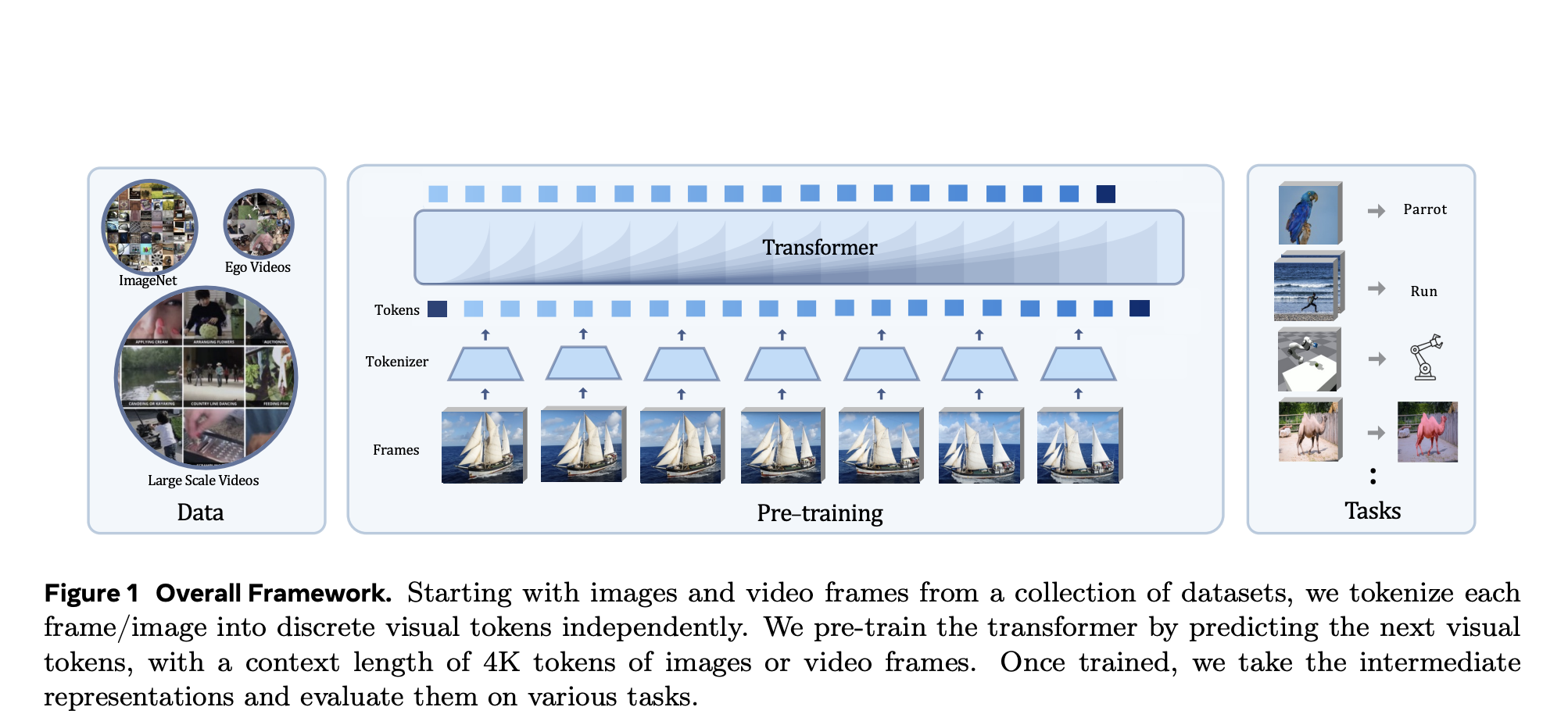
Autoregressive pre-training has proved to be revolutionary in machine learning, especially concerning sequential data processing. Predictive modeling of the following […]
Category: Computer Vision

Sa2VA: A Unified AI Framework for Dense Grounded Video and Image Understanding through SAM-2 and LLaVA Integration
Multi-modal Large Language Models (MLLMs) have revolutionized various image and video-related tasks, including visual question answering, narrative generation, and interactive […]

