
Moonshot AI just released Kimi K3. It is a 2.8-trillion-parameter model with native vision and a 1-million-token context window. Moonshot […]
Category: AI Shorts
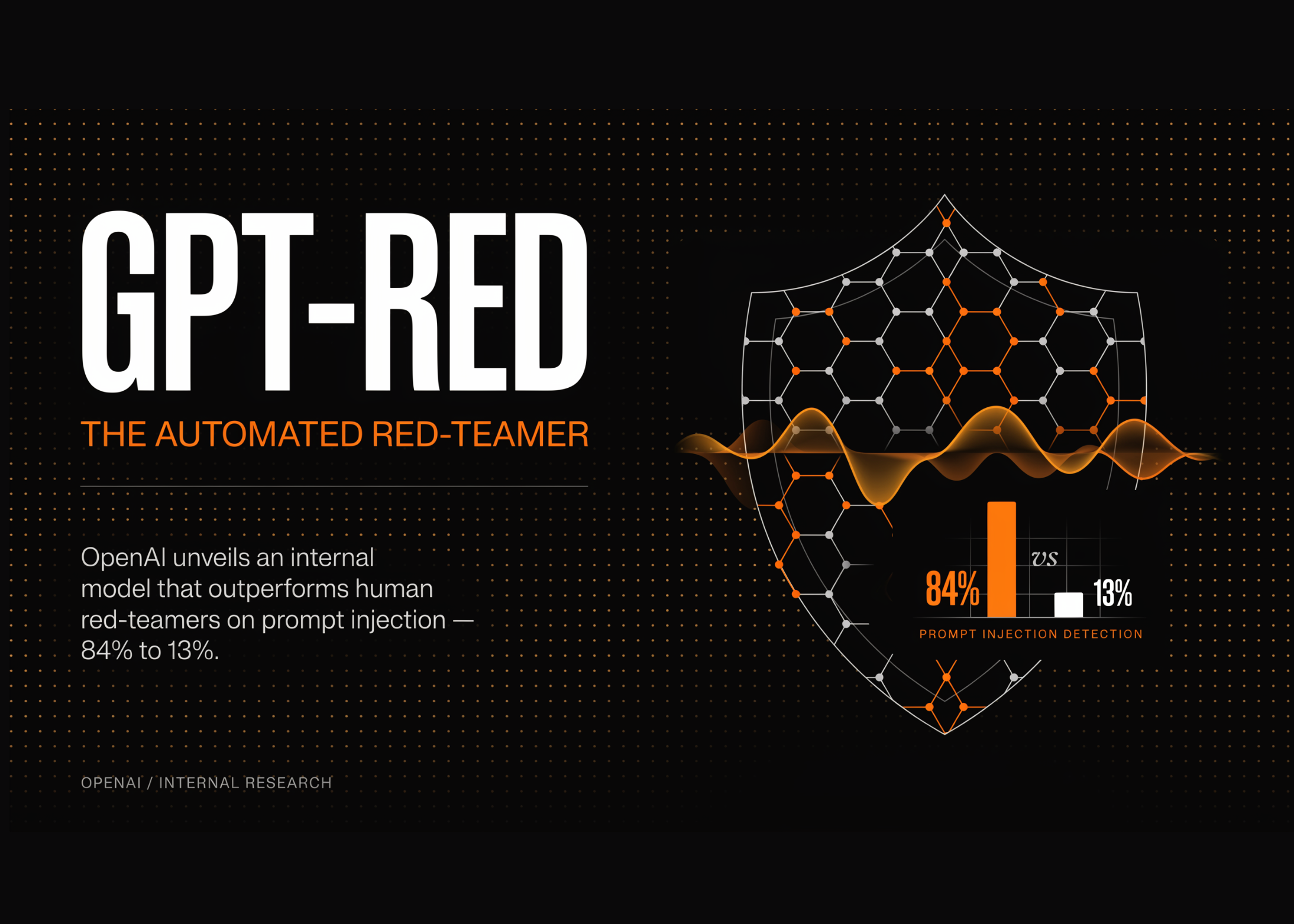
OpenAI Details GPT-Red: An Internal Automated Red-Teaming Model That Beat Human Red-Teamers 84% To 13% On Prompt Injection
This week, OpenAI published details of GPT-Red, an internal-only automated red-teaming model. Its job is to attack OpenAI’s own models […]

SpaceXAI Open-Sources Grok Build: The Rust Agent Harness, TUI, and Tool Layer Behind Its Coding CLI
SpaceXAI has open-sourced Grok Build, the terminal-based AI coding agent behind its grok CLI. The source landed on GitHub today. […]

Soofi Consortium Releases Soofi S 30B-A3B: An Open Hybrid Mamba-Transformer MoE Foundation Model For German And English
A German research consortium has published the pretraining report for Soofi S 30B-A3B. It is an open base model for […]

PrismML Releases Bonsai 27B: 1-bit and Ternary Builds of Qwen3.6-27B That Run on Laptops and Phones
PrismML just released Bonsai 27B. It is a low-bit representation of Qwen3.6-27B, not a new pretrain. The architecture is unchanged. […]

Meet Blume: An Open-Source, Zero-Config Documentation Framework That Ships AI-Ready Docs From a Markdown Folder
Hayden Bleasel, an expert developer from OpenAI, released Blume, an open-source documentation framework. Blume shipped to npm as version 1.0.3 […]

Anthropic Claude Sonnet 5 vs Sonnet 4.6 vs Opus 4.8: Agentic Coding Benchmarks, API Pricing, and Cost-Performance Tradeoffs Compared
Anthropic just shipped Claude Sonnet 5. They call it its most agentic Sonnet model yet. It plans, drives browsers and […]

Skyfall AI Releases MORPHEUS: A Persistent Enterprise Simulation Benchmark That Makes Continual Reinforcement Learning Necessary Under Structured Non-Stationarity
Most reinforcement learning benchmarks reset the world after every episode. Real operations never reset. Skyfall AI’s MORPHEUS targets that gap. […]

Stanford Researchers Introduce TRACE: A Capability-Targeted Agentic Training System That Turns Recurrent Agent Failures Into Synthetic RL Environment
Agentic LLMs often fail the same way, again and again. A Stanford research team traced this to missing, reusable capabilities. […]

Prime Intellect Releases Verifiers v1: Composable Tasksets, Harnesses, and Runtimes for Agentic RL Training and Evaluations
Prime Intellect launched verifiers 0.2.0. It previews a rewritten core, shipped under the new verifiers.v1 namespace. Modern evaluations now run […]