
In the domain of multimodal AI, instruction-based image editing models are transforming how users interact with visual content. Just released […]
Category: Computer Vision
Meta AI Just Released DINOv3: A State-of-the-Art Computer Vision Model Trained with Self-Supervised Learning, Generating High-Resolution Image Features
Meta AI has just released DINOv3, a breakthrough self-supervised computer vision model that sets new standards for versatility and accuracy […]

VL-Cogito: Advancing Multimodal Reasoning with Progressive Curriculum Reinforcement Learning
Multimodal reasoning, where models integrate and interpret information from multiple sources such as text, images, and diagrams, is a frontier […]
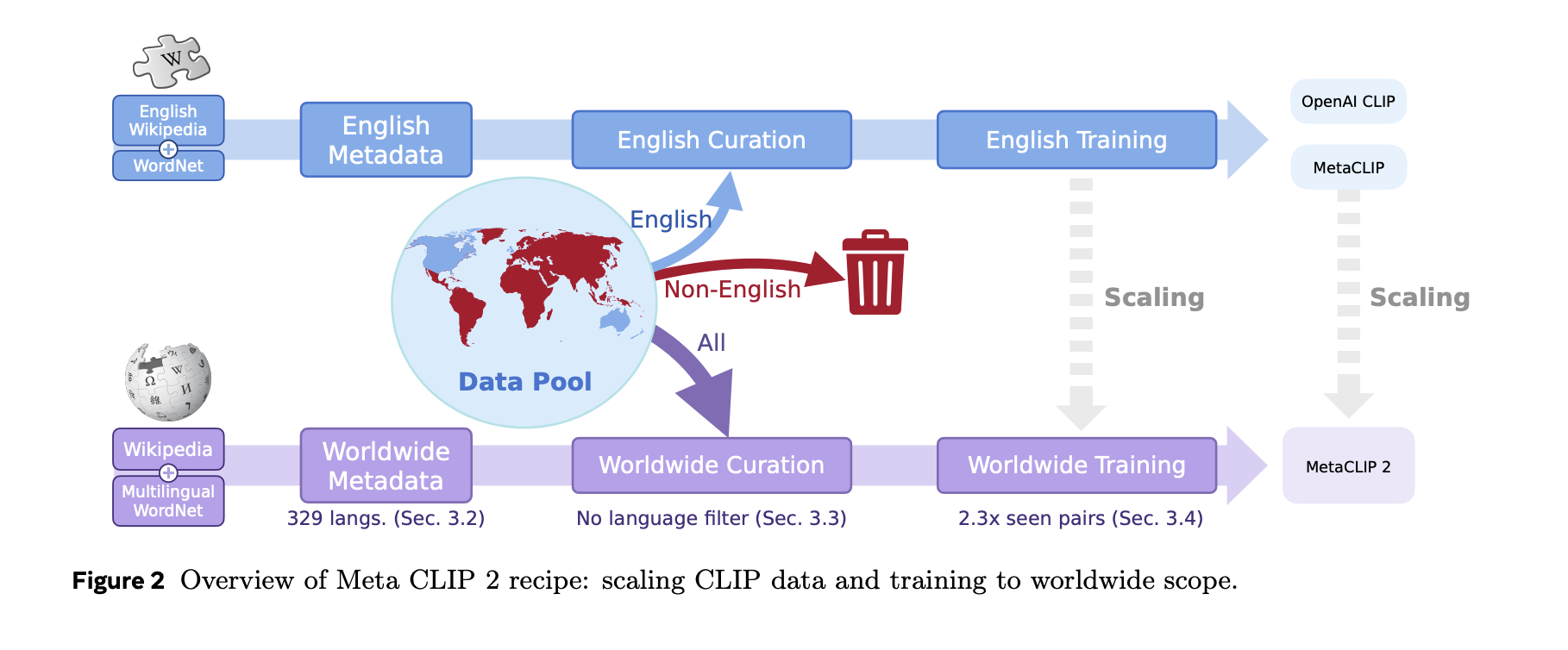
Meta CLIP 2: The First Contrastive Language-Image Pre-training (CLIP) Trained with Worldwide Image-Text Pairs from Scratch
Contrastive Language-Image Pre-training (CLIP) has become important for modern vision and multimodal models, enabling applications such as zero-shot image classification […]

