
Particle-based simulations and point-cloud applications are driving a massive expansion in the size and complexity of scientific and commercial datasets, often leaping into the realm of billions or trillions of discrete points. Efficiently reducing, storing, and analyzing this data without bottlenecking modern GPUs is one of the emerging grand challenges in fields like cosmology, geology, molecular dynamics, and 3D imaging. Recently, a team of researchers from Florida State University, the University of Iowa, Argonne National Laboratory, the University of Chicago, and several other institutions introduced GPZ, a GPU-optimized, error-bounded lossy compressor that radically improves throughput, compression ratio, and data fidelity for particle data—outperforming five state-of-the-art alternatives by wide margins.
Why Compress Particle Data? And Why is It So Hard?
Particle (or point-cloud) data—unlike structured meshes—represents systems as irregular collections of discrete elements in multidimensional space. This format is essential for capturing complex physical phenomena, but has low spatial and temporal coherence and almost no redundancy, making it a nightmare for classical lossless or generic lossy compressors.
Consider:
- The Summit supercomputer generated a single cosmological simulation snapshot of 70 TB using Nvidia V100 GPUs.
- The USGS 3D Elevation Program’s point clouds of U.S. terrain exceed 200 TB of storage.
Traditional approaches—like downsampling or on-the-fly processing—throw away up to 90% of raw data or foreclose reproducibility through lack of storage. Moreover, generic mesh-focused compressors exploit correlations that simply don’t exist in particle data, yielding poor ratios and abysmal GPU throughput.
GPZ: Architecture and Innovations
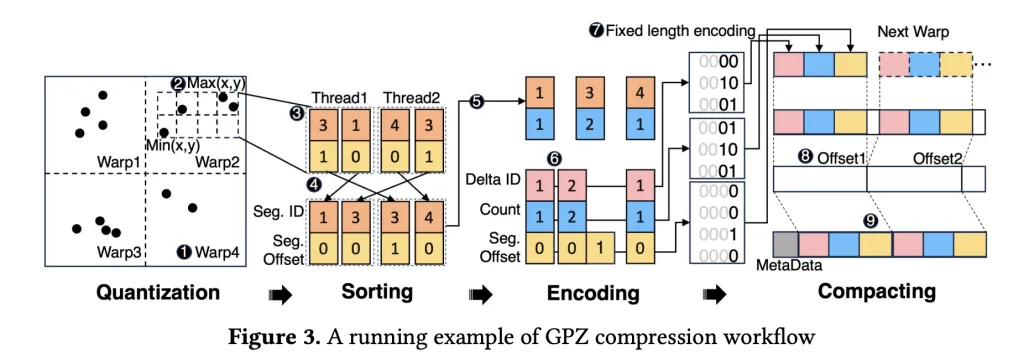
GPZ comes equipped with a four-stage, parallel GPU pipeline—specially engineered for the quirks of particle data and the stringent demands of modern massively-parallel hardware.
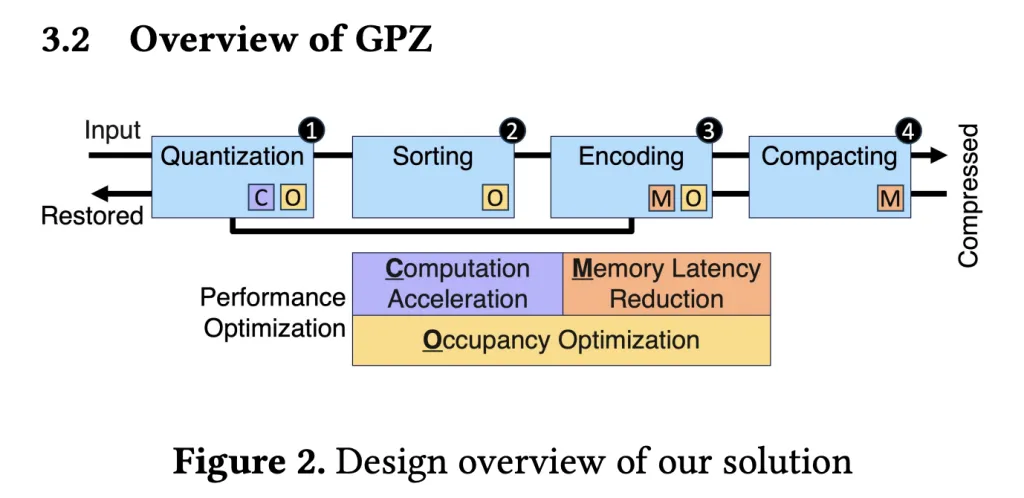
Pipeline Stages:
- Spatial Quantization
- Particles’ floating-point positions are mapped to integer segment IDs and offsets, respecting user-specified error bounds while leveraging fast FP32 operations for maximum GPU arithmetic throughput.
