Large language models have significantly advanced our understanding of artificial intelligence, yet scaling these models efficiently remains challenging. Traditional Mixture-of-Experts (MoE) architectures activate only a subset of experts per token to economize on computation. However, this design leads to two notable issues. First, experts process tokens in isolation—each expert works independently without any cross-communication. This separation can limit the model’s ability to harness diverse perspectives during processing. Second, although MoE architectures use a sparse activation pattern, they still require considerable memory because the overall parameter count is high even if only a few are active at a time. These challenges suggest that while MoE models are a step forward in scalability, their inherent design may limit both performance and resource efficiency.
The Chain-of-Experts (CoE) Approach
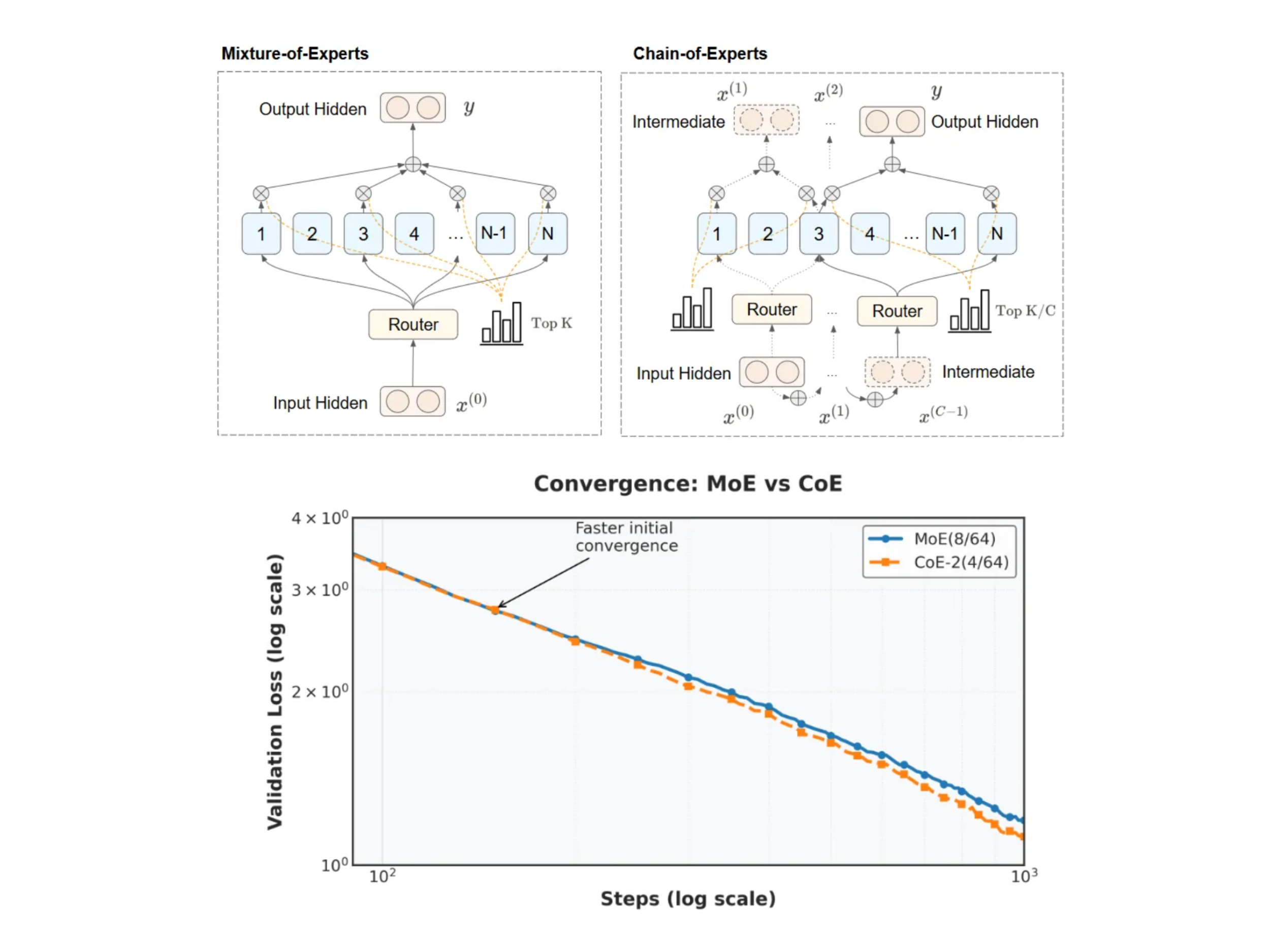
Chain-of-Experts (CoE) offers a thoughtful reexamination of MoE architectures by introducing a mechanism for sequential communication among experts. In contrast to the independent processing seen in traditional MoE models, CoE allows tokens to be processed in a series of iterations within each layer. In this arrangement, the output of one expert serves as the input for the next, thereby creating a communicative chain that enables experts to build upon one another’s work. This sequential interaction does not simply stack layers; it facilitates a more integrated approach to token processing, where each expert refines the interpretation of the token based on previous outputs. The result is a model that leverages the collaborative potential of its experts while aiming to use memory more efficiently [][
Technical Details and Benefits
At the heart of the CoE method is an iterative process that redefines how experts interact. For instance, consider a configuration described as CoE-2(4/64): the model operates with two iterations per token, with four experts selected from a pool of 64 available experts at each cycle. This design contrasts with traditional MoE setups, which rely on a single pass through a pre-selected group of experts.
A key technical element in CoE is the independent gating mechanism. In conventional MoE models, the gating function selects which experts should process a token, but these decisions are made once per token per layer. CoE extends this idea by allowing each expert’s gating decision to be made independently during each iteration. This flexibility encourages a form of specialization, where an expert can adjust its processing based on information received from earlier iterations.
Additionally, the use of inner residual connections in CoE further improves the model. Instead of simply adding the original token back after the entire sequence of processing (an outer residual connection), CoE integrates residual connections within each iteration. This design helps maintain the integrity of the token’s information while allowing for incremental improvements at every step.
