
Multimodal AI agents are designed to process and integrate various data types, such as images, text, and videos, to perform […]
Category: Computer Vision
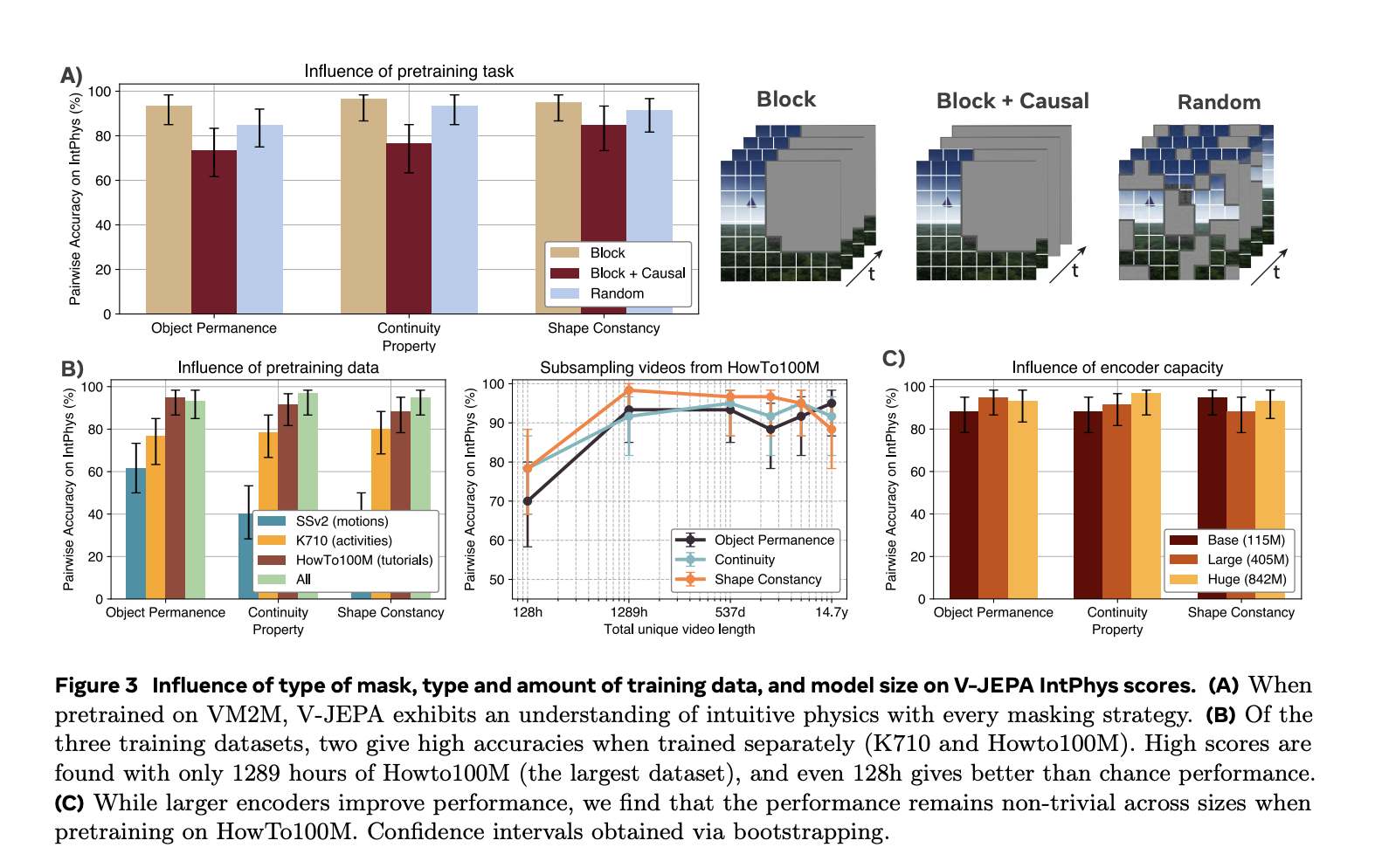
Learning Intuitive Physics: Advancing AI Through Predictive Representation Models
Humans possess an innate understanding of physics, expecting objects to behave predictably without abrupt changes in position, shape, or color. […]
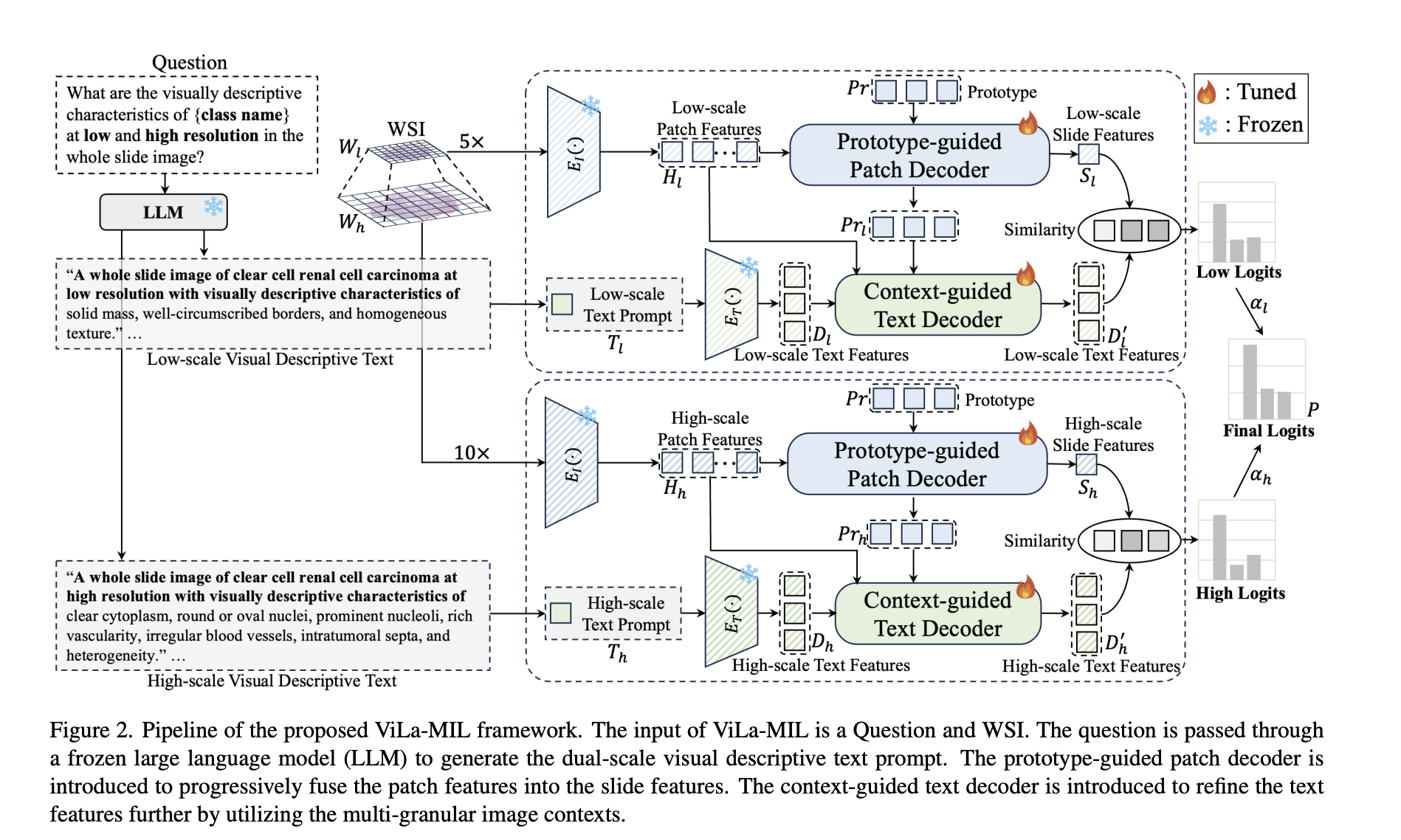
