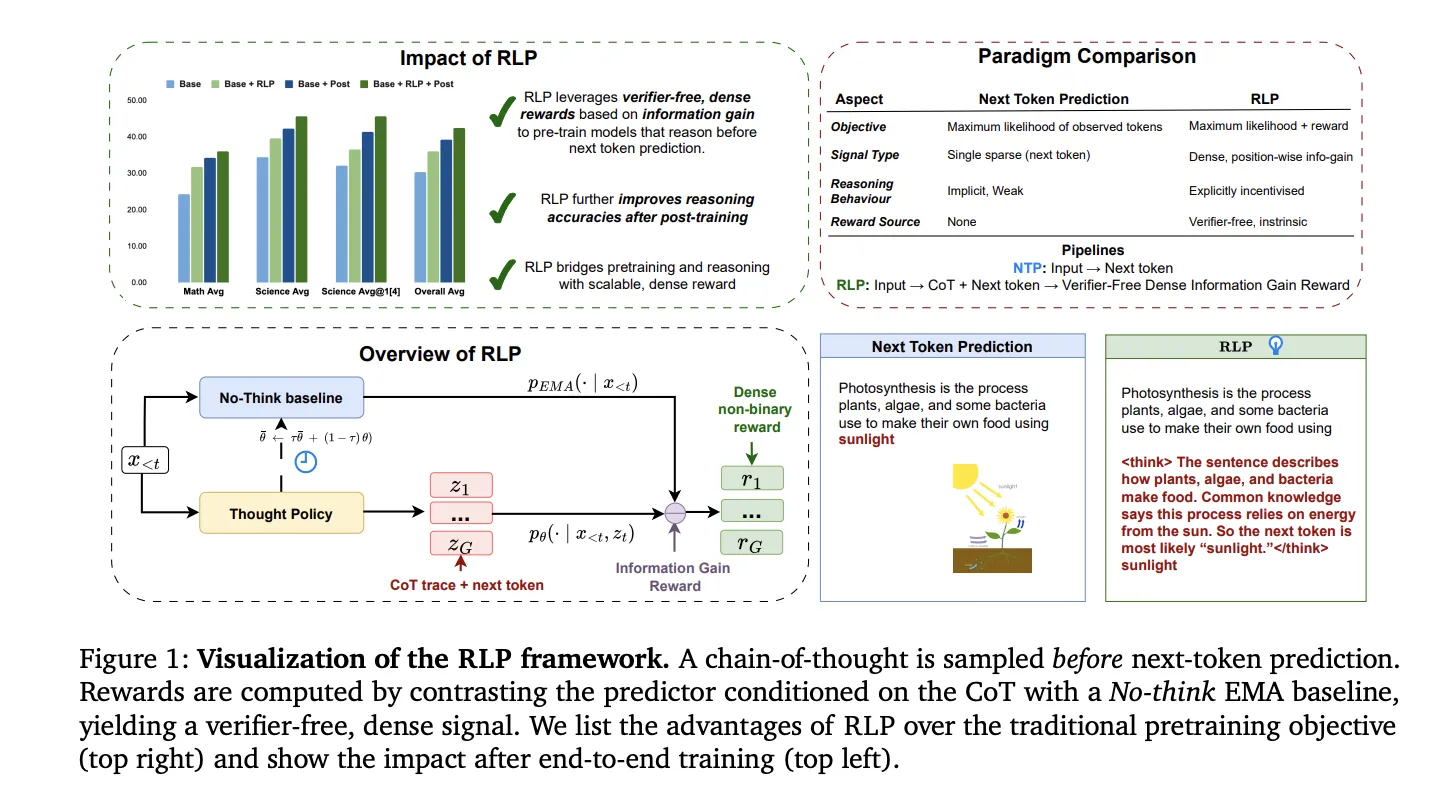
NVIDIA AI has introduced Reinforcement Learning Pretraining (RLP), a training objective that injects reinforcement learning into the pretraining stage rather than deferring it to post-training. The core idea is simple and testable: treat a short chain-of-thought (CoT) as an action sampled before next-token prediction and reward it by the information gain it provides on the observed next token, measured against a no-think EMA baseline. This produces a verifier-free, dense, position-wise reward that can be applied to ordinary text streams at pretraining scale.
