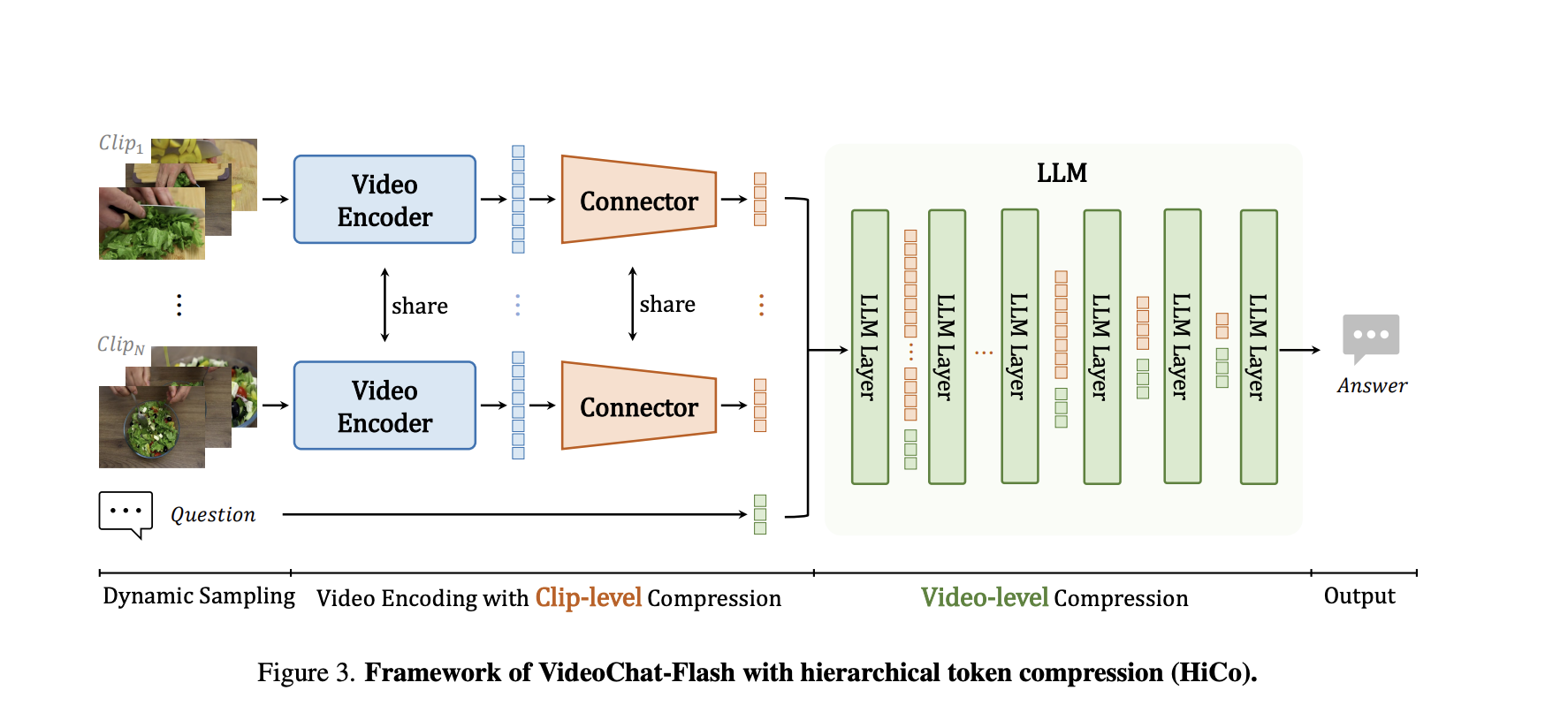
One of the most significant and advanced capabilities of a multimodal large language model is long-context video modeling, which allows […]
Category: Computer Vision

