
The Challenge of Designing General-Purpose Vision Encoders As AI systems grow increasingly multimodal, the role of visual perception models becomes […]
Category: Computer Vision

Do We Still Need Complex Vision-Language Pipelines? Researchers from ByteDance and WHU Introduce Pixel-SAIL—A Single Transformer Model for Pixel-Level Understanding That Outperforms 7B MLLMs
MLLMs have recently advanced in handling fine-grained, pixel-level visual understanding, thereby expanding their applications to tasks such as precise region-based […]
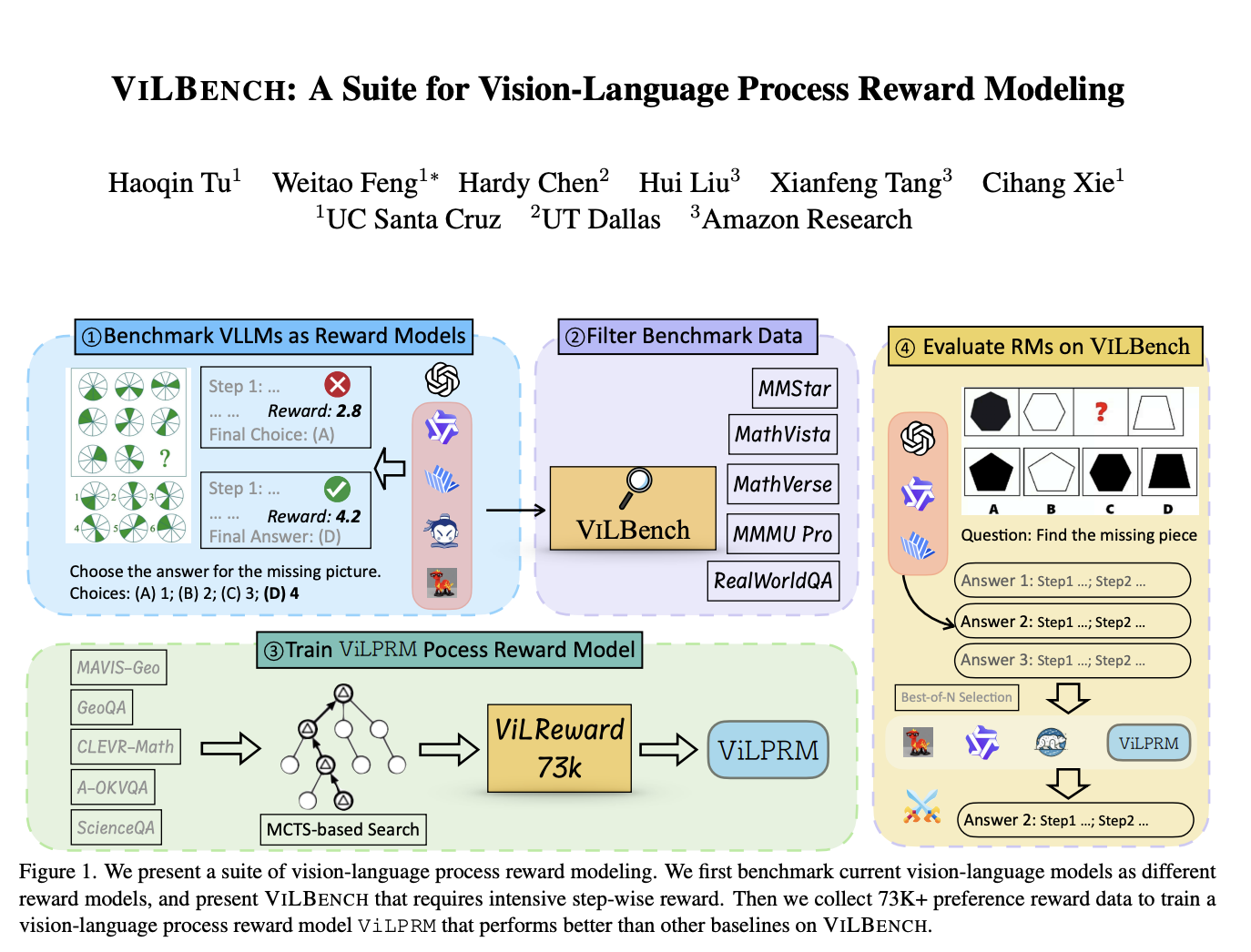
Advancing Vision-Language Reward Models: Challenges, Benchmarks, and the Role of Process-Supervised Learning
Process-supervised reward models (PRMs) offer fine-grained, step-wise feedback on model responses, aiding in selecting effective reasoning paths for complex tasks. […]

