Can a fully sovereign open reasoning model match state of the art systems when every part of its training pipeline is transparent. Researchers from Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) release K2 Think V2, a fully sovereign reasoning model designed to test how far open and fully documented pipelines can push long horizon reasoning on math, code, and science when the entire stack is open and reproducible. K2 Think V2 takes the 70 billion parameter K2 V2 Instruct base model and applies a carefully engineered reinforcement learning approach to turn it into a high precision reasoning model that remains fully open in both weights and data.

From K2 V2 base model to reasoning specialist
K2 V2 is a dense decoder only transformer with 80 layers, hidden size 8192, and 64 attention heads with grouped query attention and rotary position embeddings. It is trained on around 12 trillion tokens drawn from the TxT360 corpus and related curated datasets that cover web text, math, code, multilingual data, and scientific literature.
Training proceeds in three phases. Pretraining runs at context length 8192 tokens on natural data to establish robust general knowledge. Mid training then extends context up to 512k tokens using TxT360 Midas, which mixes long documents, synthetic thinking traces, and diverse reasoning behaviors while carefully keeping at least 30 percent short context data in every stage. Finally, supervised fine tuning, called TxT360 3efforts, injects instruction following and structured reasoning signals.
The important point is that K2 V2 is not a generic base model. It is explicitly optimized for long context consistency and exposure to reasoning behaviors during mid training. That makes it a natural foundation for a post training stage that focuses only on reasoning quality, which is exactly what K2 Think V2 does.
Fully sovereign RLVR on GURU dataset
K2 Think V2 is trained with a GRPO style RLVR recipe on top of K2 V2 Instruct. The team uses the Guru dataset, version 1.5, which focuses on math, code, and STEM questions. Guru is derived from permissively licensed sources, expanded in STEM coverage, and decontaminated against key evaluation benchmarks before use. This is important for a sovereign claim, because both the base model data and the RL data are curated and documented by the same institute.
The GRPO setup removes the usual KL and entropy auxiliary losses and uses asymmetric clipping of the policy ratio with the high clip set to 0.28. Training runs fully on policy with temperature 1.2 to increase rollout diversity, global batch size 256, and no micro batching. This avoids off policy corrections that are known to introduce instability in GRPO like training.
RLVR itself runs in two stages. In the first stage, response length is capped at 32k tokens and the model trains for about 200 steps. In the second stage, the maximum response length is increased to 64k tokens and training continues for about 50 steps with the same hyperparameters. This schedule specifically exploits the long context capability inherited from K2 V2 so that the model can practice full chain of thought trajectories rather than short solutions.
