
Vision Language Models (VLMs) allow both text inputs and visual understanding. However, image resolution is crucial for VLM performance for […]
Category: Computer Vision
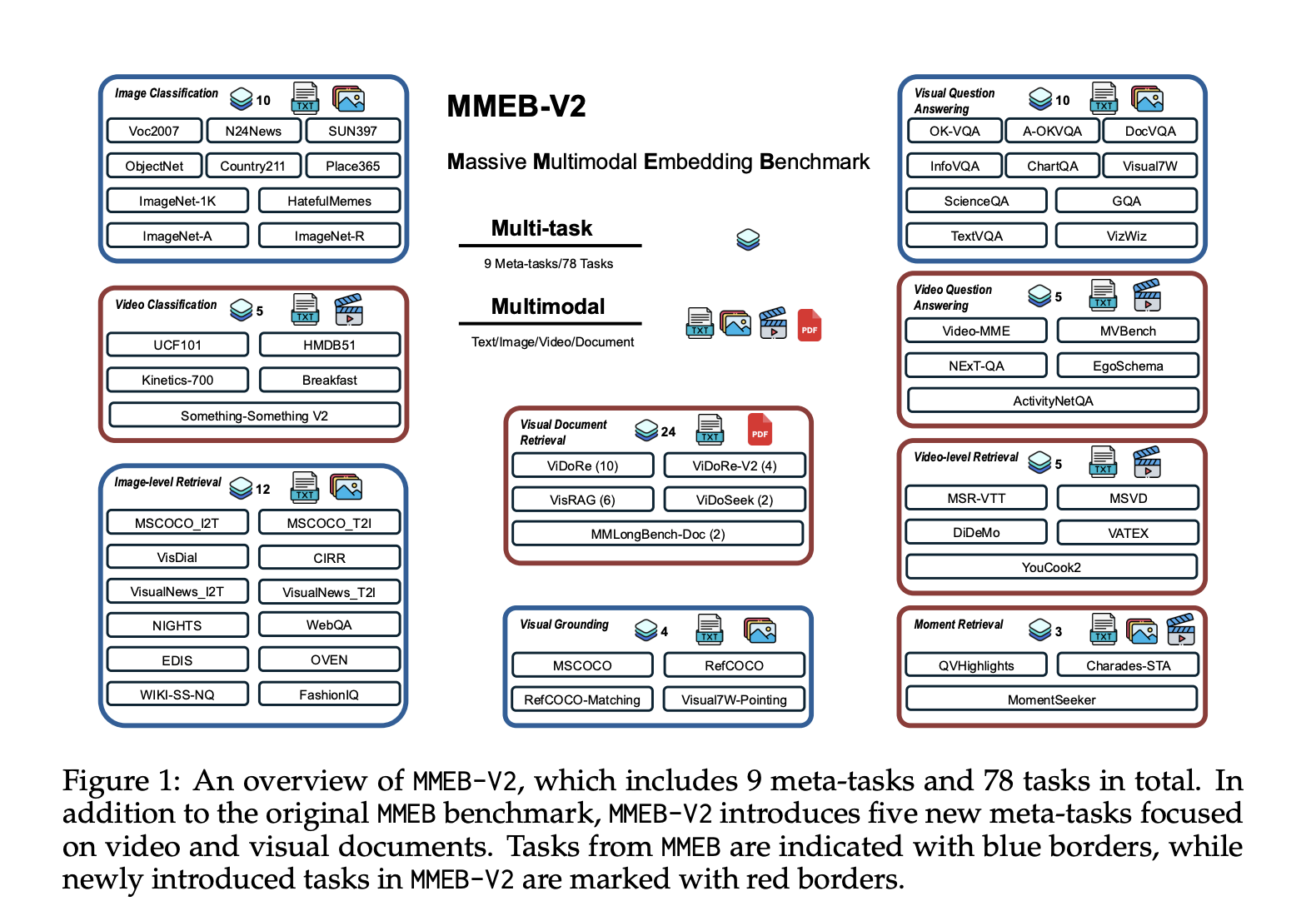
VLM2Vec-V2: A Unified Computer Vision Framework for Multimodal Embedding Learning Across Images, Videos, and Visual Documents
Embedding models act as bridges between different data modalities by encoding diverse multimodal information into a shared dense representation space. […]

RoboBrain 2.0: The Next-Generation Vision-Language Model Unifying Embodied AI for Advanced Robotics
Advancements in artificial intelligence are rapidly closing the gap between digital reasoning and real-world interaction. At the forefront of this […]

GPT-4o Understands Text, But Does It See Clearly? A Benchmarking Study of MFMs on Vision Tasks
Multimodal foundation models (MFMs) like GPT-4o, Gemini, and Claude have shown rapid progress recently, especially in public demos. While their […]

