
Large language models are stateless by default. Each API call starts fresh. The model forgets your last message once the […]
Category: Software Engineering
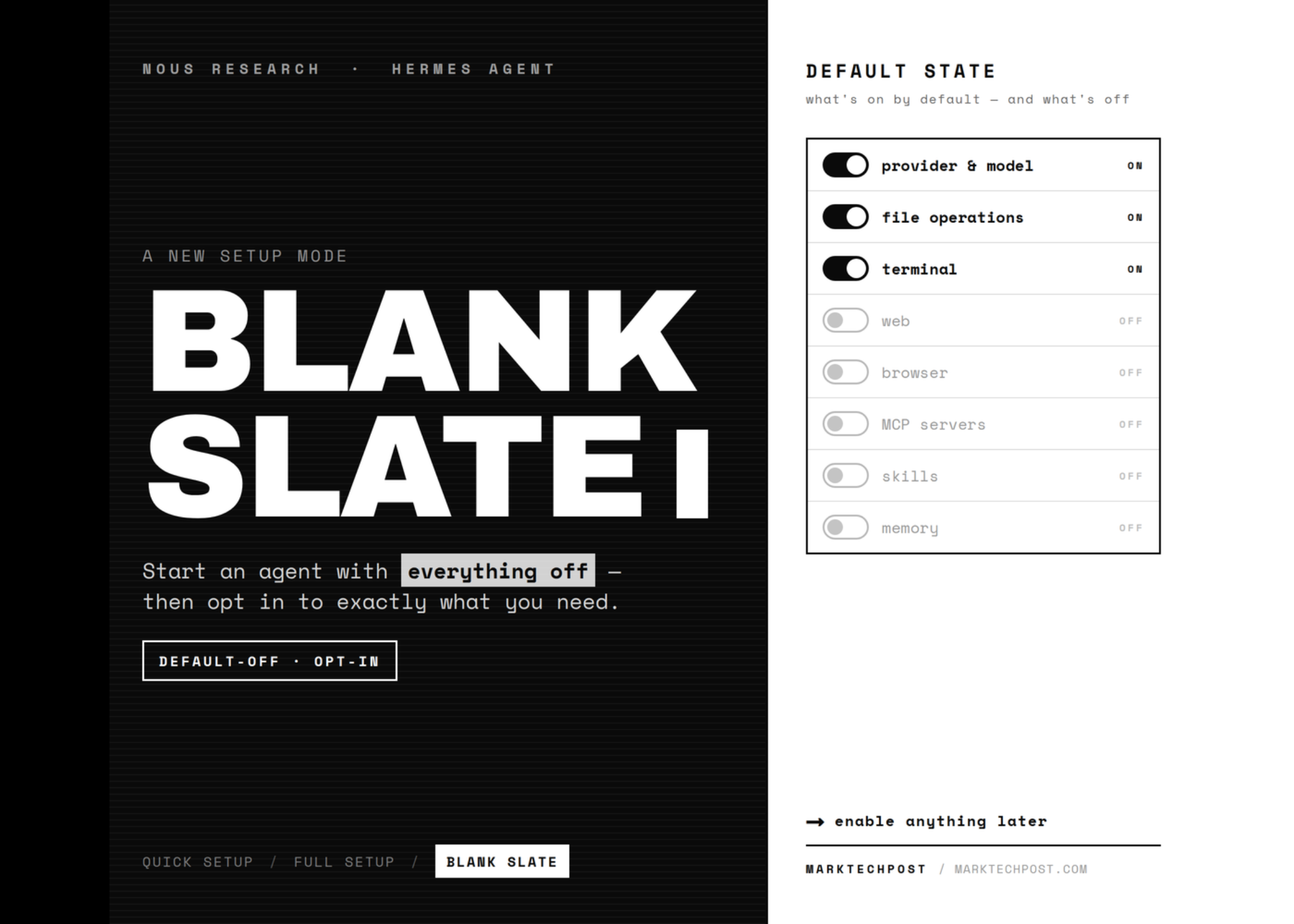
Nous Research Updates Hermes Agent With a Blank Slate Mode That Pins Toolsets via platform_toolsets.cli and disabled_toolsets
Nous Research has added a Blank Slate setup mode to its open-source Hermes Agent. It inverts the usual onboarding. Instead […]

Yandex Open-Sources YaFF: A Zero-Copy Wire Format for Protobuf With Near-Struct Read Speed
TLDR YaFF is Yandex’s open-source zero-copy wire format for Protobuf — Apache 2.0, currently C++, v0.1.0. The .proto file stays […]
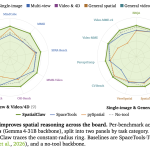
NVIDIA AI Introduce SpatialClaw: A Training-Free Agent That Treats Code as the Action Interface for Spatial Reasoning
NVIDIA Research has released SpatialClaw, a training-free framework for spatial reasoning. It targets a persistent weakness in vision-language models (VLMs). […]

Liquid AI Introduces LFM2.5-Embedding-350M and LFM2.5-ColBERT-350M: Dense Bi-Encoder and Late-Interaction Models for Fast Multilingual Search Across 11 Languages
This week, Liquid AI released two new retrieval models. They are LFM2.5-ColBERT-350M and LFM2.5-Embedding-350M. Both hold 350M parameters. Both are […]

