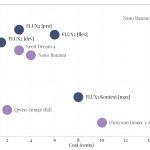
Black Forest Labs has released FLUX.2, its second generation image generation and editing system. FLUX.2 targets real world creative workflows […]
Category: Computer Vision
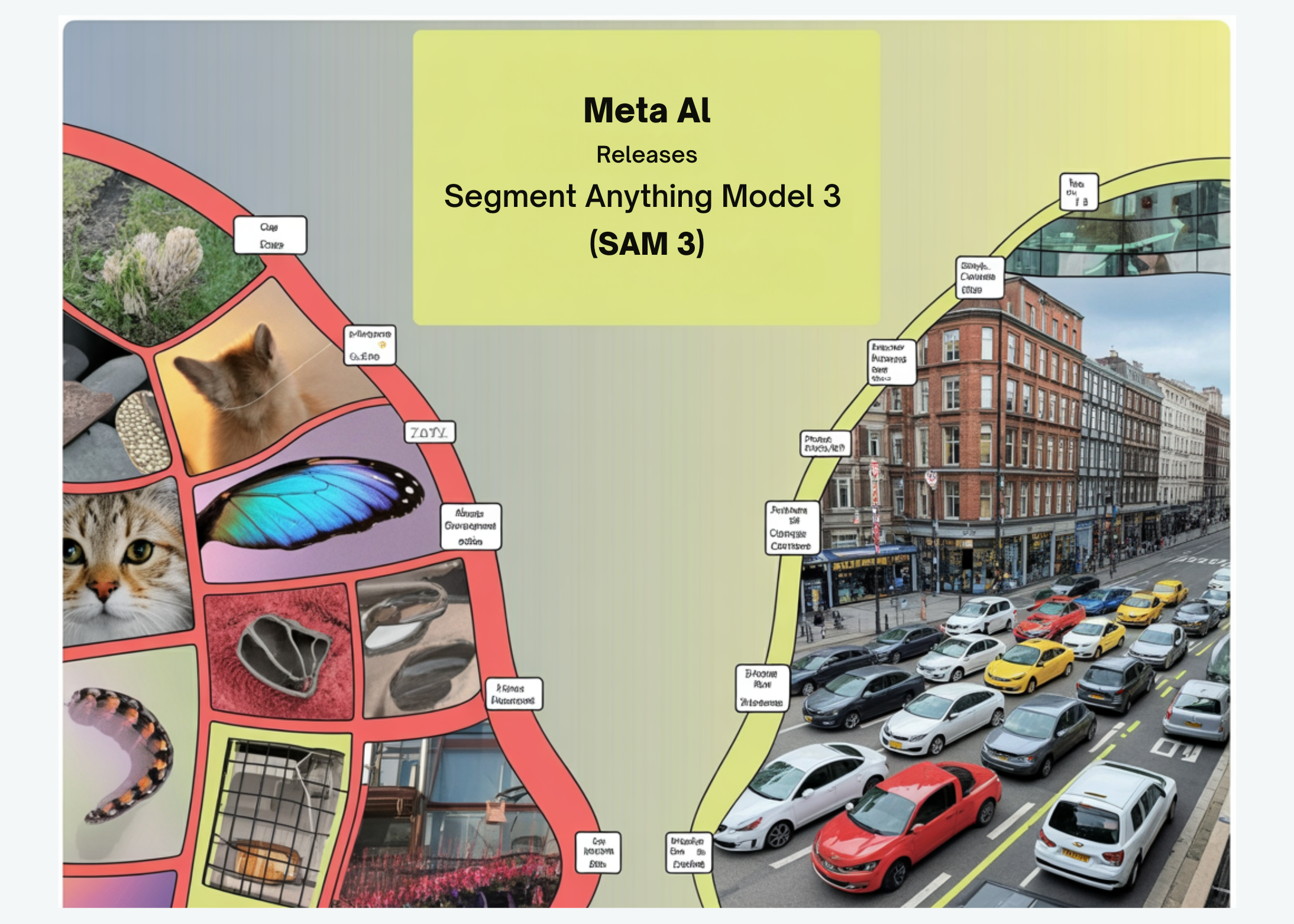
Meta AI Releases Segment Anything Model 3 (SAM 3) for Promptable Concept Segmentation in Images and Videos
How do you reliably find, segment and track every instance of any concept across large image and video collections using […]

Why Spatial Supersensing is Emerging as the Core Capability for Multimodal AI Systems?
Even strong ‘long-context’ AI models fail badly when they must track objects and counts over long, messy video streams, so […]

Zhipu AI Releases ‘Glyph’: An AI Framework for Scaling the Context Length through Visual-Text Compression
Can we render long texts as images and use a VLM to achieve 3–4× token compression, preserving accuracy while scaling […]
Salesforce AI Research Introduces WALT (Web Agents that Learn Tools): Enabling LLM agents to Automatically Discover Reusable Tools from Any Website
A team of Salesforce AI researchers introduced WALT (Web Agents that Learn Tools), a framework that reverse-engineers latent website functionality […]