NASA Releases Galileo: The Open-Source Multimodal Model Advancing Earth Observation and Remote Sensing
Introduction Galileo is an open-source, highly multimodal foundation model developed to process, analyze, and understand diverse Earth observation (EO) data […]
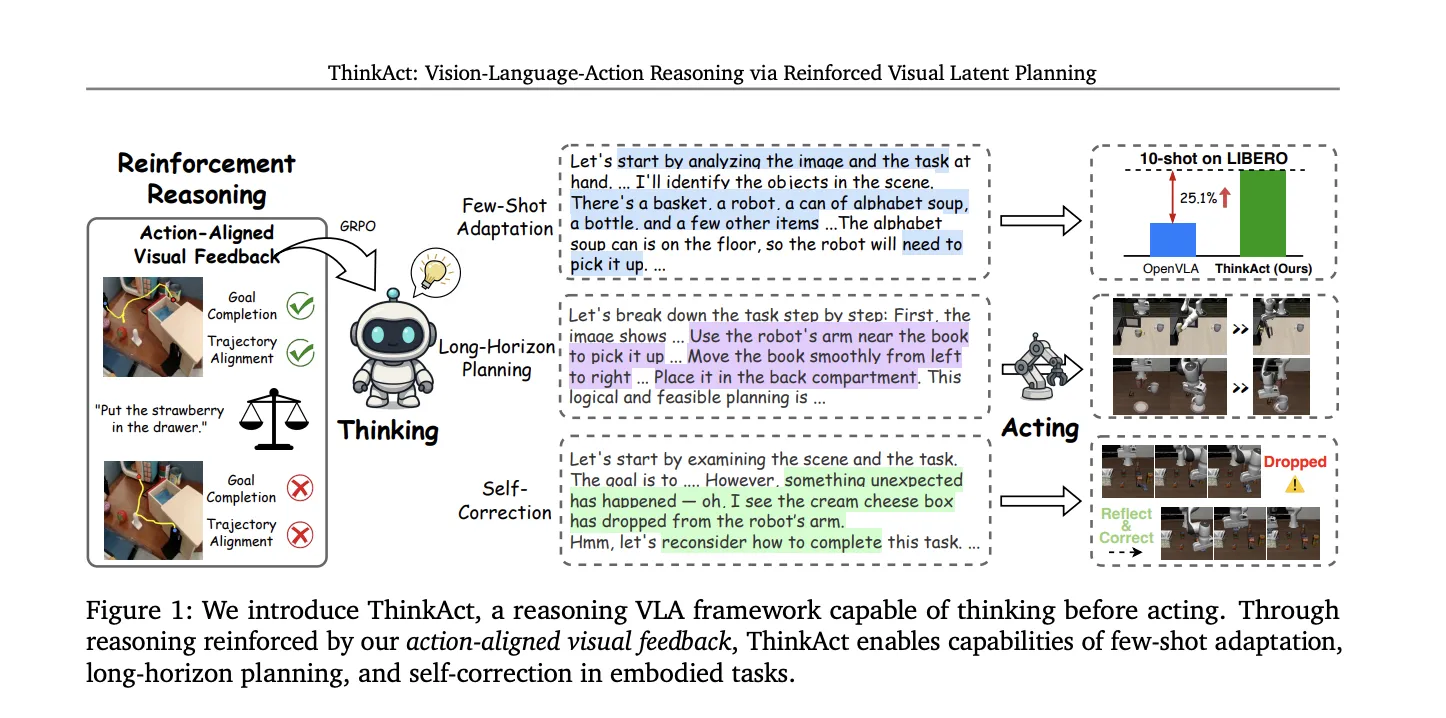
NVIDIA AI Presents ThinkAct: Vision-Language-Action Reasoning via Reinforced Visual Latent Planning
Estimated reading time: 5 minutes Table of contents Introduction The ThinkAct Framework Experimental Results Ablation Studies and Model Analysis Implementation […]

