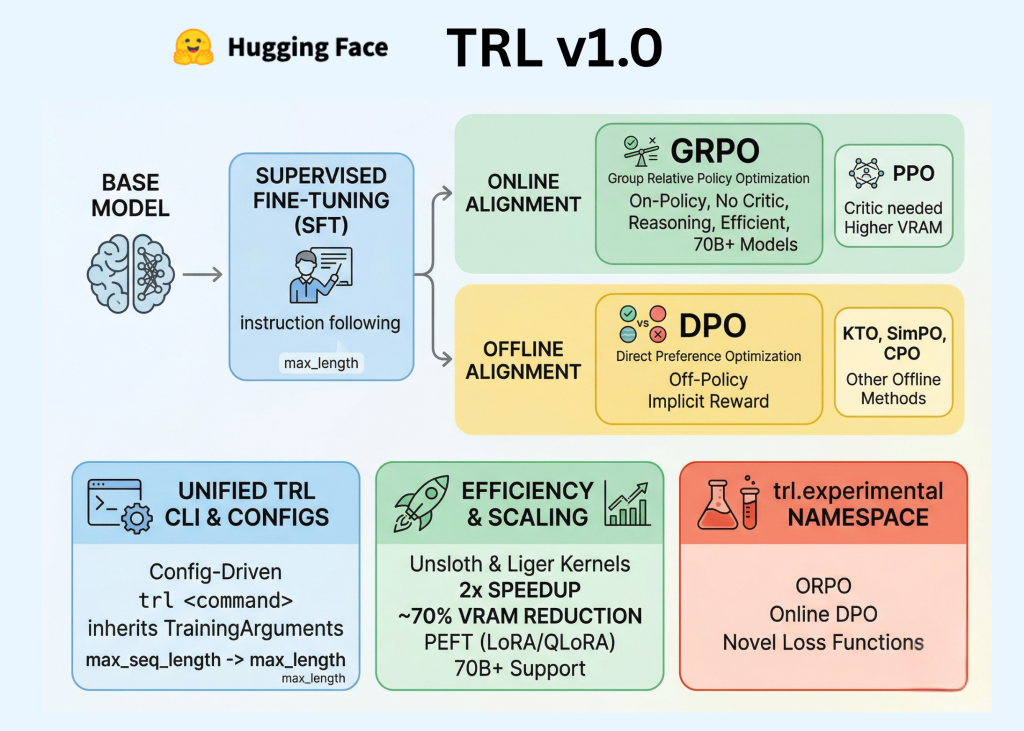
Hugging Face has officially released TRL (Transformer Reinforcement Learning) v1.0, marking a pivotal transition for the library from a research-oriented […]
Category: Applications

Google AI Releases Veo 3.1 Lite: Giving Developers Low Cost High Speed Video Generation via The Gemini API
Google has announced the release of Veo 3.1 Lite, a new model tier within its generative video portfolio designed to […]
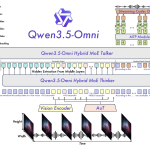
Alibaba Qwen Team Releases Qwen3.5 Omni: A Native Multimodal Model for Text, Audio, Video, and Realtime Interaction
The landscape of multimodal large language models (MLLMs) has shifted from experimental ‘wrappers’—where separate vision or audio encoders are stitched […]
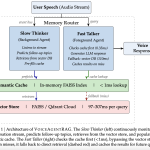
Salesforce AI Research Releases VoiceAgentRAG: A Dual-Agent Memory Router that Cuts Voice RAG Retrieval Latency by 316x
In the world of voice AI, the difference between a helpful assistant and an awkward interaction is measured in milliseconds. […]
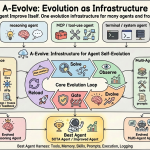
Meet A-Evolve: The PyTorch Moment For Agentic AI Systems Replacing Manual Tuning With Automated State Mutation And Self-Correction
A team of researchers associated with Amazon has released A-Evolve, a universal infrastructure designed to automate the development of autonomous […]

Chroma Releases Context-1: A 20B Agentic Search Model for Multi-Hop Retrieval, Context Management, and Scalable Synthetic Task Generation
In the current AI landscape, the ‘context window’ has become a blunt instrument. We’ve been told that if we simply […]
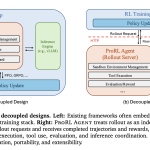
NVIDIA AI Unveils ProRL Agent: A Decoupled Rollout-as-a-Service Infrastructure for Reinforcement Learning of Multi-Turn LLM Agents at Scale
NVIDIA researchers introduced ProRL AGENT, a scalable infrastructure designed for reinforcement learning (RL) training of multi-turn LLM agents. By adopting […]
openJiuwen Community Releases ‘JiuwenClaw’: A Self Evolving AI Agent for Task Management
Over the past year, AI agents have evolved from merely answering questions to attempting to get real tasks done. However, […]

Meta Releases TRIBE v2: A Brain Encoding Model That Predicts fMRI Responses Across Video, Audio, and Text Stimuli
Neuroscience has long been a field of divide and conquer. Researchers typically map specific cognitive functions to isolated brain regions—like […]
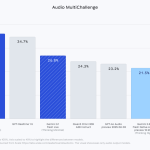
Google Releases Gemini 3.1 Flash Live: A Real-Time Multimodal Voice Model for Low-Latency Audio, Video, and Tool Use for AI Agents
Google has released Gemini 3.1 Flash Live in preview for developers through the Gemini Live API in Google AI Studio. […]