UltraCUA: A Foundation Computer-Use Agents Model that Bridges the Gap between General-Purpose GUI Agents and Specialized API-based Agents
Computer-use agents have been limited to primitives. They click, they type, they scroll. Long action chains amplify grounding errors and […]

Google AI Introduces VISTA: A Test Time Self Improving Agent for Text to Video Generation
TLDR: VISTA is a multi agent framework that improves text to video generation during inference, it plans structured prompts as […]

NVIDIA AI Open-Sources ViPE (Video Pose Engine): A Powerful and Versatile 3D Video Annotation Tool for Spatial AI
How do you create 3D datasets to train AI for Robotics without expensive traditional approaches? A team of researchers from […]
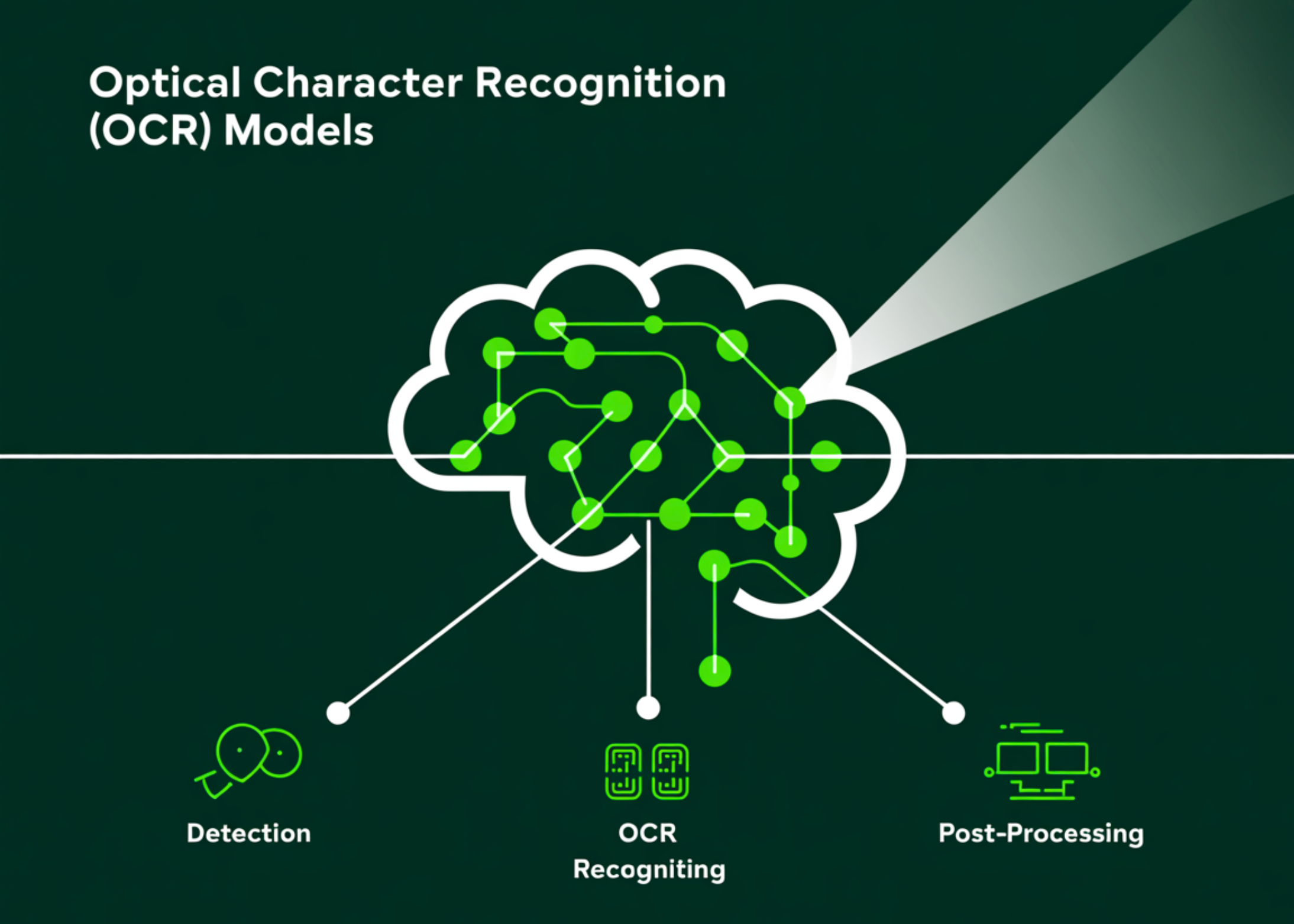
What are Optical Character Recognition (OCR) Models? Top Open-Source OCR Models
Optical Character Recognition (OCR) is the process of turning images that contain text—such as scanned pages, receipts, or photographs—into machine-readable […]
Apple Released FastVLM: A Novel Hybrid Vision Encoder which is 85x Faster and 3.4x Smaller than Comparable Sized Vision Language Models (VLMs)
Table of contents Introduction Existing VLM Architectures Apple’s FastVLM Benchmark Comparisons Conclusion Introduction Vision Language Models (VLMs) allow both text […]