Apple Researchers Introduce FastVLM: Achieving State-of-the-Art Resolution-Latency-Accuracy Trade-off in Vision Language Models
Vision Language Models (VLMs) allow both text inputs and visual understanding. However, image resolution is crucial for VLM performance for […]
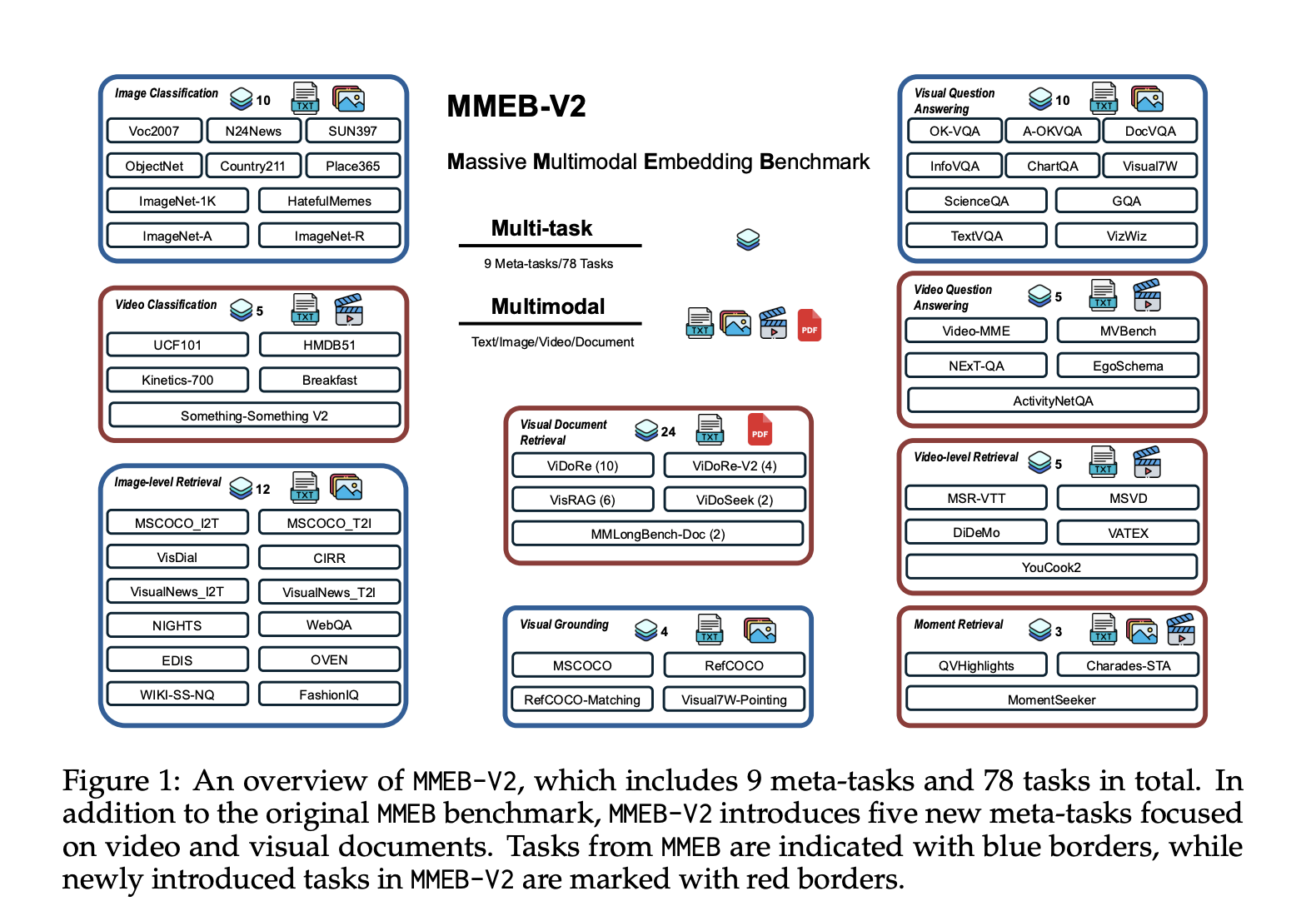
VLM2Vec-V2: A Unified Computer Vision Framework for Multimodal Embedding Learning Across Images, Videos, and Visual Documents
Embedding models act as bridges between different data modalities by encoding diverse multimodal information into a shared dense representation space. […]

RoboBrain 2.0: The Next-Generation Vision-Language Model Unifying Embodied AI for Advanced Robotics
Advancements in artificial intelligence are rapidly closing the gap between digital reasoning and real-world interaction. At the forefront of this […]

GPT-4o Understands Text, But Does It See Clearly? A Benchmarking Study of MFMs on Vision Tasks
Multimodal foundation models (MFMs) like GPT-4o, Gemini, and Claude have shown rapid progress recently, especially in public demos. While their […]