- Segment sizes are tuned for optimal GPU occupancy.
- Spatial Sorting
- Within each block (mapped to a CUDA warp), particles are sorted by their segment ID to enhance subsequent lossless coding—using warp-level operations to avoid costly synchronization.
- Block-level sort balances compression ratio with shared memory footprint for best parallelism.
- Lossless Encoding
- Innovative parallel run-length and delta encoding strip redundancy from sorted segment IDs and quantized offsets.
- Bit-plane coding eliminates zero bits, with all steps heavily optimized for GPU memory access patterns.
- Compacting
- Compressed blocks are efficiently assembled into a contiguous output using a three-step device-level strategy that slashes synchronization overheads and maximizes memory throughput (809 GB/s on RTX 4090, near theoretical peak).
Decompression is the reverse—extract, decode, and reconstruct positions within error bounds, enabling high-fidelity post-hoc analysis.
Hardware-Aware Performance Optimizations
GPZ sets itself apart with a suite of hardware-centric optimizations:
- Memory coalescing: Reads and writes are carefully aligned to 4-byte boundaries maximizing DRAM bandwidth (up to 1.6x improvement over strided access).
- Register and shared memory management: Algorithms are designed to keep occupancy high. Precision is dropped to FP32 where possible, and excessive register use is avoided to prevent spills.
- Compute scheduling: One-warp-per-block mapping, explicit use of CUDA intrinsics like FMA operations, and loop unrolling where beneficial.
- Division/modulo elimination: Replacing slow division/modulo operations with precomputed reciprocals and bitwise masks where possible.
Benchmarking: GPZ vs. State-of-the-Art
GPZ was evaluated on six real-world datasets (from cosmology, geology, plasma physics, and molecular dynamics), spanning three GPU architectures:
- Consumer: RTX 4090,
- Data center: H100 SXM,
- Edge: Nvidia L4.
Baselines included:
- cuSZp2
- PFPL
- FZ-GPU
- cuSZ
- cuSZ-i
Most of these tools, optimized for generic scientific meshes, failed or showed severe performance/quality drop-offs on particle datasets over 2 GB; GPZ remained robust throughout.
Results:
- Speed: GPZ delivered compression throughputs up to 8x higher than the next-best competitor. Average throughputs hit 169 GB/s (L4), 598 GB/s (RTX 4090), and 616 GB/s (H100). Decompression scales even higher.
- Compression Ratio: GPZ consistently outperformed all baselines, yielding ratios as much as 600% higher in challenging settings. Even when runners-up edged slightly ahead, GPZ sustained a 3x-6x speed advantage.
- Data Quality: Rate-distortion plots confirmed superior preservation of scientific features (higher PSNR at lower bitrates), and visual inspection (especially in 10x magnified views) revealed GPZ’s reconstructions were nearly indistinguishable from the originals, whereas other compressions produced visible artifacts.
Key Takeaways & Implications
GPZ sets a new gold standard for real-time, large-scale particle data reduction on modern GPUs. Its design acknowledges the fundamental limits of generic compressors and delivers tailored solutions that exploit every ounce of GPU-parallelism and precision tuning.
For researchers and practitioners working with immense scientific datasets, GPZ offers:
- Robust error-bounded compression suited for in-situ and post-hoc analysis
- Practical throughput and ratios across consumer and HPC-class hardware
- Near-perfect reconstruction for downstream analytics, visualization, and modeling tasks
As data sizes continue to scale, solutions like GPZ will increasingly define the next era of GPU-oriented scientific computing and large-scale data management.
Check out the Paper here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.

Nikhil
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.