VideoMind: A Role-Based Agent for Temporal-Grounded Video Understanding
LLMs have shown impressive capabilities in reasoning tasks like Chain-of-Thought (CoT), enhancing accuracy and interpretability in complex problem-solving. While researchers […]

Meta Reality Labs Research Introduces Sonata: Advancing Self-Supervised Representation Learning for 3D Point Clouds
3D self-supervised learning (SSL) has faced persistent challenges in developing semantically meaningful point representations suitable for diverse applications with minimal […]

TokenBridge: Bridging The Gap Between Continuous and Discrete Token Representations In Visual Generation
Autoregressive visual generation models have emerged as a groundbreaking approach to image synthesis, drawing inspiration from language model token prediction […]

Vision-R1: Redefining Reinforcement Learning for Large Vision-Language Models
Large Vision-Language Models (LVLMs) have made significant strides in recent years, yet several key limitations persist. One major challenge is […]
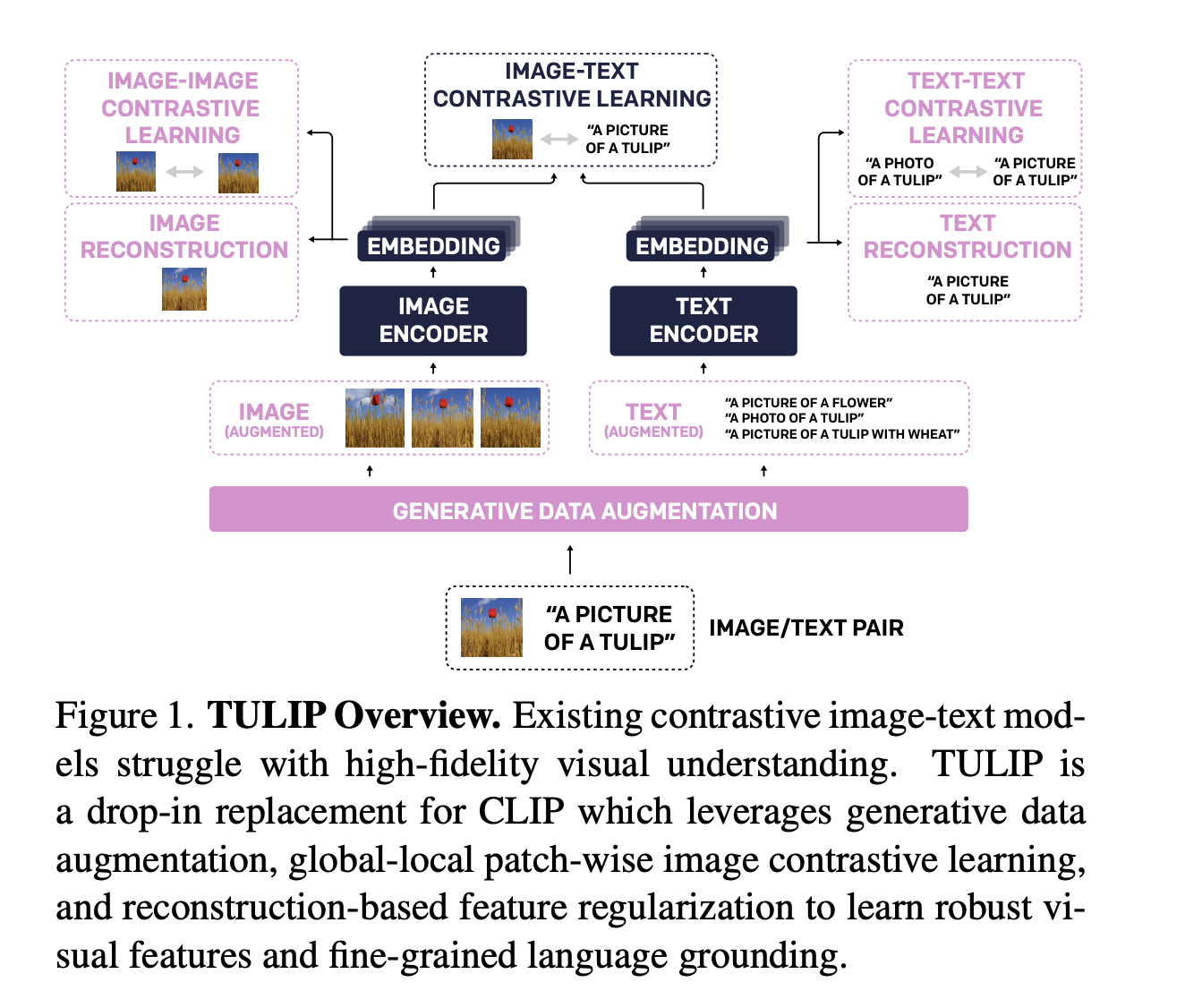
This AI Paper from UC Berkeley Introduces TULIP: A Unified Contrastive Learning Model for High-Fidelity Vision and Language Understanding
Recent advancements in artificial intelligence have significantly improved how machines learn to associate visual content with language. Contrastive learning models […]