ViLa-MIL: Enhancing Whole Slide Image Classification with Dual-Scale Vision-Language Multiple Instance Learning
Whole Slide Image (WSI) classification in digital pathology presents several critical challenges due to the immense size and hierarchical nature […]

Ola: A State-of-the-Art Omni-Modal Understanding Model with Advanced Progressive Modality Alignment Strategy
Understanding different data types like text, images, videos, and audio in one model is a big challenge. Large language models […]
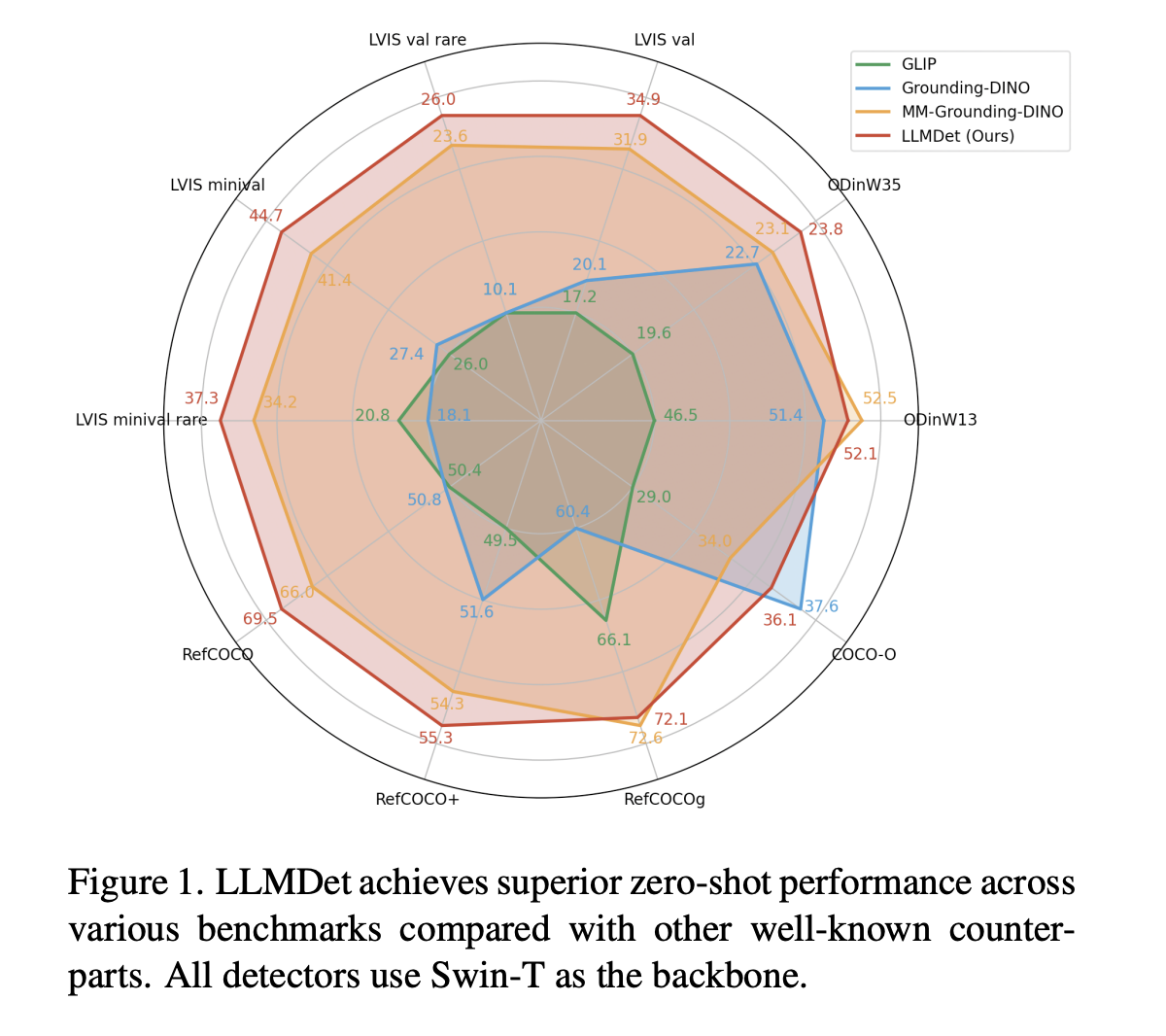
LLMDet: How Large Language Models Enhance Open-Vocabulary Object Detection
Open-vocabulary object detection (OVD) aims to detect arbitrary objects with user-provided text labels. Although recent progress has enhanced zero-shot detection […]
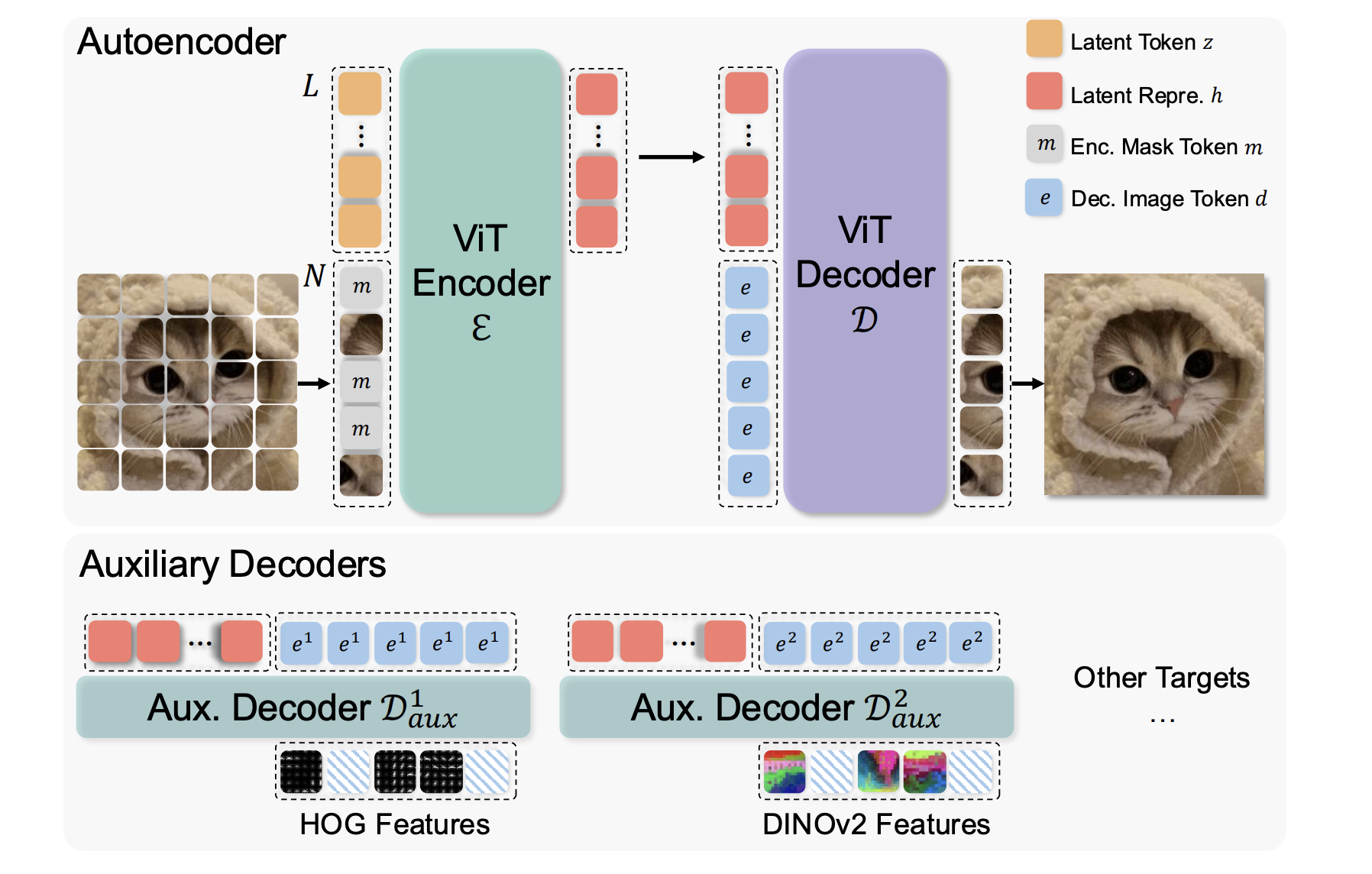
This AI Paper Introduces MAETok: A Masked Autoencoder-Based Tokenizer for Efficient Diffusion Models