ProVision: A Scalable Programmatic Approach to Vision-Centric Instruction Data for Multimodal Language Models
The rise of multimodal applications has highlighted the importance of instruction data in training MLMs to handle complex image-based queries […]

Content-Adaptive Tokenizer (CAT): An Image Tokenizer that Adapts Token Count based on Image Complexity, Offering Flexible 8x, 16x, or 32x Compression
One of the major hurdles in AI-driven image modeling is the inability to account for the diversity in image content […]
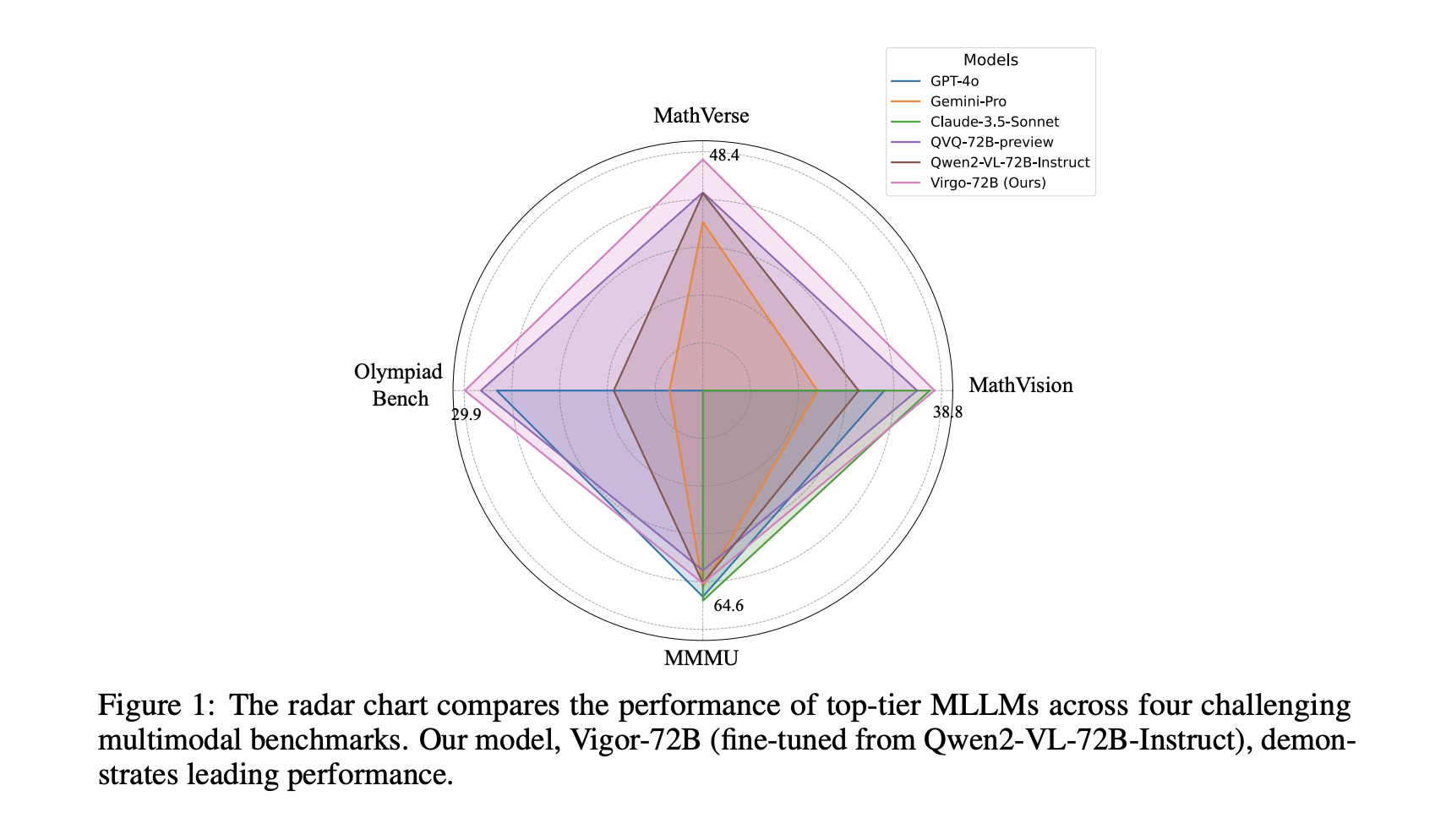
This AI Paper Introduces Virgo: A Multimodal Large Language Model for Enhanced Slow-Thinking Reasoning
Artificial intelligence research has steadily advanced toward creating systems capable of complex reasoning. Multimodal large language models (MLLMs) represent a […]
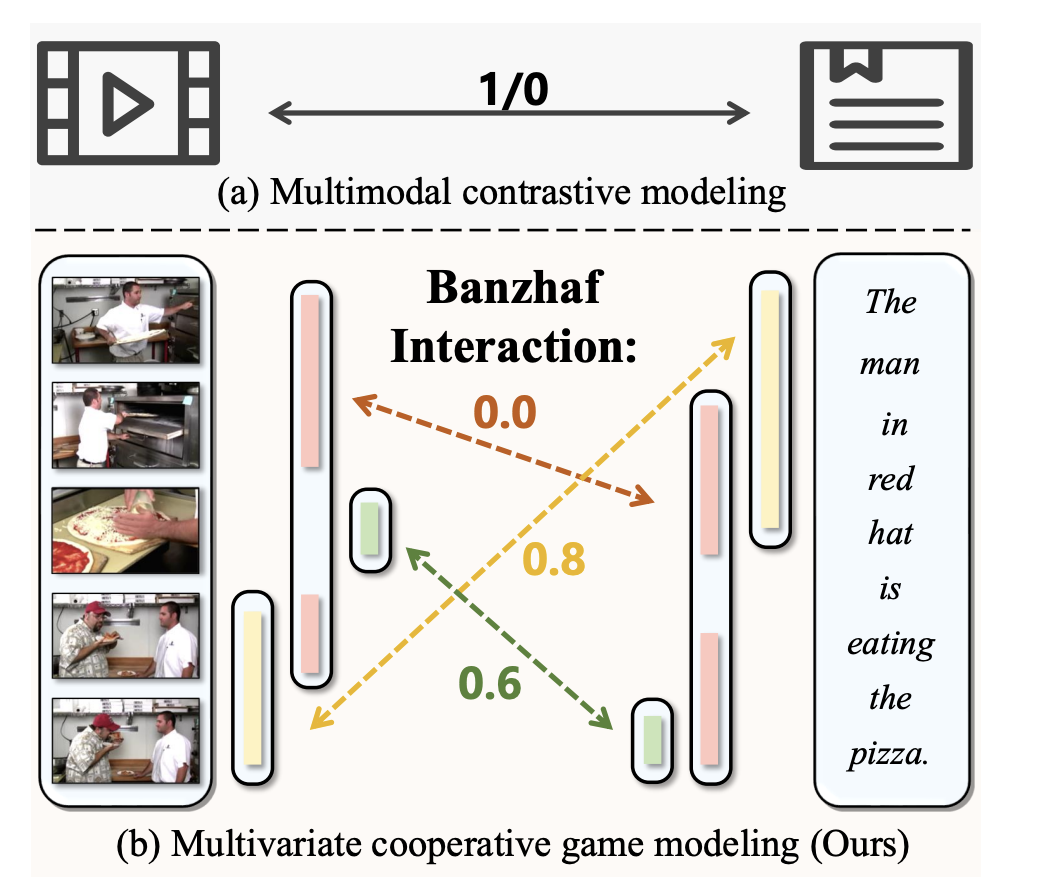