Mechanism: Information-Gain Rewards with an EMA Counterfactual
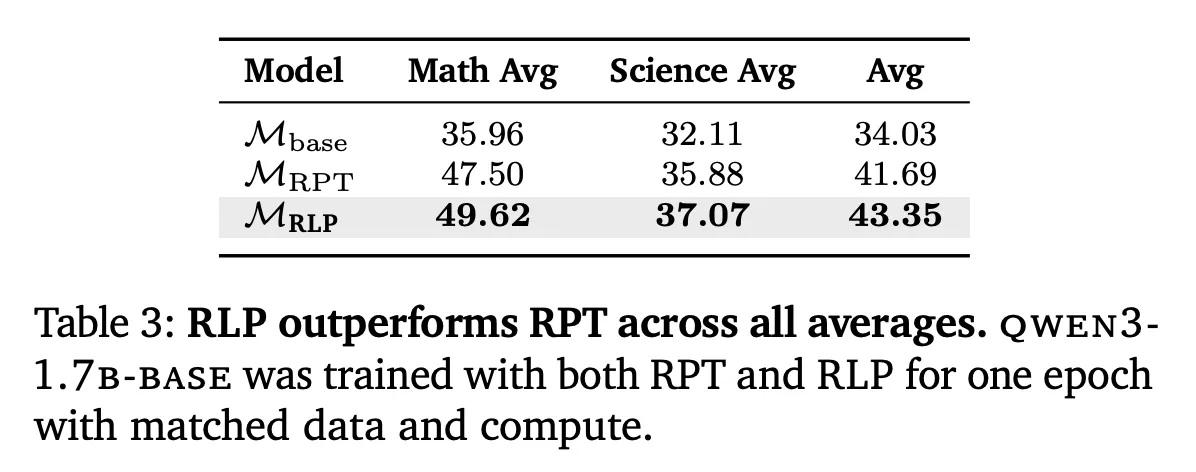
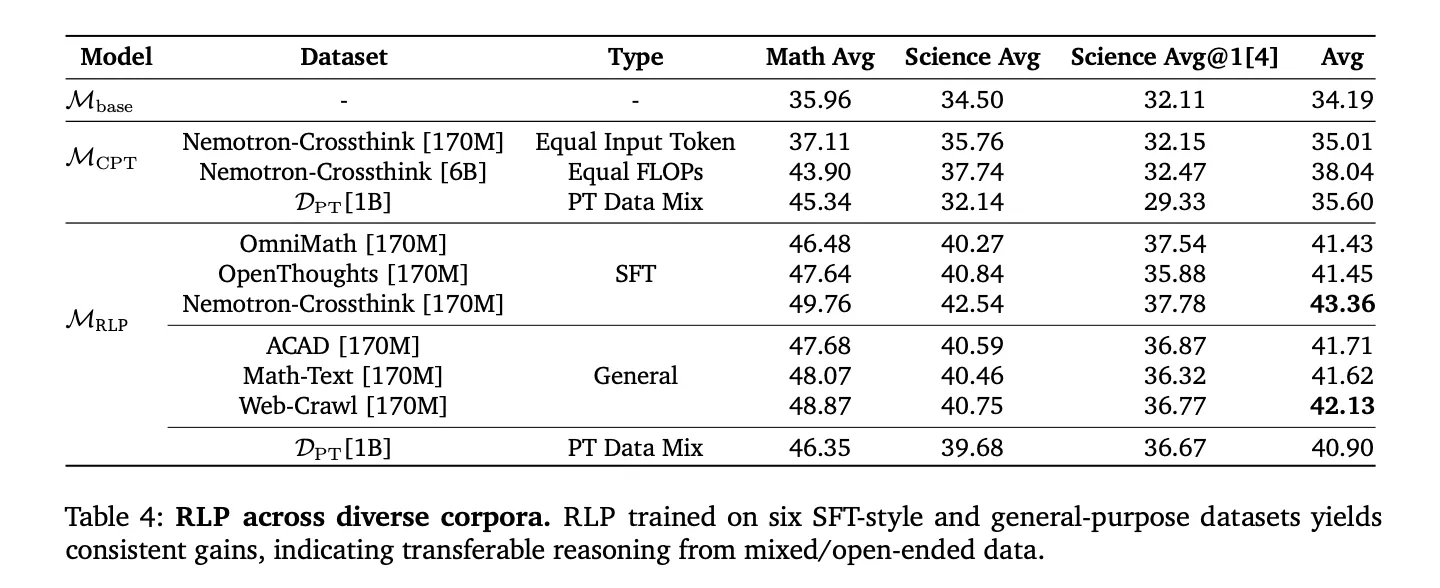
RLP uses a single network (shared parameters) to (1) sample a CoT policy 𝜋 𝜃 ( 𝑐 𝑡 ∣ 𝑥 < 𝑡 ) π θ (c t ∣x r(ct)=logpθ(xt∣x Why this matters technically: unlike prior “reinforcement pretraining” variants that rely on sparse, binary correctness signals or proxy filters, RLP’s dense, verifier-free reward attaches position-wise credit wherever thinking improves prediction, enabling updates at every token position in general web-scale corpora without external verifiers or curated answer keys. Qwen3-1.7B-Base: Pretraining with RLP improved the overall math+science average by ~19% vs the base model and ~17% vs compute-matched continuous pretraining (CPT). After identical post-training (SFT + RLVR) across all variants, the RLP-initialized model retained a ~7–8% relative advantage, with the largest gains on reasoning-heavy benchmarks (AIME25, MMLU-Pro). Nemotron-Nano-12B v2: Applying RLP to a 12B hybrid Mamba-Transformer checkpoint yielded an overall average increase from 42.81% to 61.32% and an absolute +23% gain on scientific reasoning, even though the RLP run used ~200B fewer tokens (training for 19.8T vs 20T tokens; RLP applied for 250M tokens). This highlights data efficiency and architecture-agnostic behavior. RPT comparison: Under matched data and compute with Omni-MATH-style settings, RLP outperformed RPT on