
Onton, a San Francisco-based search and discovery company, has released Ontology 1, a neurosymbolic model for complex, conversational, multimodal product […]
Category: Applications

AMD Releases Instella-MoE-16B-A3B: A Fully Open Mixture-of-Experts LLM With 2.8B Active Parameters Trained On Instinct GPUs
AMD released Instella-MoE-16B-A3B, a fully open Mixture-of-Experts language model trained from scratch on Instinct MI300X and MI325X GPUs. The model […]

Supabase Releases Evals: an Open Source Benchmark That Scores Claude Code, Codex and OpenCode on Real Supabase Tasks
Supabase has open sourced Supabase Evals, its benchmark and framework for testing how well AI agents build using Supabase. It […]

MiniMax Releases MiniMax H3: An Omni-Modal Video Model That Generates 15-Second 2K Clips With Native Stereo Audio
MiniMax releases MiniMax H3, a general-purpose multimodal generation model. MiniMax H3 is not a text-to-video model with add-ons. MiniMax describes […]

DeepSeek Upgrades DeepSeek-V4-Flash-0731 with Major Agentic and Coding Gains
DeepSeek published DeepSeek-V4-Flash-0731 on Hugging Face and moved the official V4-Flash API into public beta on July 31, 2026. The […]
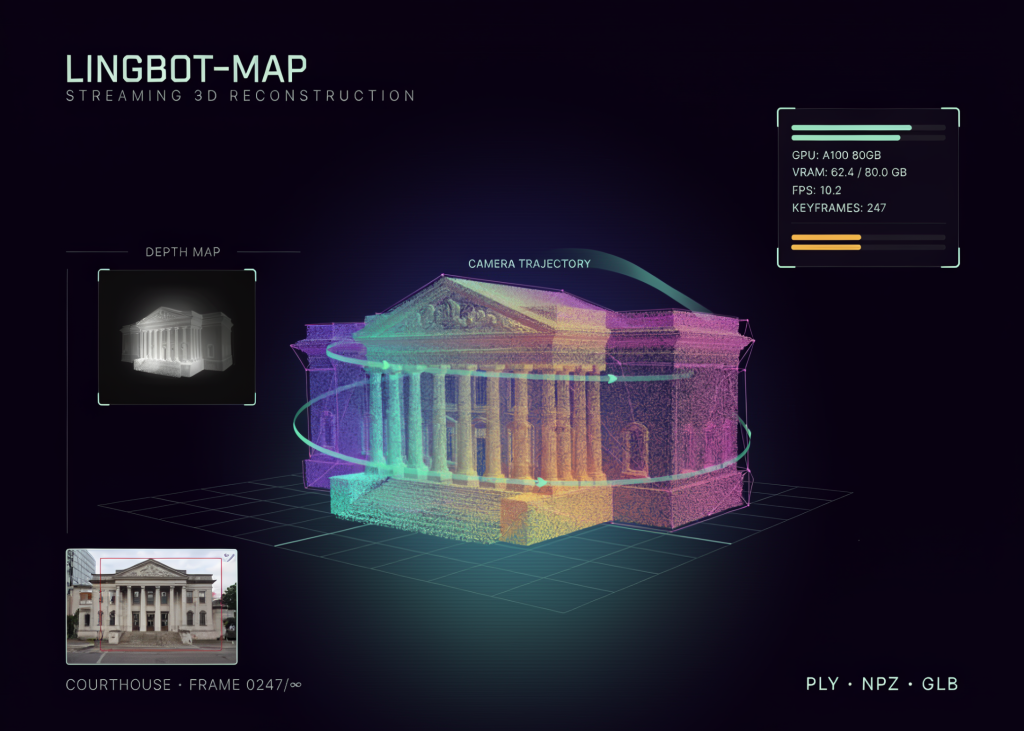
LingBot-Map Tutorial: GPU-Aware Inference and Point Cloud Export
