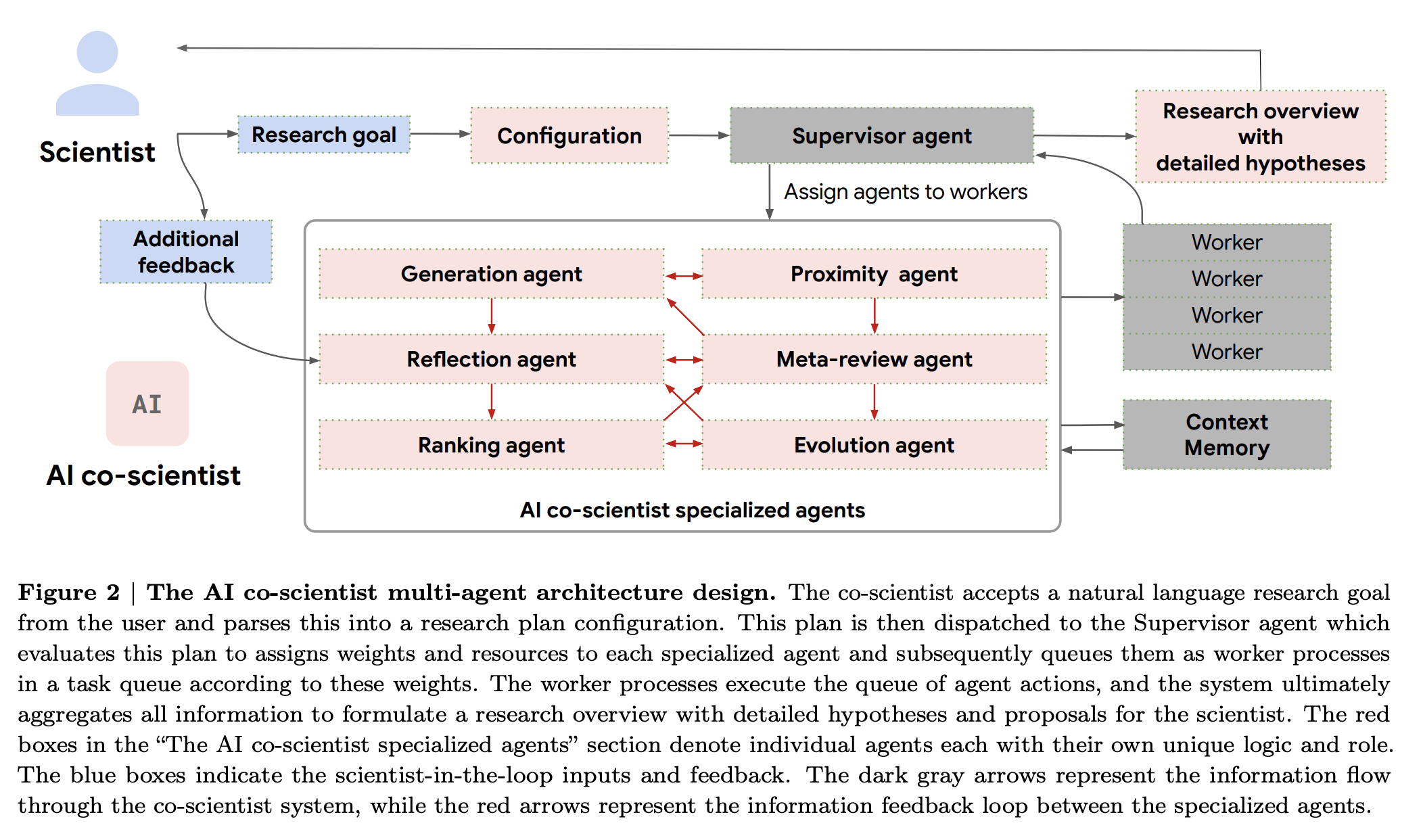
In this tutorial, we explore kvcached, a dynamic KV-cache implementation on top of vLLM, to understand how dynamic KV-cache allocation transforms GPU memory usage for large language models. We begin by setting up the environment and deploying lightweight Qwen2.5 models through an OpenAI-compatible API, ensuring a realistic inference workflow. We then design controlled experiments where we simulate bursty workloads to observe how memory behaves under both elastic and static allocation strategies. Through systematic measurement and visualization, we directly compare VRAM utilization and latency, and extend the setup to a multi-model scenario where we observe how memory flexibly shifts across active workloads in real time.