Diffusion models generate images by progressively refining noise into structured representations. However, the computational cost associated with these models remains […]
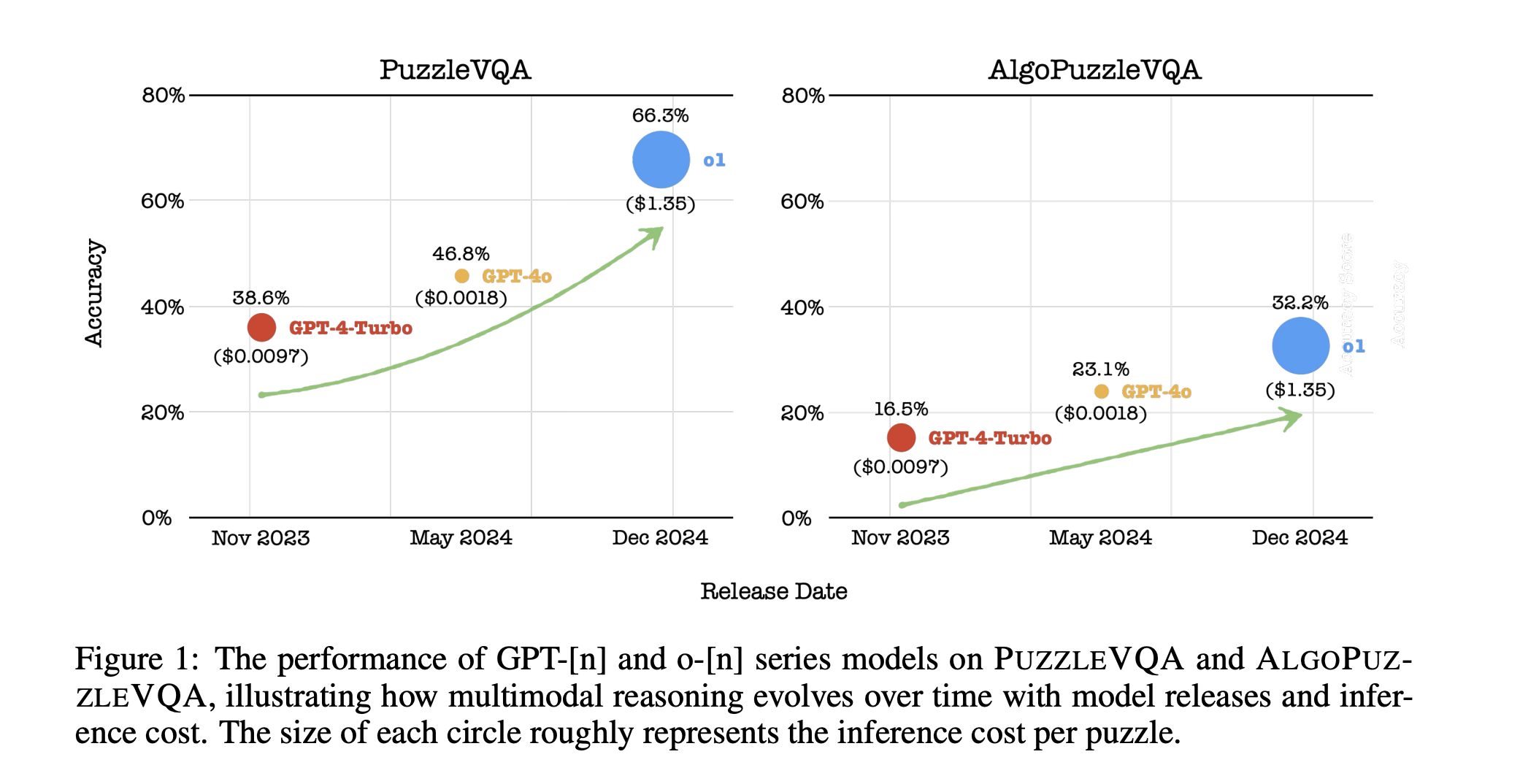
Singapore University of Technology and Design (SUTD) Explores Advancements and Challenges in Multimodal Reasoning for AI Models Through Puzzle-Based Evaluations and Algorithmic Problem-Solving Analysis
After the success of large language models (LLMs), the current research