In this tutorial, we implement an end-to-end streaming 3D reconstruction pipeline with LingBot-Map. We begin by configuring the input source, […]
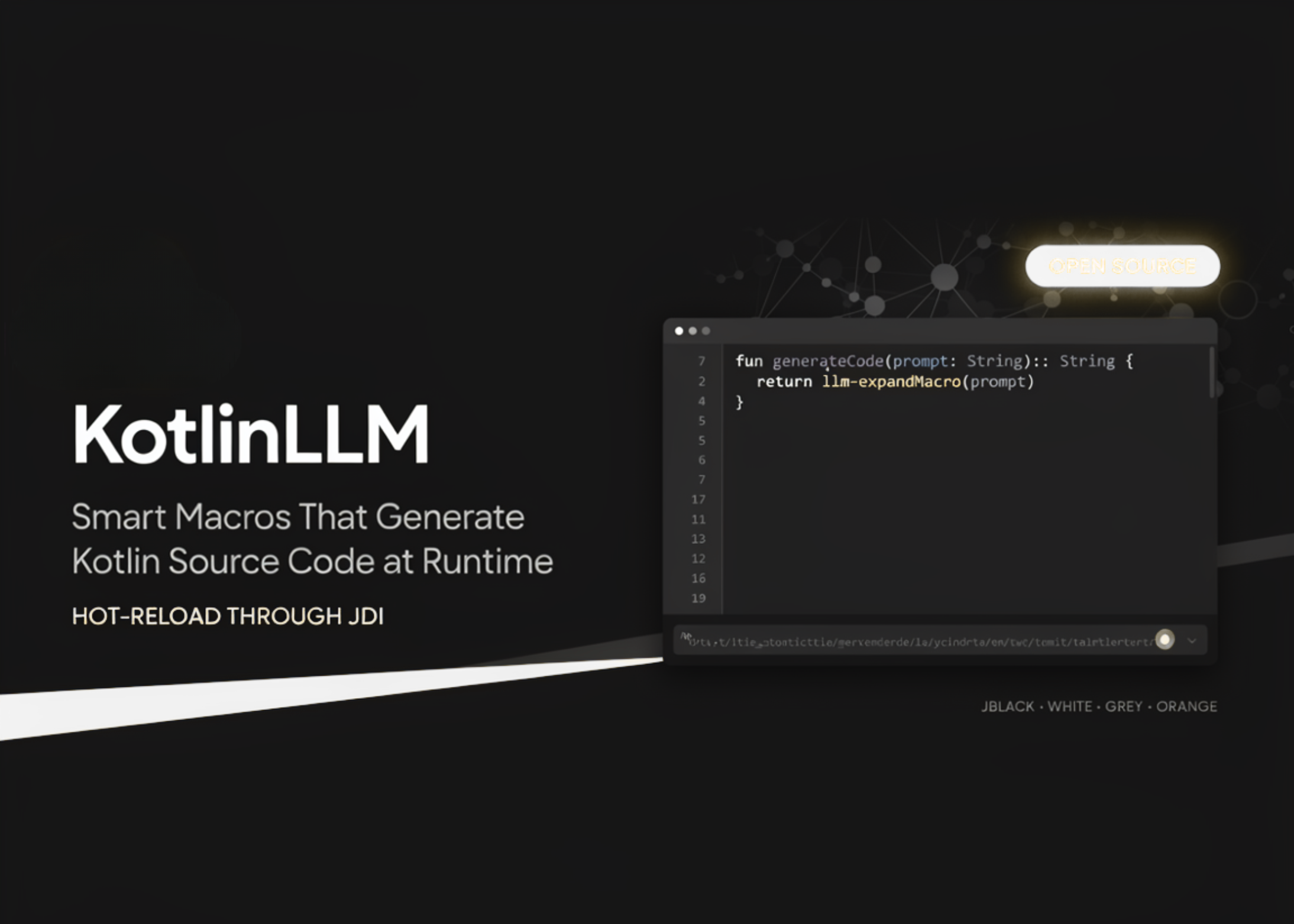
JetBrains Open-Sources KotlinLLM: Smart Macros That Generate Kotlin Source Code at Runtime and Hot-Reload It Through JDI
JetBrains Research Open-Sources KotlinLLM. KotlinLLM is an IntelliJ IDEA plugin for Kotlin/JVM projects that adds a language feature called Smart […]

Google DeepMind Ships Three Physical AI Models For Whole Body Control, Dexterity And Multi Robot Collaboration