These technical innovations collectively contribute to a model that not only maintains performance with fewer resources but also provides a more nuanced processing pathway that could be particularly valuable for tasks that require layered reasoning.
Experimental Results and Insights
Empirical studies underscore the potential of the Chain-of-Experts method. In controlled experiments—such as pretraining on math-related tasks—configurations like CoE-2(4/64) have demonstrated a reduction in validation loss (from 1.20 to 1.12) when compared with traditional MoE models operating under the same computational conditions. This improvement is achieved without increasing the overall memory or computational cost, as the sequential communication enables a more effective use of each expert’s capacity.
Further evaluations have shown that increasing the iteration count in CoE can yield benefits that are comparable to or even exceed those obtained by increasing the number of experts selected in a single pass. For instance, even when memory and compute budgets are held constant, CoE configurations exhibit up to an 18% reduction in memory usage while achieving similar or better performance outcomes.
Moreover, the sequential design of CoE opens up a substantially larger number of expert combinations—by as much as 823 times more than traditional methods. This dramatic increase in possible expert pathways means that the model has a richer set of options when processing each token, potentially leading to more robust and specialized outputs.
These findings suggest that CoE provides a pathway for rethinking how large language models can be both efficient and effective, paving the way for more sustainable AI applications in the future.
Conclusion
The Chain-of-Experts framework represents a measured evolution in the design of sparse neural networks. By introducing sequential communication among experts, CoE addresses the limitations of independent token processing and high memory usage inherent in traditional MoE models. The technical innovations—particularly the independent gating mechanism and inner residual connections—enable a more efficient and flexible approach to scaling large language models.
The experimental results, though preliminary, suggest that CoE can achieve modest yet meaningful improvements in performance and resource utilization. This approach invites further exploration, particularly in how iterative communication might be extended or refined in future model architectures. As research in this area continues, CoE stands as a thoughtful step toward achieving a balance between computational efficiency and model performance, one that may ultimately contribute to more accessible and sustainable AI systems
Check out the Technical details and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.
Aswin Ak
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.