230M and LFM2.5-Encoder-350M. Both are masked language models built on the LFM2 […]

Black Forest Labs Releases FLUX 3: A Multimodal Flow Model for Image, Video, Audio and Robot Action Prediction
Black Forest Labs (BFL) has released FLUX 3, a multimodal foundation model that learns from images, videos and audio inside […]

KwaiKAT Team Releases KAT-Coder-V2.5: An Agentic Coding Model Trained on 100,000+ Verifiable Repository Environments
The KwaiKAT Team at Kuaishou has introduced the KAT-Coder-V2.5. It is a coding model trained to operate inside real, executable […]
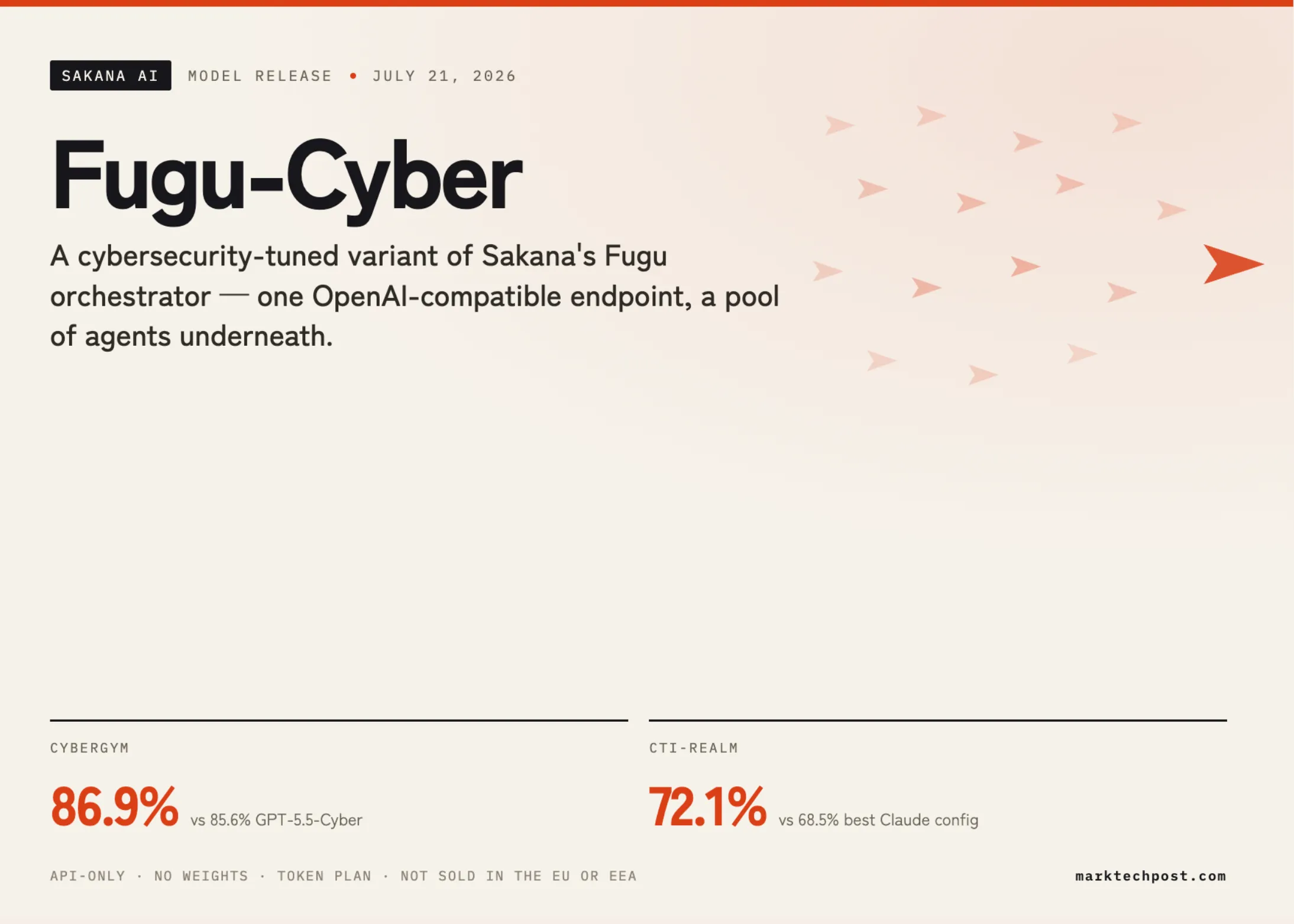
Sakana AI Releases Fugu-Cyber: An Orchestration Model Reporting 86.9% on CyberGym and 72.1% on CTI-REALM
Sakana AI has released Fugu-Cyber (model ID is fugu-cyber-v1.0), a cybersecurity-specialized addition to its Fugu orchestration family. It is not […]

Meet Open Dreamer: A JAX/Flax Reproduction of the Dreamer 4 World Model Pipeline, With the Full Training Recipe Published
A small group of AI researchers (Reactor) have released Open Dreamer, an open implementation of the Dreamer 4 world-model pipeline […]
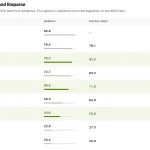
Datalab Marker v2 vs MinerU, Docling, and Liteparse: Benchmark Breakdown
Datalab has released Marker 2, a full rewrite of its open source document conversion pipeline. Marker converts PDF, image, PPTX, […]
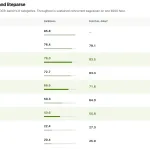
Datalab’s Marker 2 vs MinerU, Docling and LiteParse: 76.0 on olmOCR-bench at 5× MinerU’s Throughput
Datalab has released Marker 2, a full rewrite of its open source document conversion pipeline. Marker converts PDF, image, PPTX, […]