math, science, and overall averages—attributed to RLP’s continuous information-gain reward versus RPT’s sparse binary signal and entropy-filtered tokens. Reinforcement Learning Pretraining (RLP) is orthogonal to post-training pipelines (SFT, RLVR) and shows compounding improvements after standard alignment. Because the reward is computed from model log-evidence rather than external verifiers, it scales to domain-agnostic corpora (web crawl, academic text, textbooks) and SFT-style reasoning corpora, avoiding the brittleness of narrow curated datasets. In compute-matched comparisons (including CPT with 35× more tokens to match FLOPs), RLP still led on overall averages, suggesting the improvements derive from objective design, not budget. RLP reframes pretraining to directly reward “think-before-predict” behavior using a verifier-free, information-gain signal, yielding durable reasoning gains that persist through identical SFT+RLVR and extend across architectures (Qwen3-1.7B, Nemotron-Nano-12B v2). The method’s objective—contrasting CoT-conditioned likelihood against a no-think EMA baseline—integrates cleanly into large-scale pipelines without curated verifiers, making it a practical upgrade to next-token pretraining rather than a post-training add-on. Check out the Paper, Code and Project Page. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.Understanding the Results
Positioning vs. Post-Training RL and Data Curation
Key Takeaways
Conclusion

Asif Razzaq