import os, sys, time, json, subprocess, threading, signal, shutil from pathlib import Path def sh(cmd, check=True): return subprocess.run(cmd, check=check, shell=isinstance(cmd, str)) try: import torch except ImportError: sh([sys.executable, "-m", "pip", "install", "-q", "torch"]) import torch assert torch.cuda.is_available(), "No GPU detected. In Colab: Runtime > Change runtime type > GPU." props = torch.cuda.get_device_properties(0) print(f"[GPU] {torch.cuda.get_device_name(0)} " f"({props.total_memory / 1e9:.1f} GB, " f"compute capability {props.major}.{props.minor})") def pip_install(*pkgs, extra=()): subprocess.run([sys.executable, "-m", "pip", "install", "-q", *pkgs, *extra], check=True) print("[install] vLLM ...") pip_install("vllm==0.10.2") print("[install] kvcached (compiles a small CUDA extension) ...") pip_install("kvcached", extra=["--no-build-isolation"]) print("[install] misc (matplotlib, requests, pynvml) ...") pip_install("matplotlib", "requests", "pynvml", "numpy") MODEL_A = "Qwen/Qwen2.5-0.5B-Instruct" MODEL_B = "Qwen/Qwen2.5-1.5B-Instruct" PORT_A, PORT_B = 8001, 8002 MAX_MODEL_LEN = 2048We start by setting up the environment and verifying that a GPU is available for our experiments. We install all required dependencies including vLLM and kvcached along with supporting libraries. We then define our model configurations and ports to prepare for launching the inference servers.
def launch_vllm(model, port, kvcached=True, gpu_mem_util=0.55, log_path=None): """Start a vLLM OpenAI-compatible server as a subprocess. With kvcached=True the autopatch hooks replace vLLM's KV-cache allocator with the elastic one.""" env = os.environ.copy() env["VLLM_USE_V1"] = "1" if kvcached: env["ENABLE_KVCACHED"] = "true" env["KVCACHED_AUTOPATCH"] = "1" env["KVCACHED_IPC_NAME"] = f"kvc_{port}" cmd = [ sys.executable, "-m", "vllm.entrypoints.openai.api_server", "--model", model, "--port", str(port), "--max-model-len", str(MAX_MODEL_LEN), "--disable-log-requests", "--no-enable-prefix-caching", "--enforce-eager", ] if not kvcached: cmd += ["--gpu-memory-utilization", str(gpu_mem_util)] log = open(log_path or os.devnull, "w") proc = subprocess.Popen(cmd, env=env, stdout=log, stderr=subprocess.STDOUT, preexec_fn=os.setsid) return proc, log def wait_ready(port, timeout=420): import requests url = f"http://localhost:{port}/v1/models" t0 = time.time() while time.time() - t0 < timeout: try: if requests.get(url, timeout=2).status_code == 200: return True except Exception: pass time.sleep(3) raise TimeoutError(f"vLLM on port {port} didn't come up within {timeout}s") def shutdown(proc, log): if proc and proc.poll() is None: try: os.killpg(os.getpgid(proc.pid), signal.SIGTERM) proc.wait(timeout=45) except Exception: os.killpg(os.getpgid(proc.pid), signal.SIGKILL) if log and not log.closed: log.close() time.sleep(3)We implement helper functions to launch and manage the vLLM server with and without kvcached enabled. We configure environment variables to activate dynamic KV-cache behavior and ensure proper server initialization. We also define utilities to wait for server readiness and safely shut down processes after execution.

