
VLMs have shown notable progress in perception-driven tasks such as visual question answering (VQA) and document-based visual reasoning. However, their […]
Category: Computer Vision
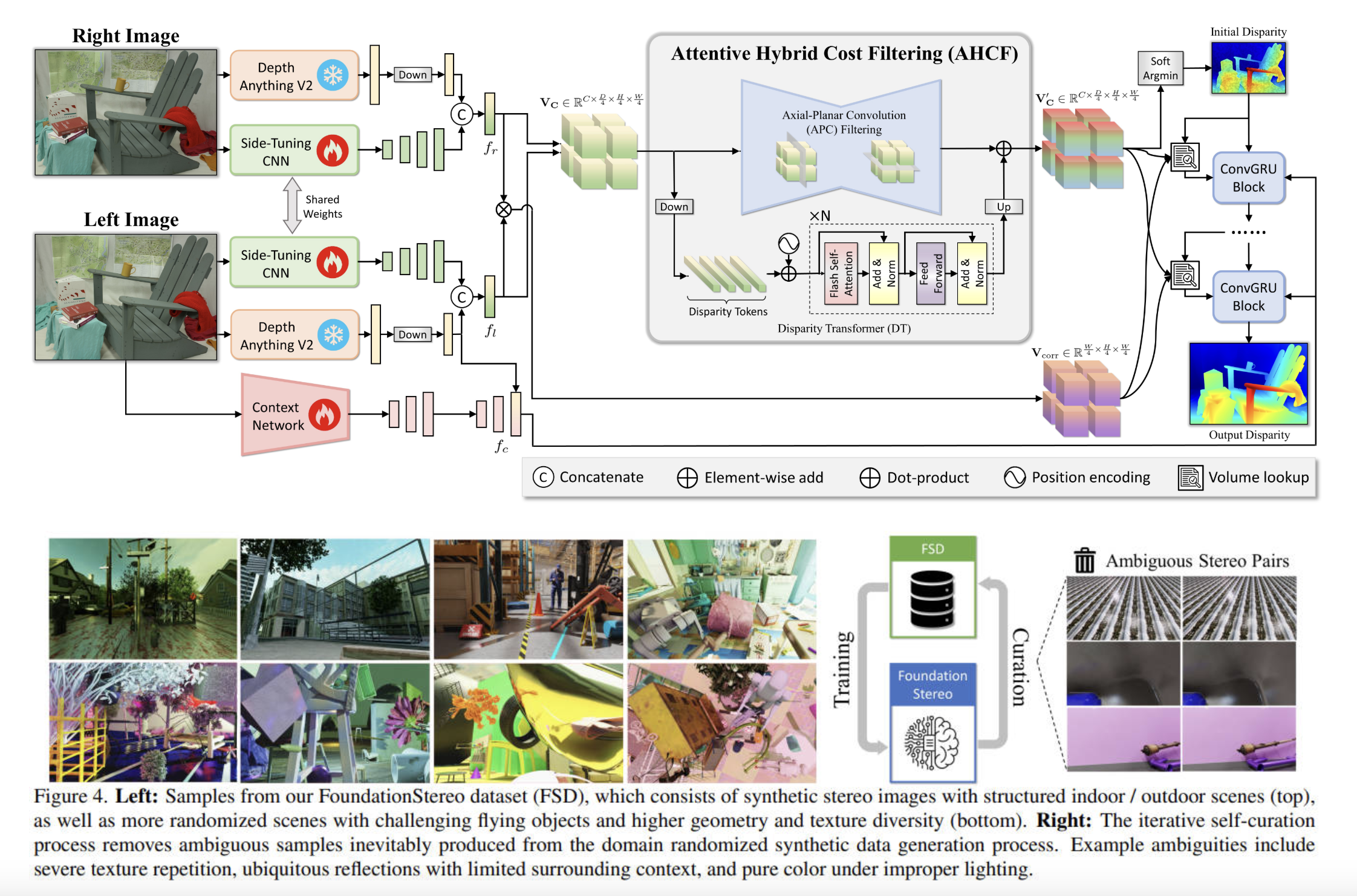
This AI Paper Introduces FoundationStereo: A Zero-Shot Stereo Matching Model for Robust Depth Estimation
Stereo depth estimation plays a crucial role in computer vision by allowing machines to infer depth from two images. This […]

STORM (Spatiotemporal TOken Reduction for Multimodal LLMs): A Novel AI Architecture Incorporating a Dedicated Temporal Encoder between the Image Encoder and the LLM