IBM and Hugging Face Researchers Release SmolDocling: A 256M Open-Source Vision Language Model for Complete Document OCR
Converting complex documents into structured data has long posed significant challenges in the field of computer science. Traditional approaches, involving […]
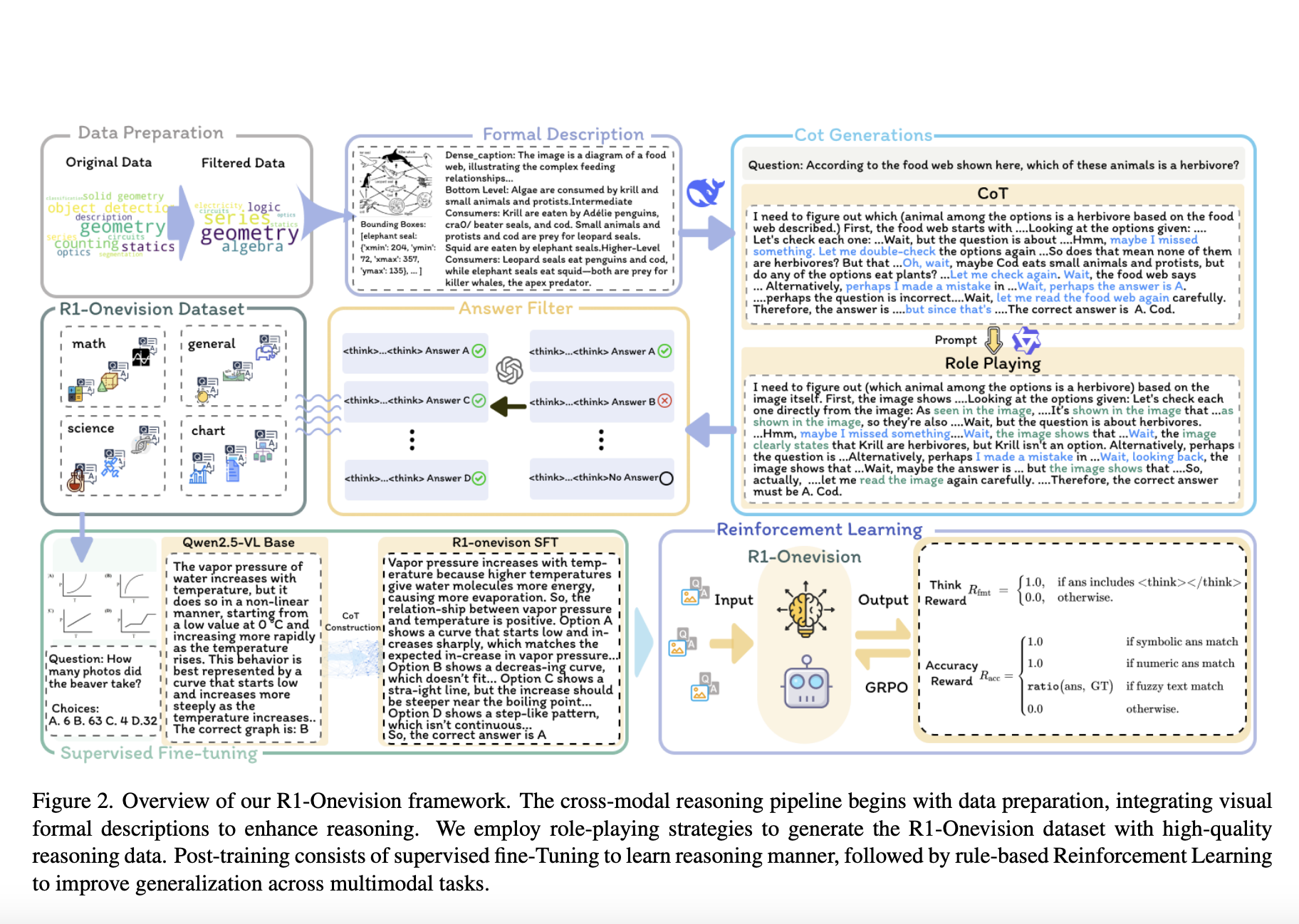
This AI Paper Introduces R1-Onevision: A Cross-Modal Formalization Model for Advancing Multimodal Reasoning and Structured Visual Interpretation
Multimodal reasoning is an evolving field that integrates visual and textual data to enhance machine intelligence. Traditional artificial intelligence models […]