import pynvml pynvml.nvmlInit() NV_HANDLE = pynvml.nvmlDeviceGetHandleByIndex(0) def vram_used_mb(): info = pynvml.nvmlDeviceGetMemoryInfo(NV_HANDLE) return info.used / (1024 ** 2) class MemorySampler(threading.Thread): def __init__(self, interval=0.2): super().__init__(daemon=True) self.interval = interval self.samples = [] self._stop = threading.Event() def run(self): t0 = time.time() while not self._stop.is_set(): self.samples.append((time.time() - t0, vram_used_mb())) time.sleep(self.interval) def stop(self): self._stop.set(); self.join() import requests from concurrent.futures import ThreadPoolExecutor PROMPTS = [ "Explain quantum entanglement to a curious 10-year-old.", "Write a Python function that detects cycles in a linked list.", "Summarize the plot of Hamlet in one paragraph.", "List 5 surprising household uses for baking soda with explanations.", "Compose a vivid haiku about rainy Monday mornings.", "Describe the Fermi paradox and three plausible resolutions.", "Translate 'knowledge is power' into French, German, and Japanese.", "Explain the difference between TCP and UDP with real examples.", ] def bursty_workload(port, model, n_bursts=3, burst_size=6, pause=6.0, max_tokens=180): """Fire n_bursts waves of burst_size concurrent requests with an idle gap between waves. The idle gap is where kvcached releases physical VRAM -- a static-allocation engine simply cannot.""" url = f"http://localhost:{port}/v1/chat/completions" def one(i): body = { "model": model, "messages": [{"role": "user", "content": PROMPTS[i % len(PROMPTS)]}], "max_tokens": max_tokens, "temperature": 0.7, } t0 = time.time() r = requests.post(url, json=body, timeout=180) r.raise_for_status() return time.time() - t0 latencies = [] with ThreadPoolExecutor(max_workers=burst_size) as ex: for b in range(n_bursts): print(f" burst {b+1}/{n_bursts} ({burst_size} concurrent)") latencies += list(ex.map(one, range(burst_size))) if b < n_bursts - 1: time.sleep(pause) return latenciesWe initialize GPU memory tracking using pynvml to monitor VRAM usage in real time. We create a background sampling thread that continuously records memory consumption during experiments. We then define a bursty workload generator that sends concurrent requests to simulate realistic LLM usage patterns.
print("n=== Experiment 1: vLLM + kvcached ===") proc, log = launch_vllm(MODEL_A, PORT_A, kvcached=True, log_path="https://www.marktechpost.com/tmp/vllm_kvc.log") try: wait_ready(PORT_A) idle_kvc = vram_used_mb() print(f" Idle VRAM after load (weights only): {idle_kvc:.0f} MB") sampler = MemorySampler(); sampler.start() lat_kvc = bursty_workload(PORT_A, MODEL_A) time.sleep(6) sampler.stop() mem_kvc = sampler.samples finally: shutdown(proc, log) print("n=== Experiment 2: vLLM baseline (static KV allocation) ===") proc, log = launch_vllm(MODEL_A, PORT_A, kvcached=False, log_path="https://www.marktechpost.com/tmp/vllm_base.log") try: wait_ready(PORT_A) idle_base = vram_used_mb() print(f" Idle VRAM (weights + pre-reserved KV pool): {idle_base:.0f} MB") sampler = MemorySampler(); sampler.start() lat_base = bursty_workload(PORT_A, MODEL_A) time.sleep(6) sampler.stop() mem_base = sampler.samples finally: shutdown(proc, log)We run the first experiment with kvcached enabled and capture both memory usage and latency metrics. We then execute the same workload under a baseline static allocation setup for comparison. We collect and store all results to enable a clear side-by-side evaluation of both approaches.