GameFactory: Leveraging Pre-trained Video Models for Creating New Game
Video diffusion models have emerged as powerful tools for video generation and physics simulation, showing promise in developing game engines. […]
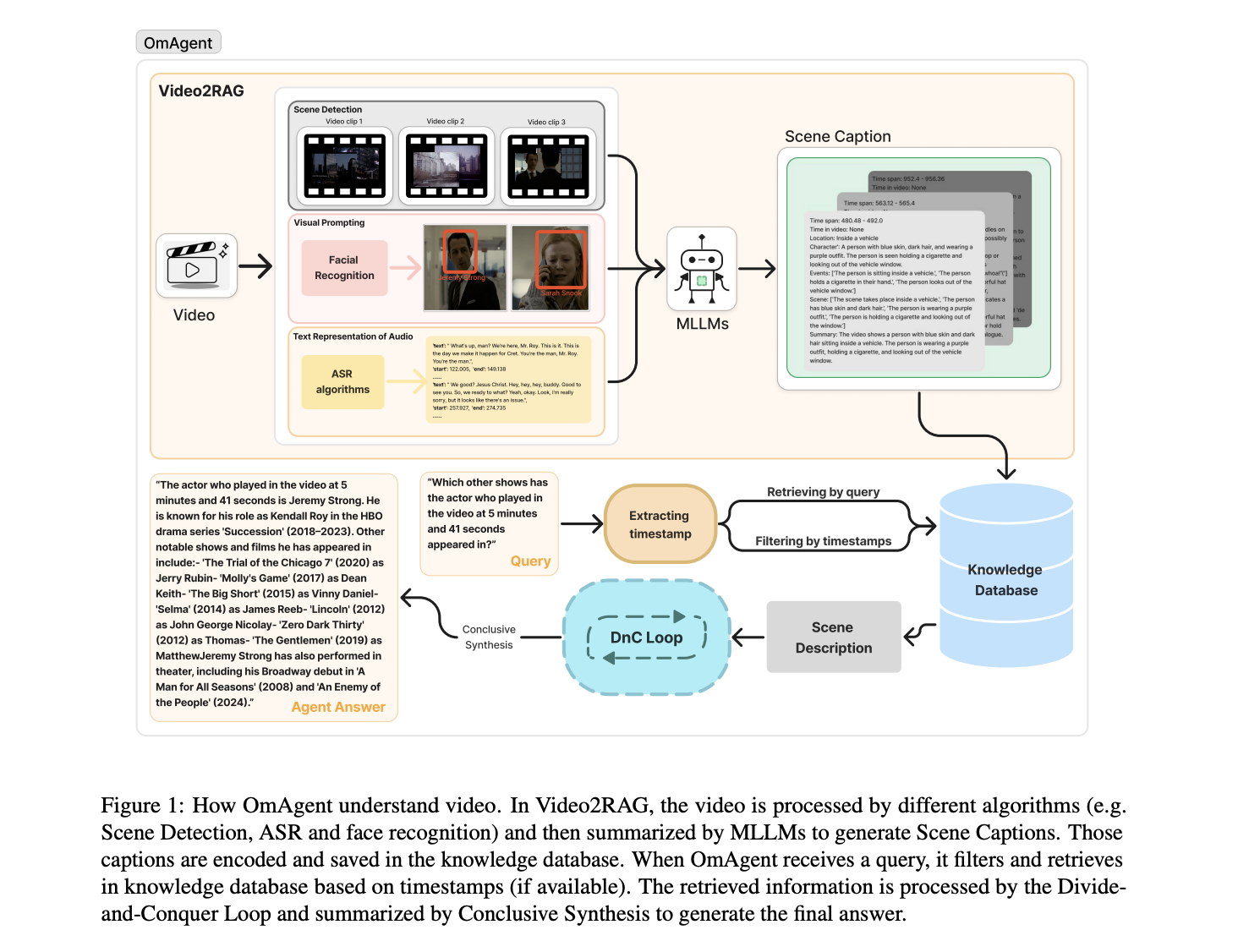
Meet OmAgent: A New Python Library for Building Multimodal Language Agents
Understanding long videos, such as 24-hour CCTV footage or full-length films, is a major challenge in video processing. Large Language […]

Purdue University Researchers Introduce ETA: A Two-Phase AI Framework for Enhancing Safety in Vision-Language Models During Inference
Vision-language models (VLMs) represent an advanced field within artificial intelligence, integrating computer vision and natural language processing to handle multimodal […]