The KV Cache Compression Race: TurboQuant vs OSCAR vs EpiCache
Long-context large language models (LLMs) face a memory bottleneck that has nothing to do with model weights. During decoding, transformers […]

Vercel Releases Eve: An Open-Source AI Agent Framework Where Each Agent is a Directory of Files Mapped to Capabilities
Vercel has released eve, an open-source framework for building, running, and scaling agents. The project is published as the npm […]
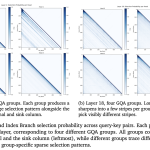
MiniMax Sparse Attention (MSA): a Two-Branch Block-Sparse Attention Trained on a 109B-Parameter MoE With a 3T-Token Budget
MiniMax released MSA (MiniMax Sparse Attention), a sparse attention method built directly on Grouped Query Attention (GQA). It targets one […]
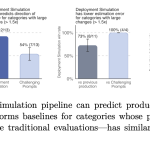
OpenAI’s Deployment Simulation Extends Pre-Deployment Risk Assessment to Agentic Coding Through Simulated Tool Calls
OpenAI published a new pre-deployment safety method called Deployment Simulation. The idea is direct. Before a model ships, simulate its […]
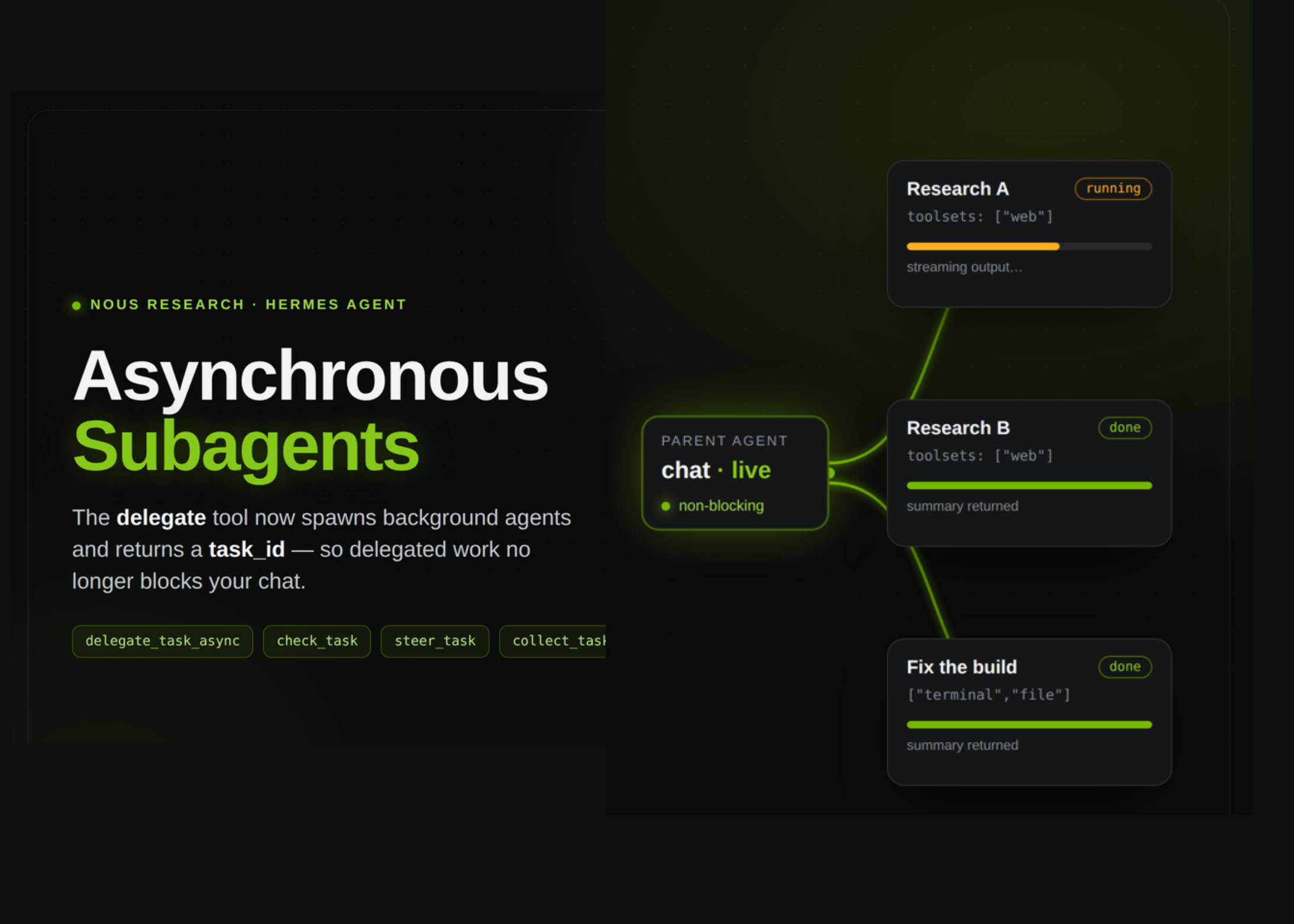
Hermes Agent Adds Asynchronous Subagents, So Delegated Work No Longer Blocks the Parent Chat
Nous Research has shipped a change to Hermes Agent. Its delegate tool can now run subagents asynchronously. Per the announcement, […]