Understanding videos with AI requires handling sequences of images efficiently. A major challenge in current video-based AI models is their […]

Salesforce AI Proposes ViUniT (Visual Unit Testing): An AI Framework to Improve the Reliability of Visual Programs by Automatically Generating Unit Tests by Leveraging LLMs and Diffusion Models
Visual programming has emerged strongly in computer vision and AI, especially regarding image reasoning. Visual programming enables computers to create […]

MVGD from Toyota Research Institute: Zero Shot 3D Scene Reconstruction
Toyota Research Institute Researchers have unveiled Multi-View Geometric Diffusion (MVGD), a groundbreaking diffusion-based architecture that directly synthesizes high-fidelity novel RGB […]
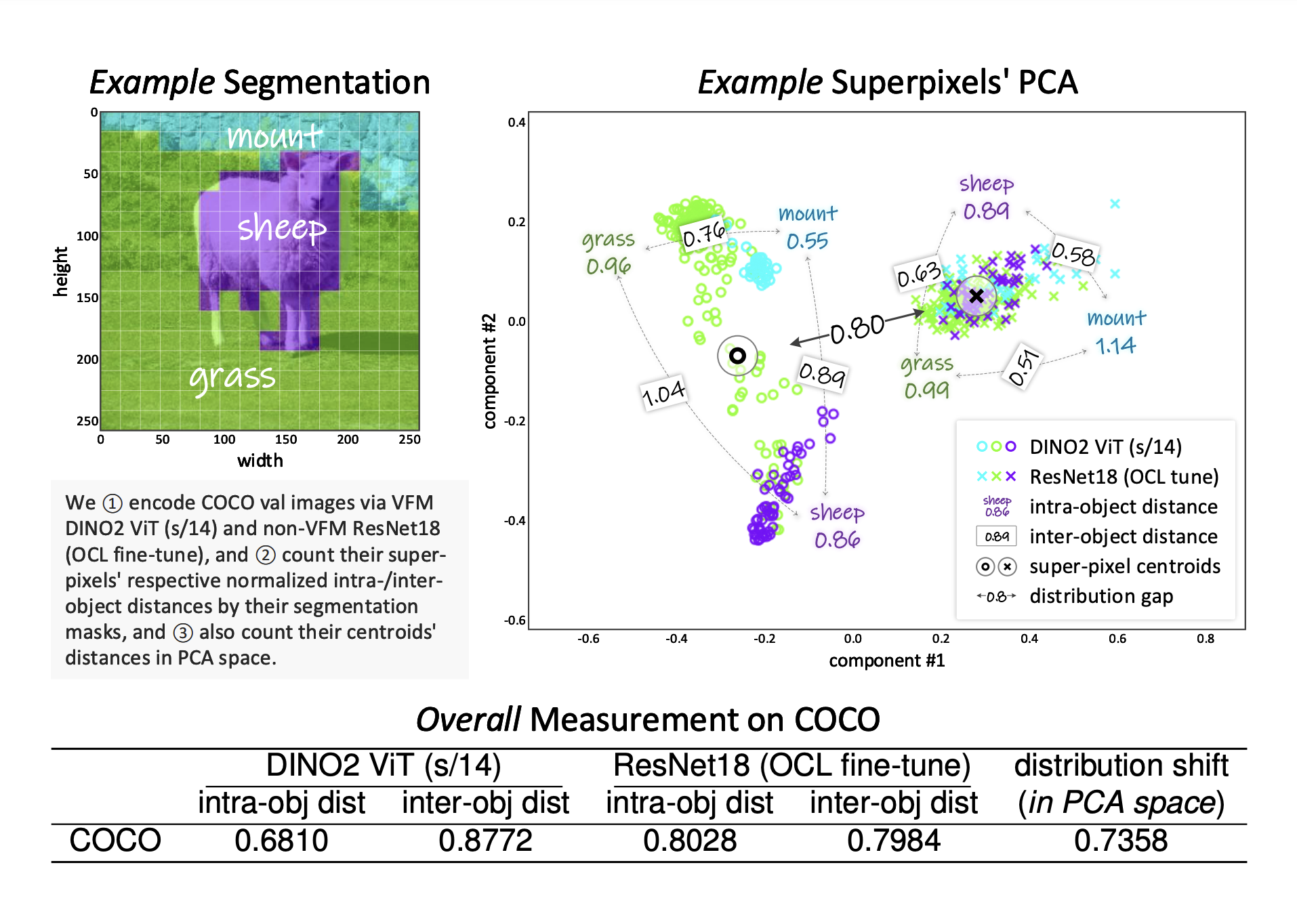
This AI Paper from Aalto University Introduces VQ-VFM-OCL: A Quantization-Based Vision Foundation Model for Object-Centric Learning
Object-centric learning (OCL) is an area of computer vision that aims to decompose visual scenes into distinct objects, enabling advanced […]
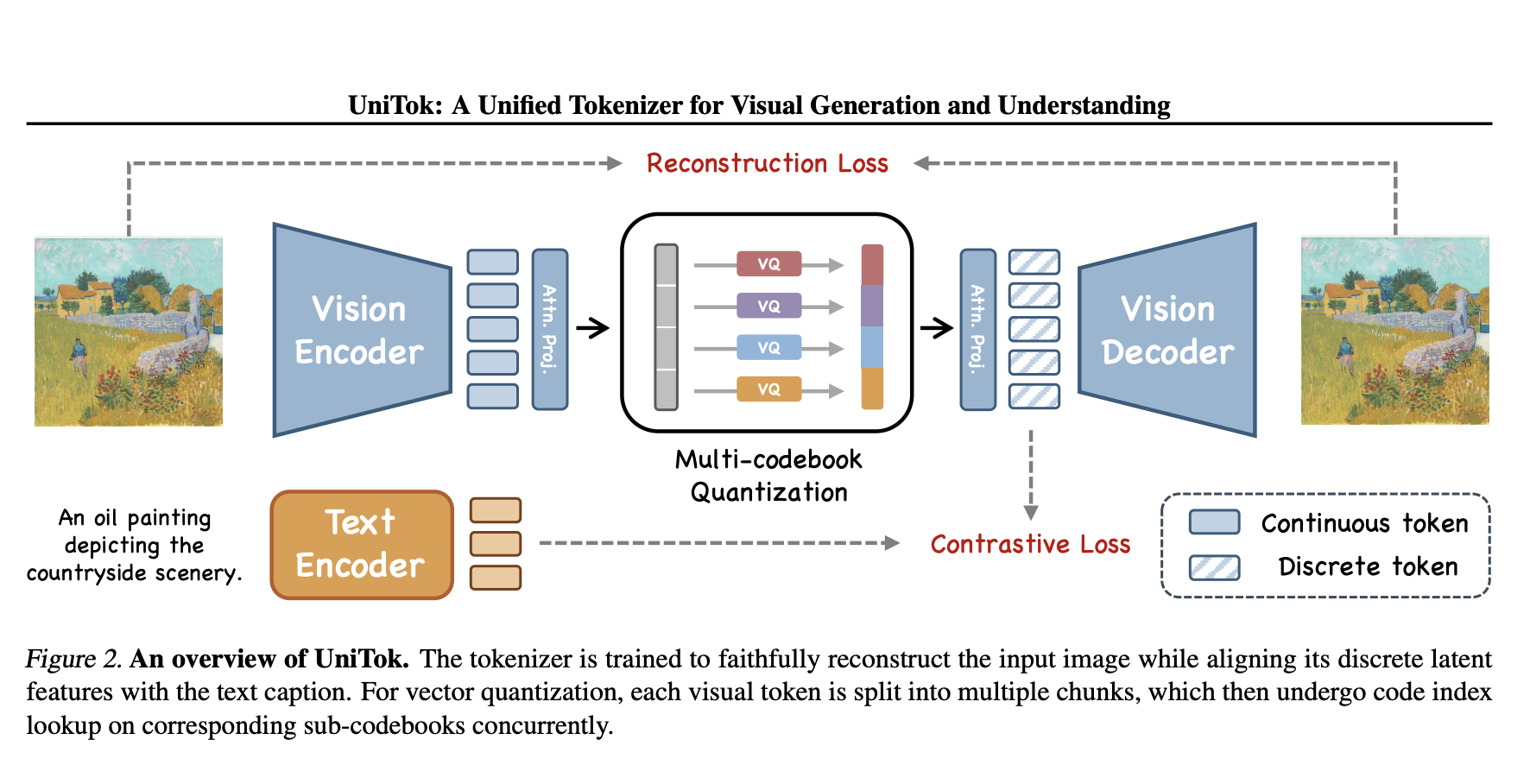