HBI V2: A Flexible AI Framework that Elevates Video-Language Learning with a Multivariate Co-Operative Game
Video-Language Representation Learning is a crucial subfield of multi-modal representation learning that focuses on the relationship between videos and their […]
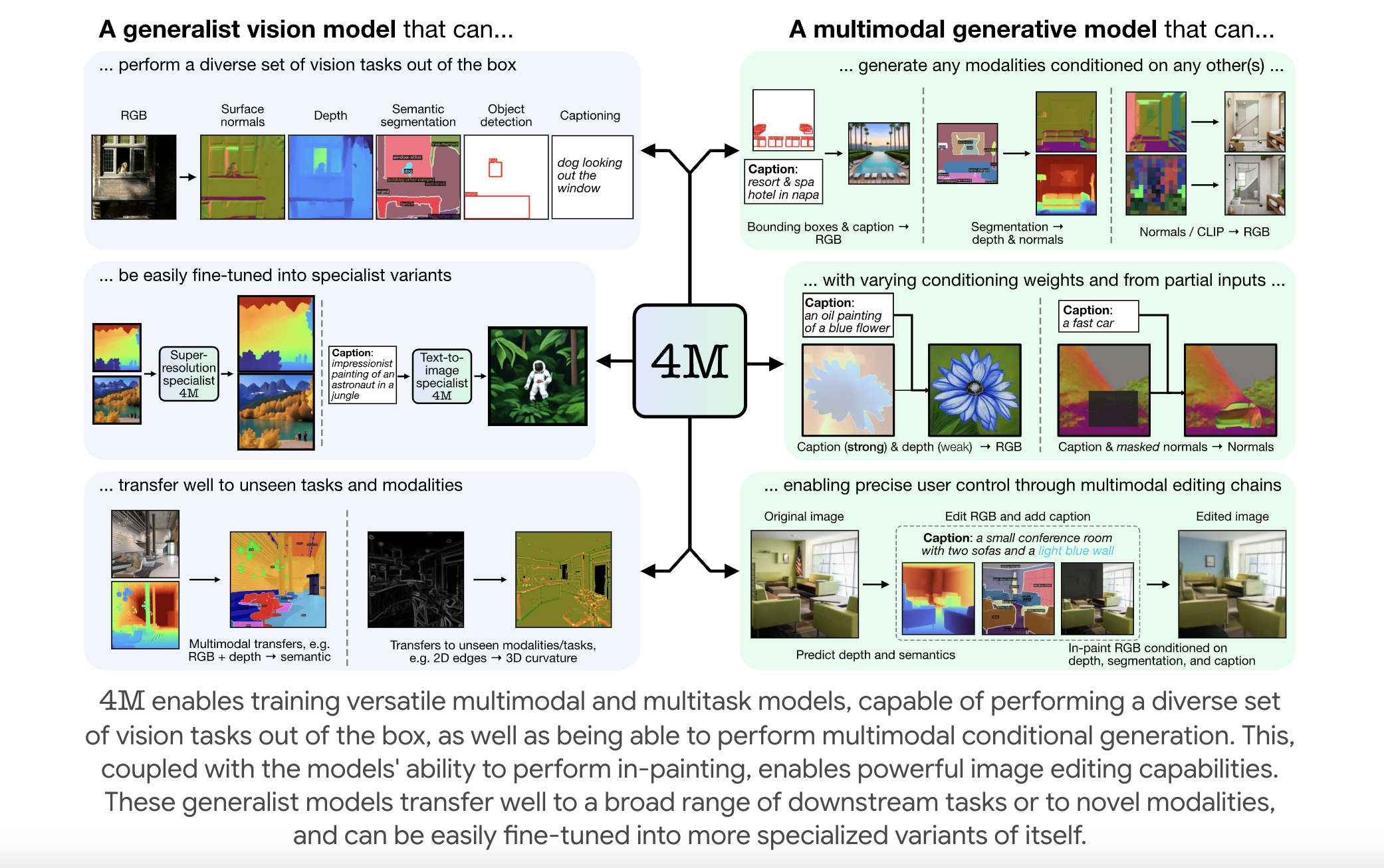
EPFL Researchers Releases 4M: An Open-Source Training Framework to Advance Multimodal AI
Multimodal foundation models are becoming increasingly relevant in artificial intelligence, enabling