Google DeepMind has released Gemini Robotics 2, the intelligence layer for its next generation of robots. The release moves the […]
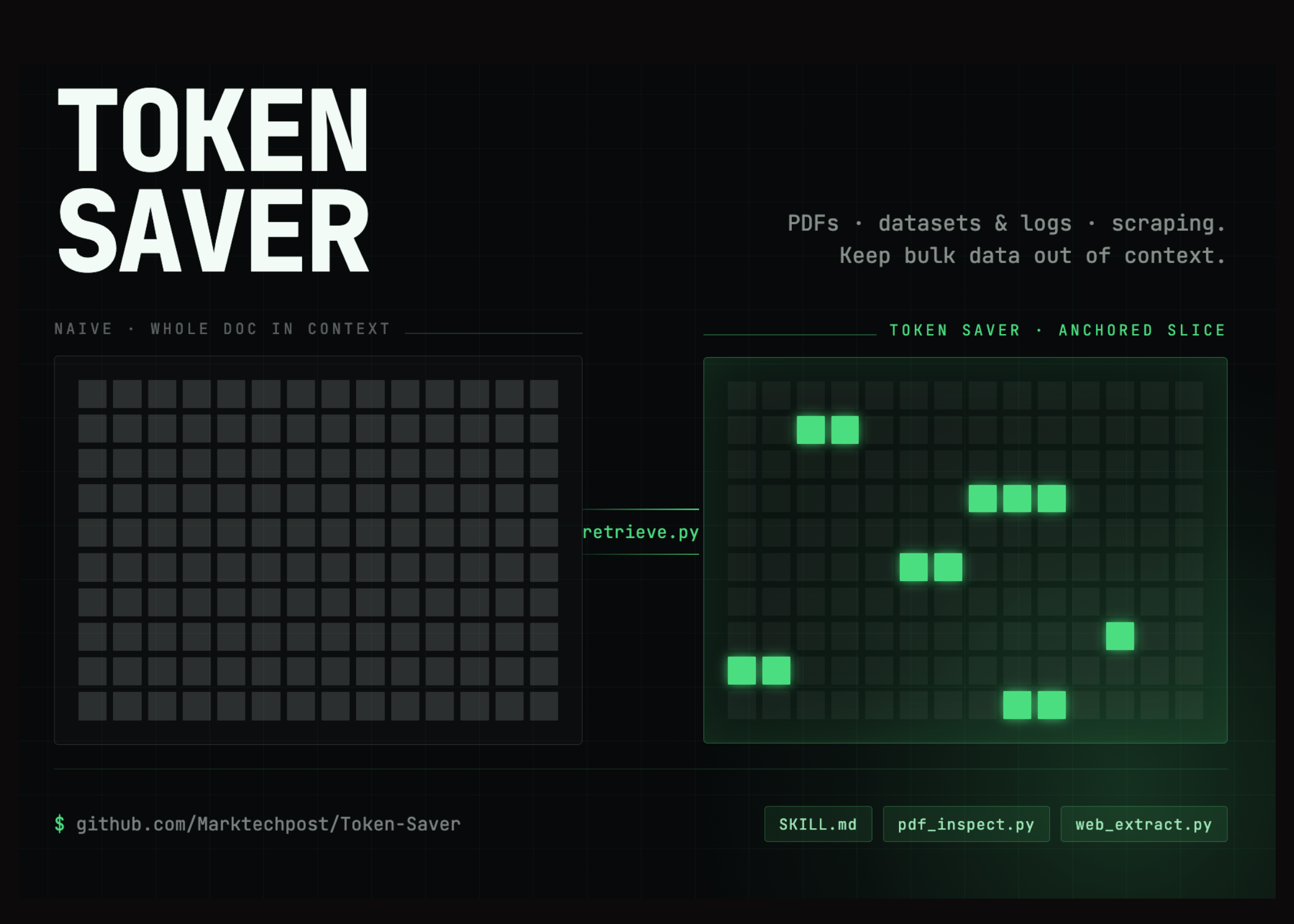
Meet Token Saver: An Open-Source MCP Extension Using Local Hybrid RAG to Cut Claude PDF Token Costs 90-99%
AI developers, researchers, and professionals frequently hit a frustrating wall when analyzing large documents with LLMs: the hidden, compounding cost […]
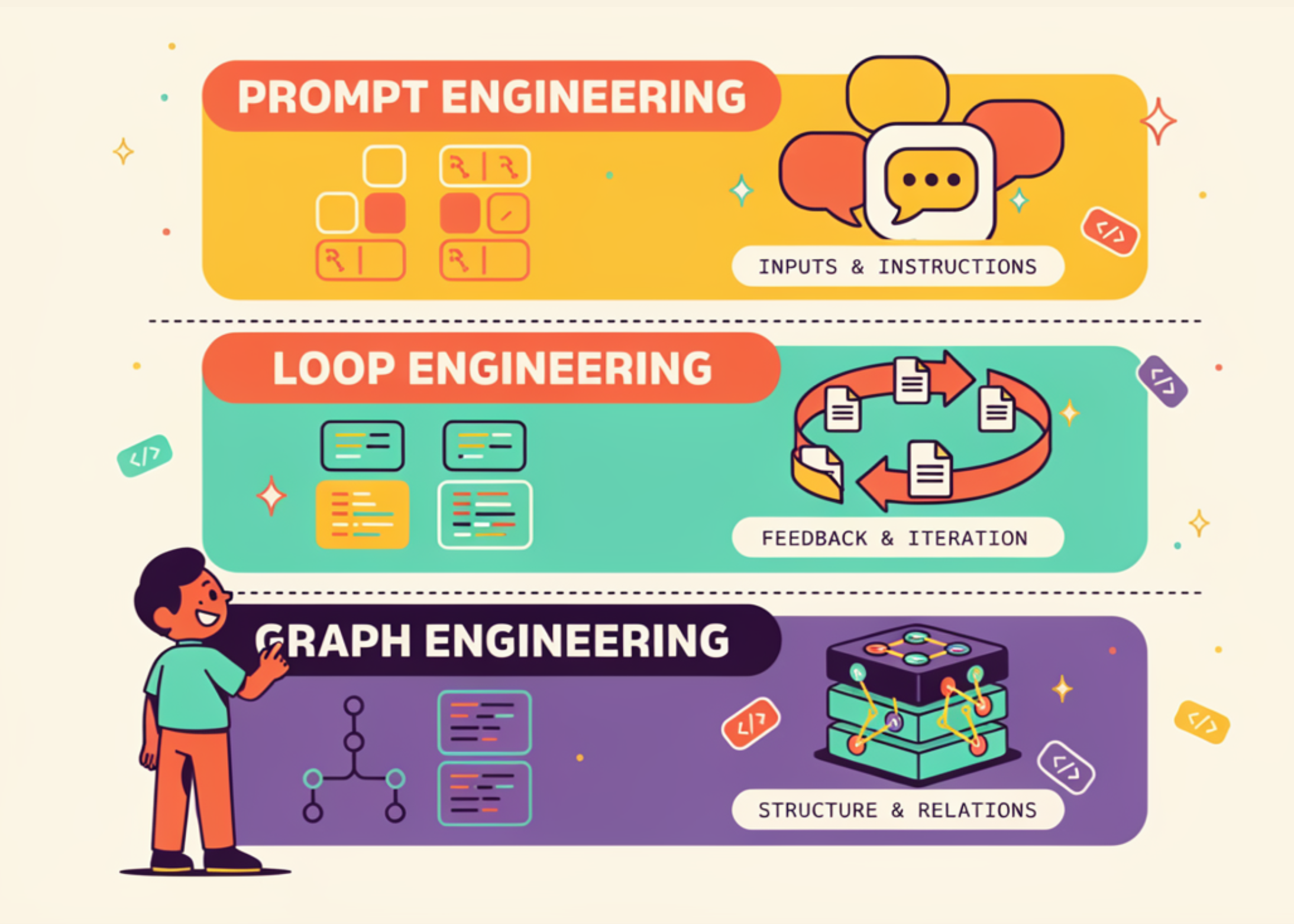
Prompt Engineering vs Loop Engineering vs Graph Engineering: What Changes at Each Layer
Three terms now compete for the same line in AI engineering job descriptions. Prompt engineering is the established one. Loop […]