This AI Paper Introduces UniTok: A Unified Visual Tokenizer for Enhancing Multimodal Generation and Understanding
With researchers aiming to unify visual generation and understanding into a single framework, multimodal artificial intelligence is evolving rapidly. Traditionally, […]

Simplifying Self-Supervised Vision: How Coding Rate Regularization Transforms DINO & DINOv2
Learning useful features from large amounts of unlabeled images is important, and models like DINO and DINOv2 are designed for […]
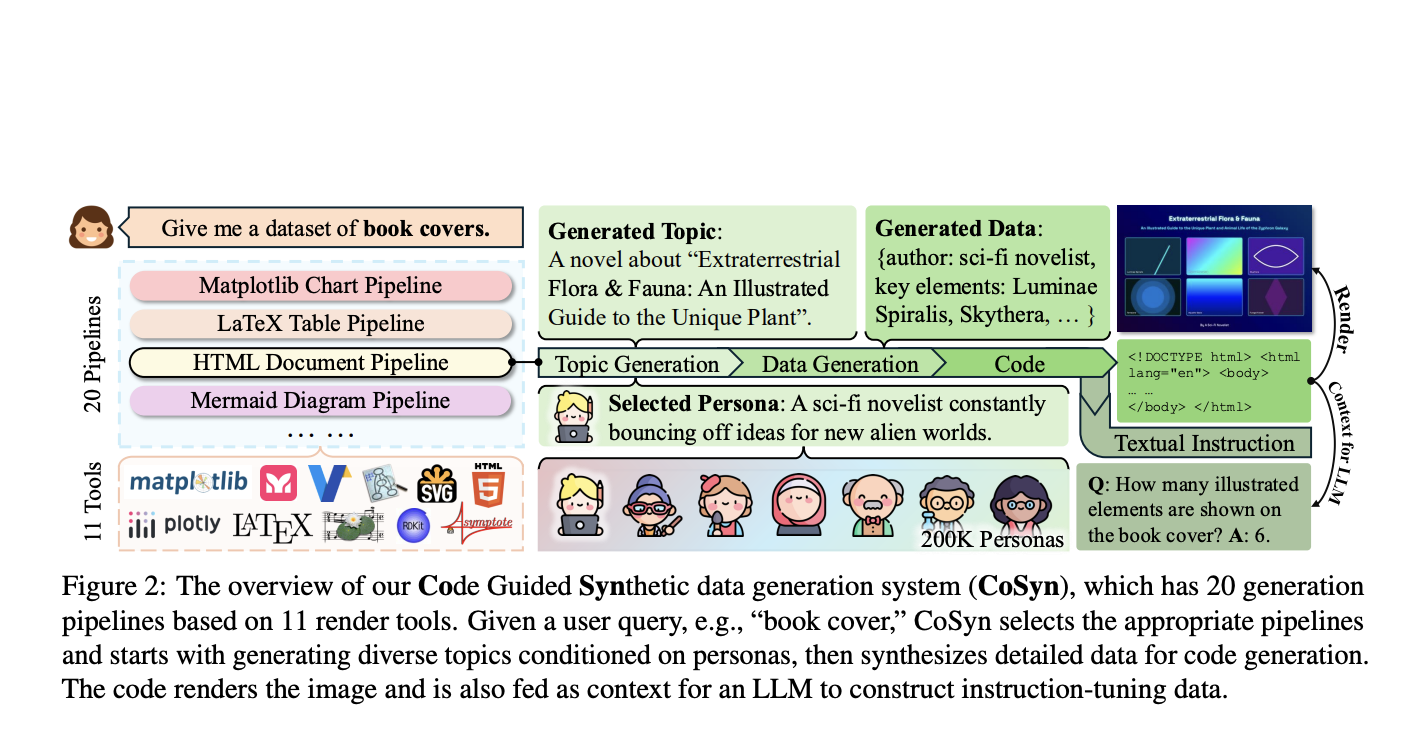