import numpy as np import matplotlib.pyplot as plt fig, axes = plt.subplots(1, 2, figsize=(14, 4.5)) tk, mk = zip(*mem_kvc); tb, mb = zip(*mem_base) axes[0].plot(tk, mk, label="with kvcached", linewidth=2, color="#1f77b4") axes[0].plot(tb, mb, label="baseline (static)", linewidth=2, linestyle="--", color="#d62728") axes[0].axhline(idle_kvc, color="#1f77b4", alpha=.3, linestyle=":") axes[0].axhline(idle_base, color="#d62728", alpha=.3, linestyle=":") axes[0].set_xlabel("time (s)"); axes[0].set_ylabel("GPU memory used (MB)") axes[0].set_title("VRAM under a bursty workloadn(dotted = idle-baseline VRAM)") axes[0].grid(alpha=.3); axes[0].legend() axes[1].boxplot([lat_kvc, lat_base], labels=["kvcached", "baseline"]) axes[1].set_ylabel("request latency (s)") axes[1].set_title(f"Latency across {len(lat_kvc)} requests") axes[1].grid(alpha=.3) plt.tight_layout() plt.savefig("https://www.marktechpost.com/content/kvcached_single_model.png", dpi=120, bbox_inches="tight") plt.show() print("n--- Single-model summary --------------------------------------------") print(f" Idle VRAM kvcached: {idle_kvc:>6.0f} MB " f"baseline: {idle_base:>6.0f} MB " f"(savings: {idle_base - idle_kvc:>5.0f} MB)") print(f" Peak VRAM kvcached: {max(mk):>6.0f} MB " f"baseline: {max(mb):>6.0f} MB") print(f" Median lat. kvcached: {np.median(lat_kvc):>6.2f} s " f"baseline: {np.median(lat_base):>6.2f} s") print(f" VRAM flex kvcached: peak-idle = {max(mk)-min(mk):>5.0f} MB " f"(baseline can't release -- static pool)") print("n=== Experiment 3: Two LLMs sharing one GPU (kvcached on both) ===") pA, lA = launch_vllm(MODEL_A, PORT_A, kvcached=True, log_path="https://www.marktechpost.com/tmp/mA.log") try: wait_ready(PORT_A) pB, lB = launch_vllm(MODEL_B, PORT_B, kvcached=True, log_path="https://www.marktechpost.com/tmp/mB.log") try: wait_ready(PORT_B) print(f" Both models loaded. Idle VRAM: {vram_used_mb():.0f} MB") sampler = MemorySampler(); sampler.start() for i in range(4): port, model = ((PORT_A, MODEL_A) if i % 2 == 0 else (PORT_B, MODEL_B)) print(f" round {i+1}: driving {model}") bursty_workload(port, model, n_bursts=1, burst_size=4, pause=0) time.sleep(5) sampler.stop() t, m = zip(*sampler.samples) plt.figure(figsize=(11, 4.2)) plt.plot(t, m, color="#c2410c", linewidth=2) plt.xlabel("time (s)"); plt.ylabel("GPU memory used (MB)") plt.title("Two LLMs on one T4 via kvcached — memory flexes per active model") plt.grid(alpha=.3); plt.tight_layout() plt.savefig("https://www.marktechpost.com/content/kvcached_multillm.png", dpi=120, bbox_inches="tight") plt.show() finally: shutdown(pB, lB) finally: shutdown(pA, lA) print("n=== Bonus: kvcached ships CLI tools ===") print(" kvtop — live per-instance KV memory monitor (like nvtop for kvcached)") print(" kvctl — set/limit per-instance memory budgets in shared memory") for tool in ("kvtop", "kvctl"): path = shutil.which(tool) print(f" {tool}: {path or 'not on PATH'}") print("nAll plots saved to /content/. Done.")We visualize the collected data by plotting VRAM usage trends and latency distributions across both setups. We compute summary statistics to quantify improvements in memory efficiency and performance. We finally extend the experiment to a multi-model scenario, observe how memory dynamically adapts across active models, and conclude with additional insights into tooling.
In conclusion, we demonstrated how dynamic KV-cache management fundamentally improves GPU efficiency compared to traditional static allocation approaches. We observed that kvcached enables significant VRAM savings during idle periods while maintaining competitive latency under load, making it especially effective for bursty or multi-tenant inference environments. By running multiple models on a single GPU and alternating traffic, we clearly saw how memory is allocated only when needed and released when idle, validating the core premise of demand-driven caching. Overall, we established a practical and reproducible framework for evaluating memory optimization techniques in LLM serving and highlighted how this approach can scale to more complex, production-grade deployments.
Check out the Full Codes with Notebook. Also, feel free to follow us on Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us

Sana Hassan
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.