extends beyond text-based understanding to multimodal reasoning tasks. These […]
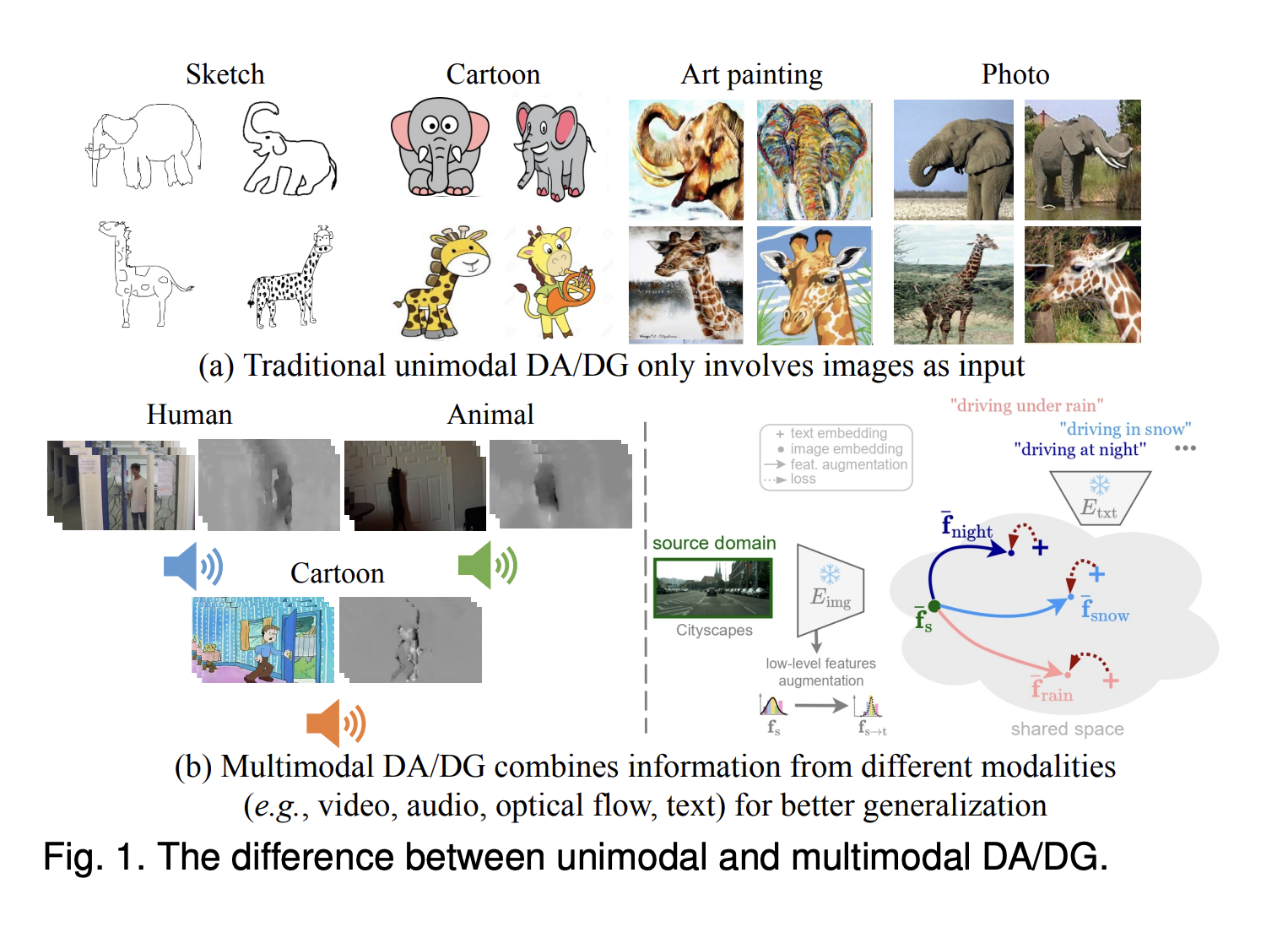
Researchers from ETH Zurich and TUM Share Everything You Need to Know About Multimodal AI Adaptation and Generalization
There is no gainsaying that artificial intelligence has developed tremendously in various fields. However, the accurate evaluation of its progress […]

Meta AI Introduces MILS: A Training-Free Multimodal AI Framework for Zero-Shot Image, Video, and Audio Understanding
Large Language Models (LLMs) are primarily designed for text-based tasks, limiting their ability to interpret and generate multimodal content such […]

Meta AI Introduces VideoJAM: A Novel AI Framework that Enhances Motion Coherence in AI-Generated Videos
Despite recent advancements, generative video models still struggle to represent motion realistically. Many existing models focus primarily on pixel-level reconstruction, […]