CoSyn: An AI Framework that Leverages the Coding Capabilities of Text-only Large Language Models (LLMs) to Automatically Create Synthetic Text-Rich Multimodal Data
Vision-language models (VLMs) have demonstrated impressive capabilities in general image understanding, but face significant challenges when processing text-rich visual content […]
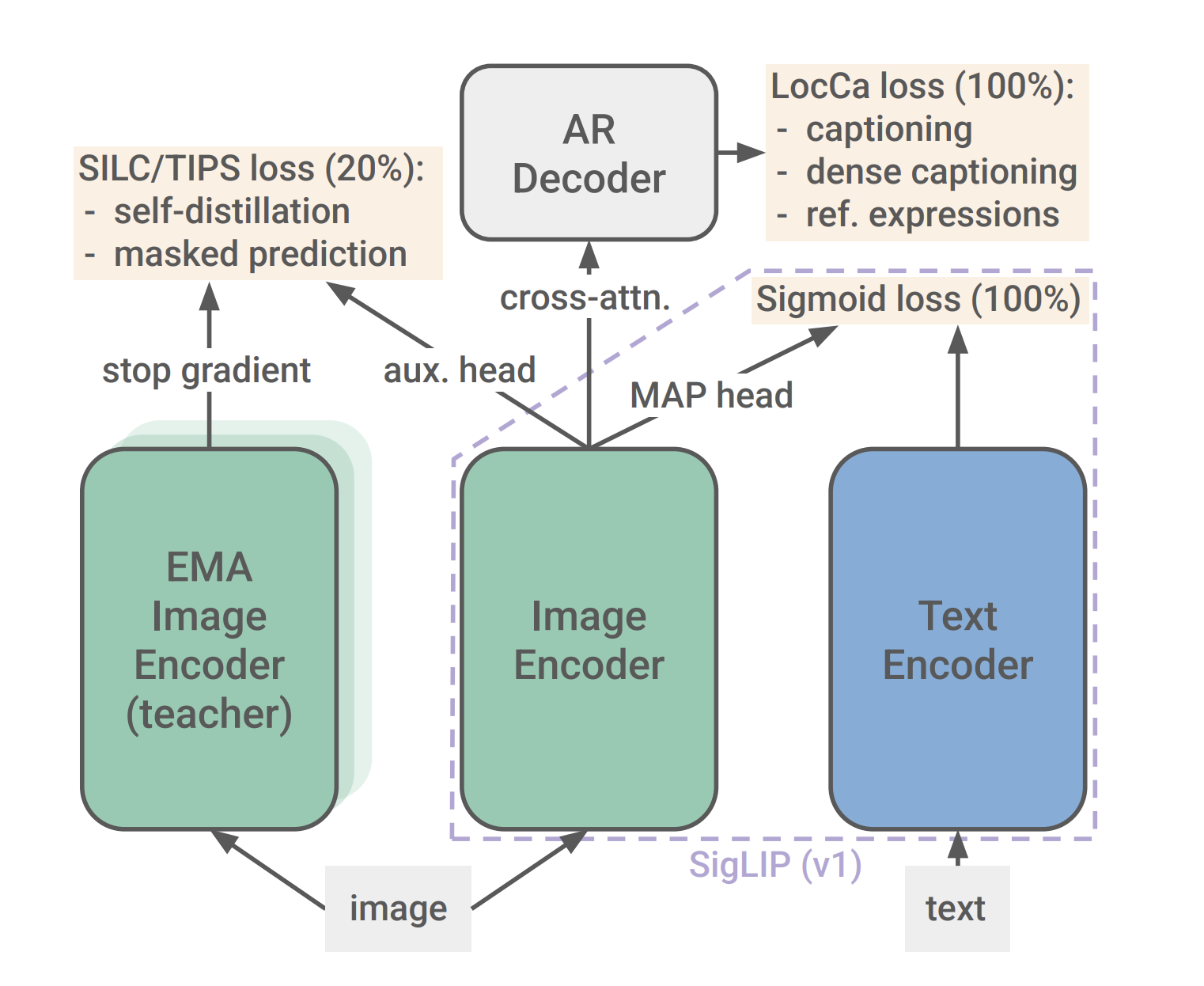
Google DeepMind Research Releases SigLIP2: A Family of New Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features
Modern vision-language models have transformed how we process visual data, yet they often fall short when it comes to fine-grained […]