systems to process and integrate multiple forms of data—such […]

VITA-1.5: A Multimodal Large Language Model that Integrates Vision, Language, and Speech Through a Carefully Designed Three-Stage Training Methodology
The development of multimodal large language models (MLLMs) has brought new opportunities in artificial intelligence. However, significant challenges persist in […]
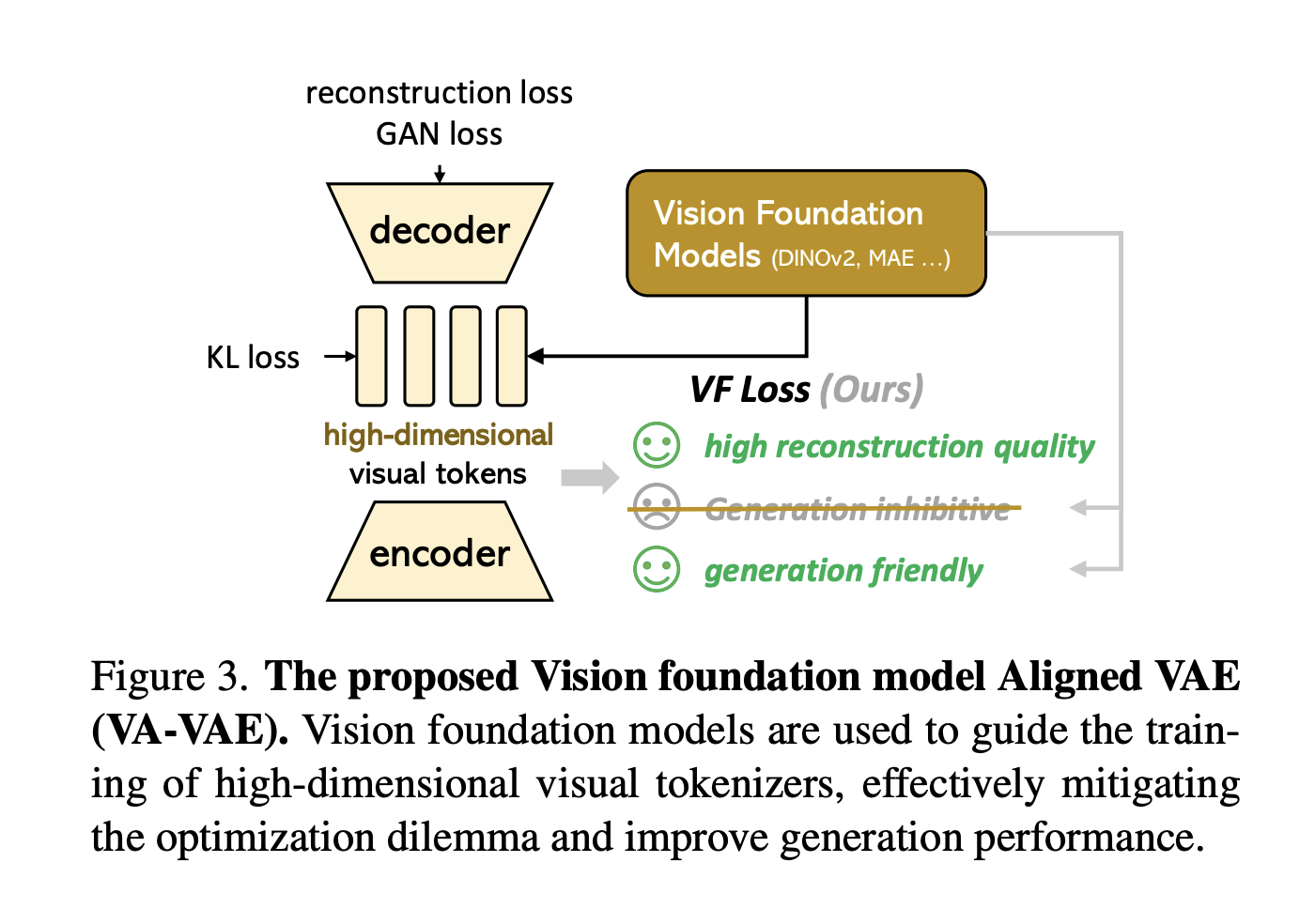
From Latent Spaces to State-of-the-Art: The Journey of LightningDiT
