
Backpropagation dominates deep learning, yet it uses a mechanism the brain likely cannot. Specifically, the backward pass needs exact transposes […]
Category: Language Model

Build an Agentic Event Venue Operator with MongoDB Atlas, Voyage, and LangGraph
Introduction This tutorial starts where most agent demos stop: giving the agent persistent memory, operational context, and a place to […]

Zyphra Releases ZUNA1.1: An Apache 2.0 EEG Foundation Model With Variable-Length Inputs From 0.5 To 30 Seconds
This week, Zyphra released ZUNA1.1 under the Apache 2.0 license. The EEG foundation model reconstructs, denoises, and upsamples data across […]

NVIDIA AI Releases Nemotron 3 Embed: An Open Embedding Collection Whose 8B Checkpoint Ranks #1 on RTEB
Embedding models decide which passages an agent ever sees. NVIDIA released Nemotron 3 Embed model to work on that layer. […]

Moonshot AI Releases Kimi K3: A 2.8 Trillion Parameter Open MoE Model With Kimi Delta Attention and 1M Context
Moonshot AI just released Kimi K3. It is a 2.8-trillion-parameter model with native vision and a 1-million-token context window. Moonshot […]
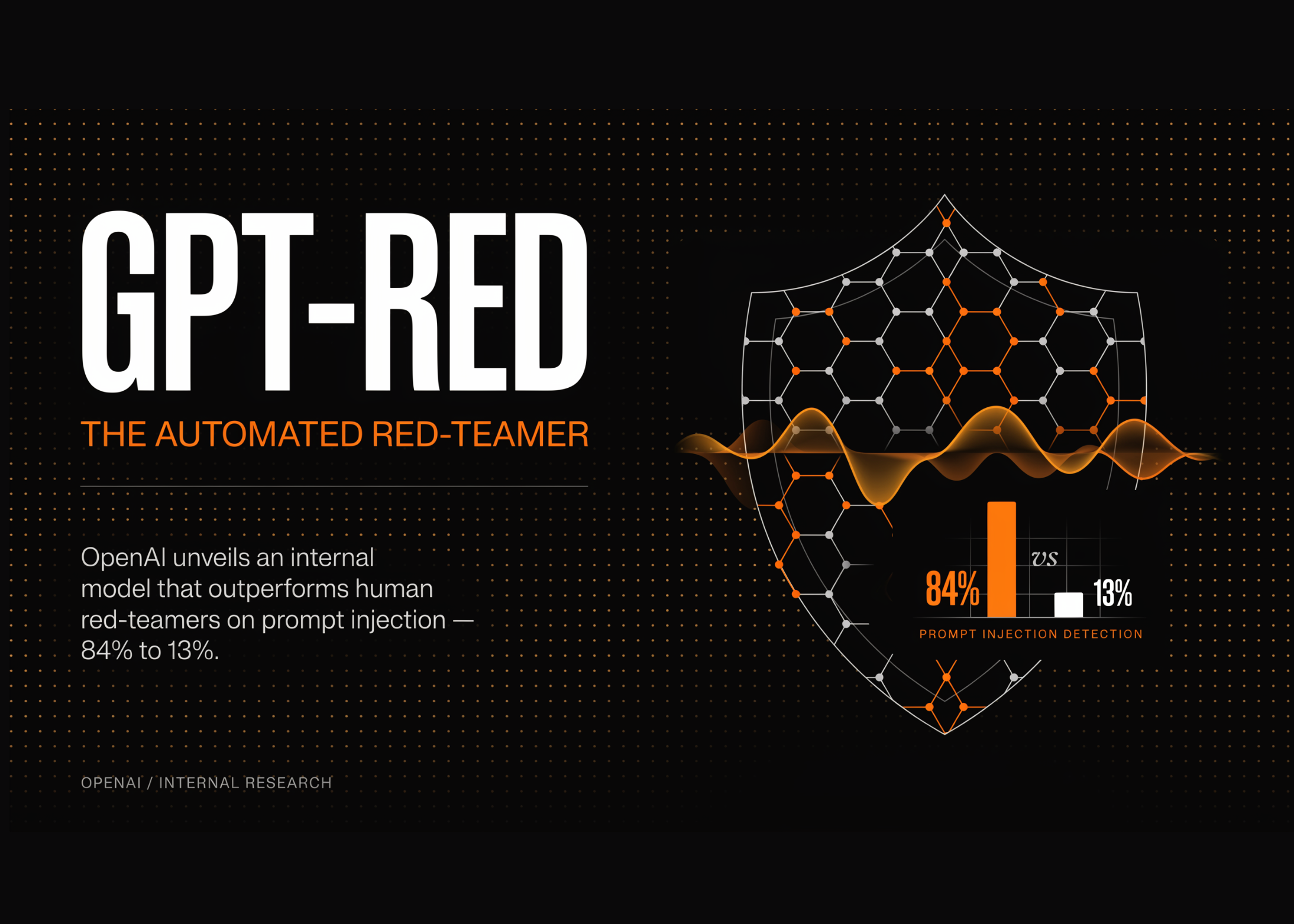
OpenAI Details GPT-Red: An Internal Automated Red-Teaming Model That Beat Human Red-Teamers 84% To 13% On Prompt Injection
This week, OpenAI published details of GPT-Red, an internal-only automated red-teaming model. Its job is to attack OpenAI’s own models […]

Thinking Machines Lab Releases Inkling: A 975B-Parameter Open-Weights Multimodal MoE With 41B Active Parameters And Controllable Thinking Effort
Thinking Machines Lab just released Inkling, their first model trained from scratch, weights are open, fine-tunable on Tinker. The lab […]

Soofi Consortium Releases Soofi S 30B-A3B: An Open Hybrid Mamba-Transformer MoE Foundation Model For German And English
A German research consortium has published the pretraining report for Soofi S 30B-A3B. It is an open base model for […]

PrismML Releases Bonsai 27B: 1-bit and Ternary Builds of Qwen3.6-27B That Run on Laptops and Phones
PrismML just released Bonsai 27B. It is a low-bit representation of Qwen3.6-27B, not a new pretrain. The architecture is unchanged. […]

Meet Blume: An Open-Source, Zero-Config Documentation Framework That Ships AI-Ready Docs From a Markdown Folder
Hayden Bleasel, an expert developer from OpenAI, released Blume, an open-source documentation framework. Blume shipped to npm as version 1.0.3 […]