Benchmark profile
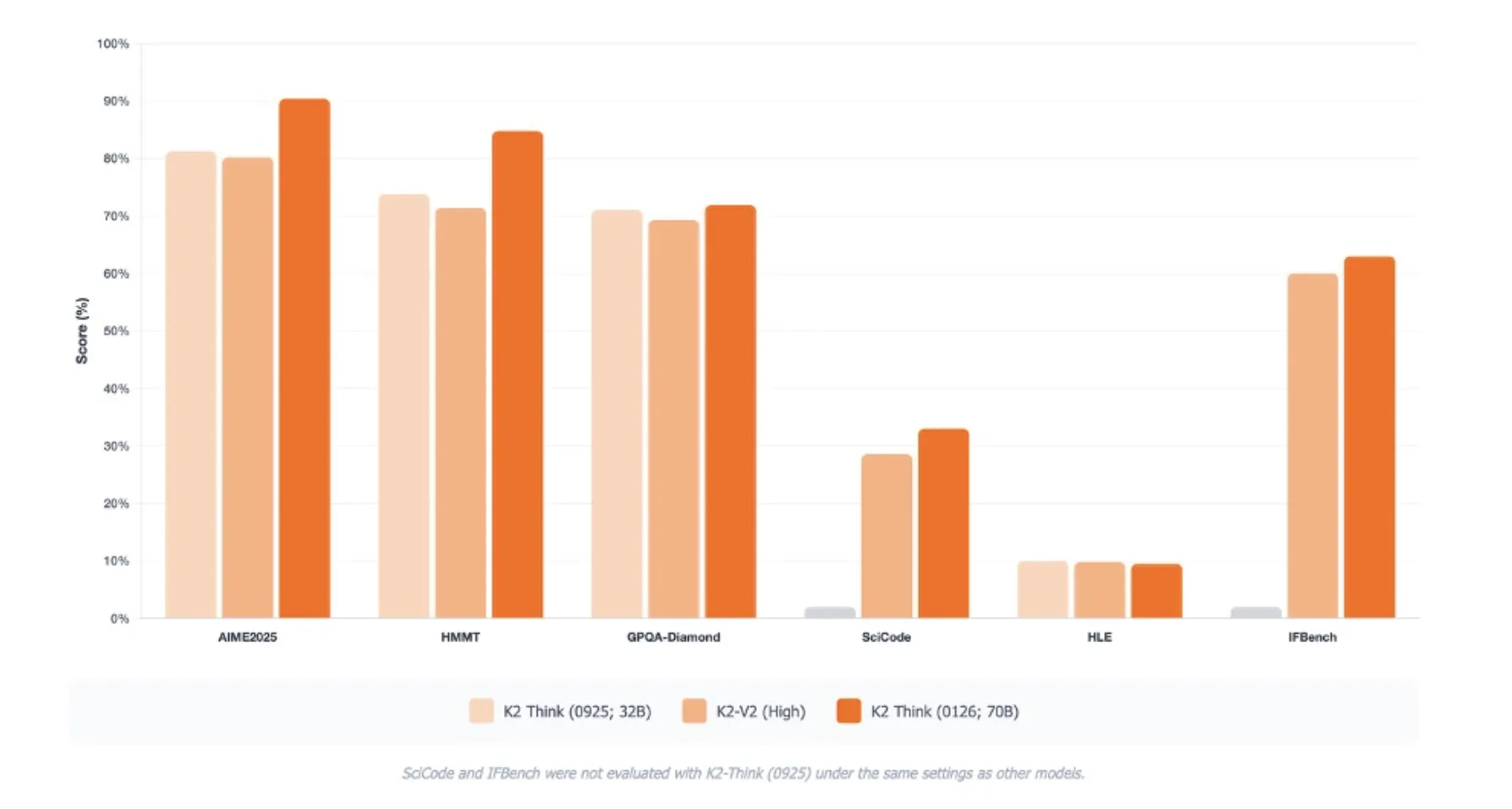
K2 Think V2 targets reasoning benchmarks rather than purely knowledge benchmarks. On AIME 2025 it reaches pass at 1 of 90.42. On HMMT 2025 it scores 84.79. On GPQA Diamond, a difficult graduate level science benchmark, it reaches 72.98. On SciCode it records 33.00, and on Humanity’s Last Exam it reaches 9.5 under the benchmark settings.
These scores are reported as averages over 16 runs and are directly comparable only within the same evaluation protocol. The MBZUAI team also highlights improvements on IFBench and on the Artificial Analysis evaluation suite, with particular gains in hallucination rate and long context reasoning compared with the previous K2 Think release.
Safety and openness
The research team reports a Safety 4 style analysis that aggregates four safety surfaces. Content and public safety, truthfulness and reliability, and societal alignment all reach macro average risk levels in the low range. Data and infrastructure risks remain higher and are marked as critical, which reflects concerns about sensitive personal information handling rather than model behavior alone. The team states that K2 Think V2 still shares the generic limitations of large language models despite these mitigations. On Artificial Analysis’s Openness Index, K2 Think V2 sits at the frontier together with K2 V2 and Olmo-3.
Key Takeaways
- K2 Think V2 is a fully sovereign 70B reasoning model: Built on K2 V2 Instruct, with open weights, open data recipes, detailed training logs, and full RL pipeline released via Reasoning360.
- Base model is optimized for long context and reasoning before RL: K2 V2 is a dense decoder transformer trained on around 12T tokens, with mid training extending context length to 512K tokens and supervised ‘3 efforts’ SFT targeting structured reasoning.
- Reasoning is aligned using GRPO based RLVR on the Guru dataset: Training uses a 2 stage on policy GRPO setup on Guru v1.5, with asymmetric clipping, temperature 1.2, and response caps at 32K then 64K tokens to learn long chain of thought solutions.
- Competitive results on hard reasoning benchmarks: K2 Think V2 reports strong pass at 1 scores such as 90.42 on AIME 2025, 84.79 on HMMT 2025, and 72.98 on GPQA Diamond, positioning it as a high precision open reasoning model for math, code, and science.
Check out the Paper, Model Weight, Repo and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Maxime Mommessin
Max is an AI analyst at MarkTechPost, based in Silicon Valley, who actively shapes the future of technology. He teaches robotics at Brainvyne, combats spam with ComplyEmail, and leverages AI daily to translate complex tech advancements into clear, understandable insights