Latent diffusion models are advanced techniques for generating high-resolution images by compressing visual data into a latent space using visual […]
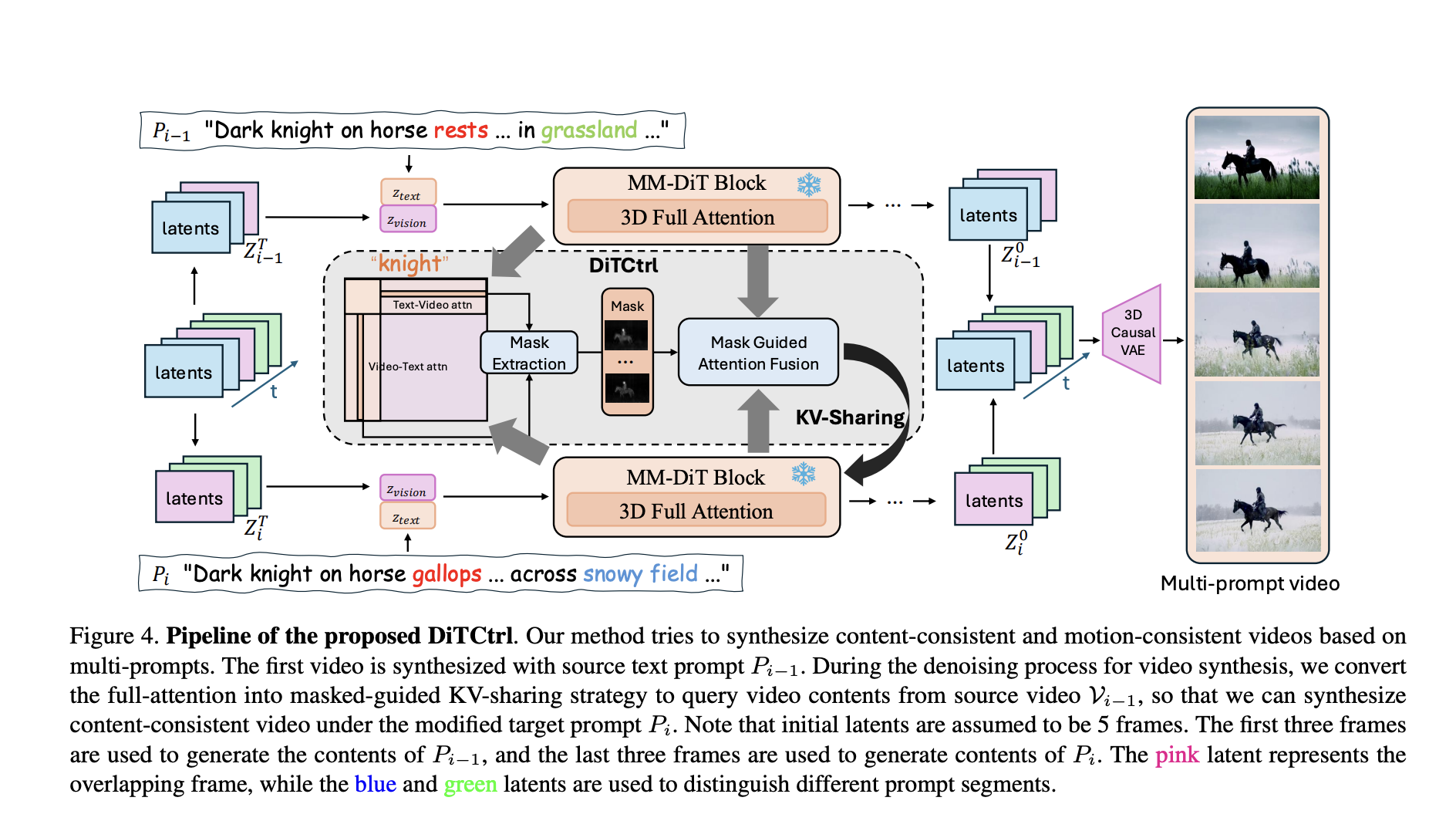
DiTCtrl: A Training-Free Multi-Prompt Video Generation Method Under MM-DiT Architectures
Generative AI has revolutionized video synthesis, producing high-quality content with minimal human intervention. Multimodal frameworks combine the strengths of generative […]