
The core idea of Multimodal Large Language Models (MLLMs) is to create models that can combine the richness of visual […]
Category: Computer Vision

Researchers Introduce MMLONGBENCH: A Comprehensive Benchmark for Long-Context Vision-Language Models
Recent advances in long-context (LC) modeling have unlocked new capabilities for LLMs and large vision-language models (LVLMs). Long-context vision–language models […]

Google Researchers Introduce LightLab: A Diffusion-Based AI Method for Physically Plausible, Fine-Grained Light Control in Single Images
Manipulating lighting conditions in images post-capture is challenging. Traditional approaches rely on 3D graphics methods that reconstruct scene geometry and […]

Salesforce AI Releases BLIP3-o: A Fully Open-Source Unified Multimodal Model Built with CLIP Embeddings and Flow Matching for Image Understanding and Generation
Multimodal modeling focuses on building systems to understand and generate content across visual and textual formats. These models are designed […]

DanceGRPO: A Unified Framework for Reinforcement Learning in Visual Generation Across Multiple Paradigms and Tasks
Recent advances in generative models, especially diffusion models and rectified flows, have revolutionized visual content creation with enhanced output quality […]

ByteDance Introduces Seed1.5-VL: A Vision-Language Foundation Model Designed to Advance General-Purpose Multimodal Understanding and Reasoning
VLMs have become central to building general-purpose AI systems capable of understanding and interacting in digital and real-world settings. By […]

Multimodal AI Needs More Than Modality Support: Researchers Propose General-Level and General-Bench to Evaluate True Synergy in Generalist Models
Artificial intelligence has grown beyond language-focused systems, evolving into models capable of processing multiple input types, such as text, images, […]

Offline Video-LLMs Can Now Understand Real-Time Streams: Apple Researchers Introduce StreamBridge to Enable Multi-Turn and Proactive Video Understanding
Video-LLMs process whole pre-recorded videos at once. However, applications like robotics and autonomous driving need causal perception and interpretation of […]
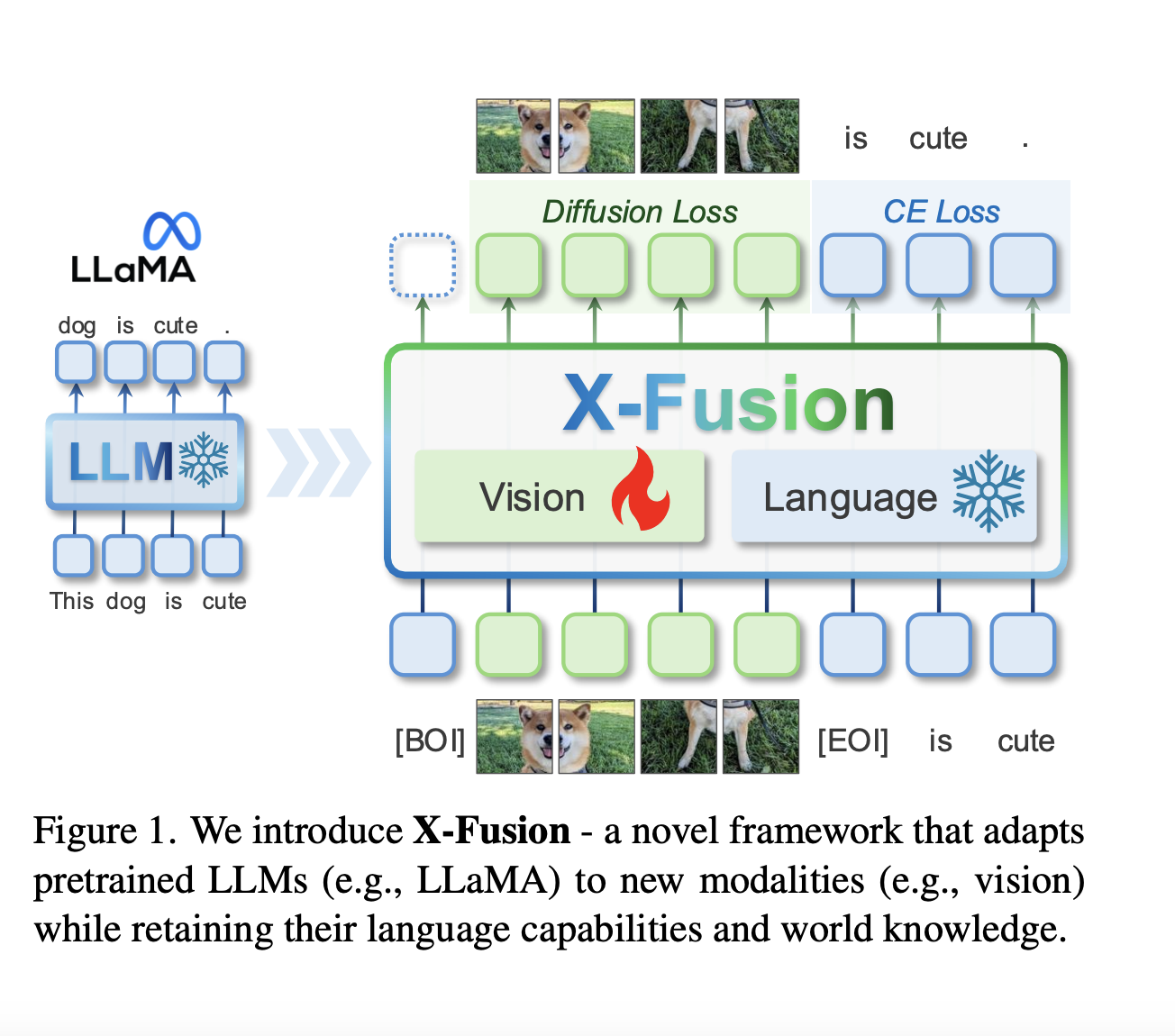
Multimodal LLMs Without Compromise: Researchers from UCLA, UW–Madison, and Adobe Introduce X-Fusion to Add Vision to Frozen Language Models Without Losing Language Capabilities
LLMs have made significant strides in language-related tasks such as conversational AI, reasoning, and code generation. However, human communication extends […]

Subject-Driven Image Evaluation Gets Simpler: Google Researchers Introduce REFVNLI to Jointly Score Textual Alignment and Subject Consistency Without Costly APIs
Text-to-image (T2I) generation has evolved to include subject-driven approaches, which enhance standard T2I models by incorporating reference images alongside text […]