This AI Paper from Alibaba Introduces Lumos-1: A Unified Autoregressive Video Generator Leveraging MM-RoPE and AR-DF for Efficient Spatiotemporal Modeling
Autoregressive video generation is a rapidly evolving research domain. It focuses on the synthesis of videos frame-by-frame using learned patterns […]

GLM-4.1V-Thinking: Advancing General-Purpose Multimodal Understanding and Reasoning
Vision-language models (VLMs) play a crucial role in today’s intelligent systems by enabling a detailed understanding of visual content. The […]
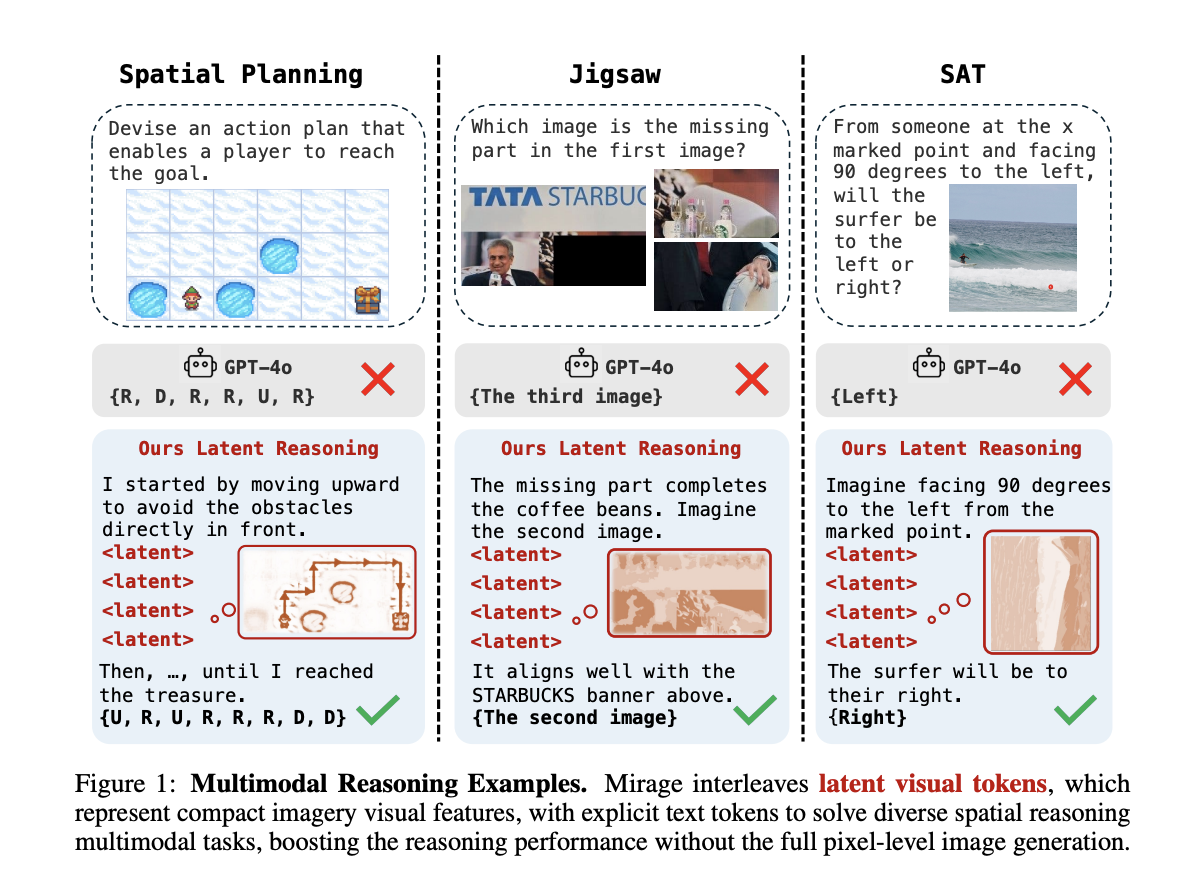
Mirage: Multimodal Reasoning in VLMs Without Rendering Images
While VLMs are strong at understanding both text and images, they often rely solely on text when reasoning, limiting their […]

JarvisArt: A Human-in-the-Loop Multimodal Agent for Region-Specific and Global Photo Editing
Bridging the Gap Between Artistic Intent and Technical Execution Photo retouching is a core aspect of digital photography, enabling users […]

This AI Paper Introduces MMSearch-R1: A Reinforcement Learning Framework for Efficient On-Demand Multimodal Search in LMMs
Large multimodal models (LMMs) enable systems to interpret images, answer visual questions, and retrieve factual information by combining multiple modalities. […]

This AI Paper Introduces PEVA: A Whole-Body Conditioned Diffusion Model for Predicting Egocentric Video from Human Motion
Understanding the Link Between Body Movement and Visual Perception The study of human visual perception through egocentric views is crucial […]