Researchers from Meta AI and UT Austin Explored Scaling in Auto-Encoders and Introduced ViTok: A ViT-Style Auto-Encoder to Perform Exploration
Modern image and video generation methods rely heavily on tokenization to encode high-dimensional data into compact latent representations. While advancements […]
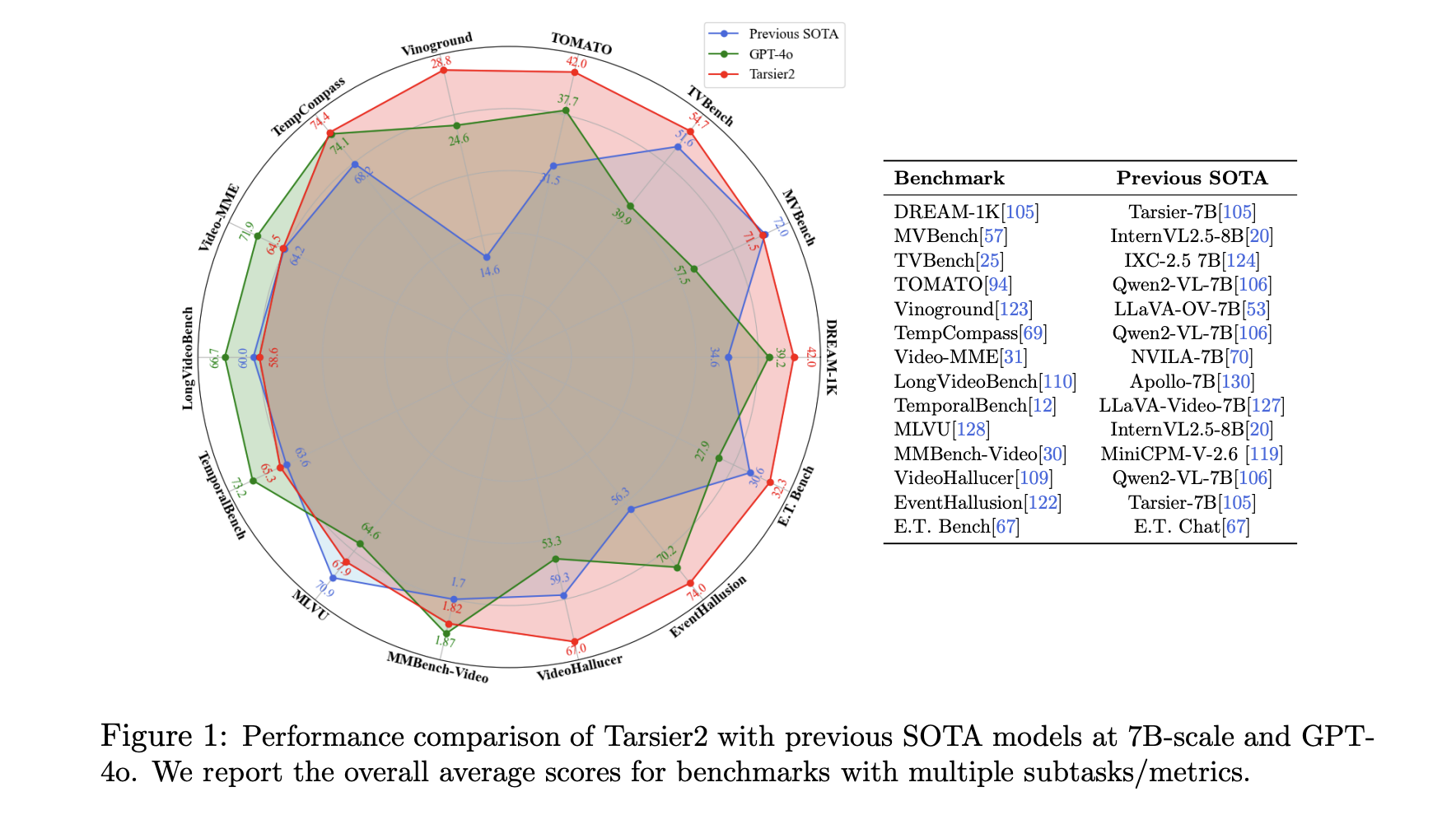
ByteDance Researchers Introduce Tarsier2: A Large Vision-Language Model (LVLM) with 7B Parameters, Designed to Address the Core Challenges of Video Understanding
Video understanding has long presented unique challenges for AI researchers. Unlike static images, videos involve intricate temporal dynamics and spatial-temporal […]

Revolutionizing Vision-Language Tasks with Sparse Attention Vectors: A Lightweight Approach to Discriminative Classification
Generative Large Multimodal Models (LMMs), such as LLaVA and Qwen-VL, excel in vision-language (VL) tasks like image captioning and visual […]

Meet VideoRAG: A Retrieval-Augmented Generation (RAG) Framework Leveraging Video Content for Enhanced Query Responses
Video-based technologies have become essential tools for information retrieval and understanding complex concepts. Videos combine visual, temporal, and contextual data, […]

Salesforce AI Introduces TACO: A New Family of Multimodal Action Models that Combine Reasoning with Real-World Actions to Solve Complex Visual Tasks
Developing effective multi-modal AI systems for real-world applications requires handling diverse tasks such as fine-grained recognition, visual grounding, reasoning, and […]

Meta AI Introduces CLUE (Constitutional MLLM JUdgE): An AI Framework Designed to Address the Shortcomings of Traditional Image Safety Systems
The rapid growth of digital platforms has brought image safety into sharp focus. Harmful imagery—ranging from explicit content to depictions […]