
Post-training techniques, such as instruction tuning and reinforcement learning from human feedback, have become essential for refining language models. But, […]
Category: Tech News

Meta AI Proposes EvalPlanner: A Preference Optimization Algorithm for Thinking-LLM-as-a-Judge
The rapid advancement of Large Language Models (LLMs) has significantly improved their ability to generate long-form responses. However, evaluating these […]

Agentic AI: The Foundations Based on Perception Layer, Knowledge Representation and Memory Systems
Agentic AI stands at the intersection of autonomy, intelligence, and adaptability, offering solutions that can sense, reason, and act in […]

From Deep Knowledge Tracing to DKT2: A Leap Forward in Educational AI
Knowledge Tracing (KT) plays a crucial role in Intelligent Tutoring Systems (ITS) by modeling students’ knowledge states and predicting their […]

Baidu Research Introduces EICopilot: An Intelligent Agent-based Chatbot to Retrieve and Interpret Enterprise Information from Massive Graph Databases
Knowledge graphs have been used tremendously in the field of enterprise lately, with their applications realized in multiple data forms […]
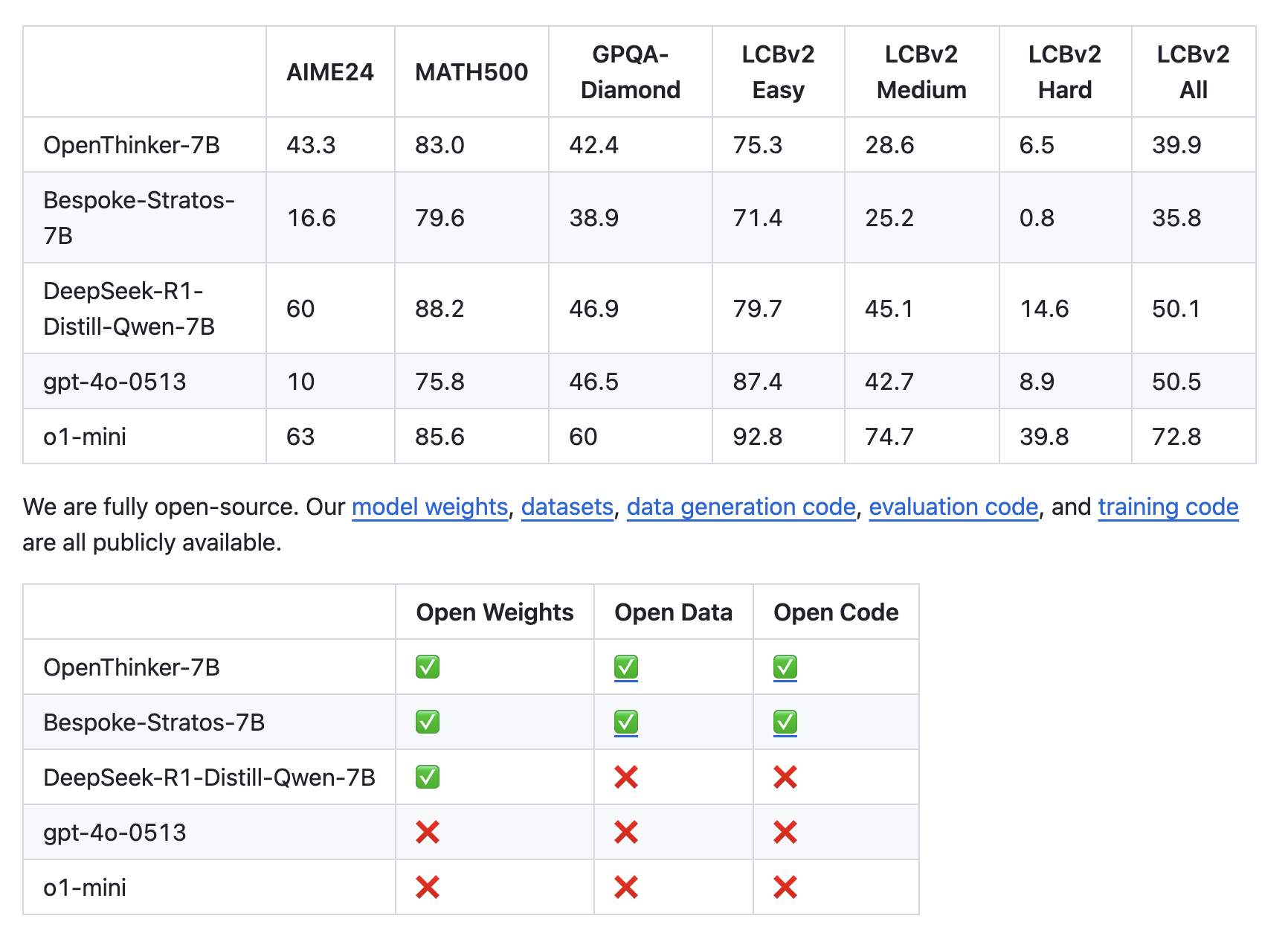
Open Thoughts: An Open Source Initiative Advancing AI Reasoning with High-Quality Datasets and Models Like OpenThoughts-114k and OpenThinker-7B
The critical issue of restricted access to high-quality reasoning datasets has limited open-source AI-driven logical and mathematical reasoning advancements. While […]
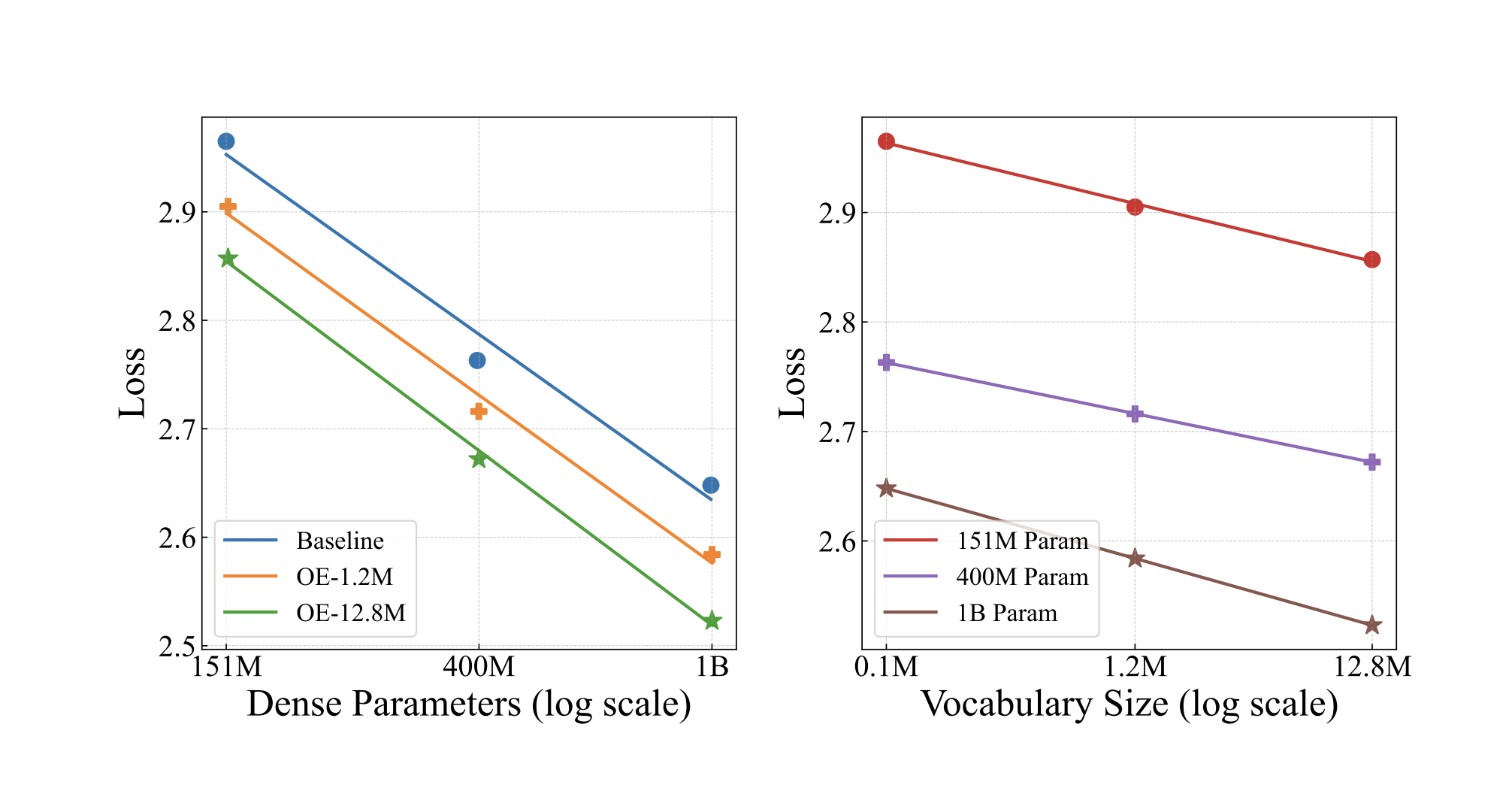
Decoupling Tokenization: How Over-Tokenized Transformers Redefine Vocabulary Scaling in Language Models
Tokenization plays a fundamental role in the performance and scalability of Large Language Models (LLMs). Despite being a critical component, […]
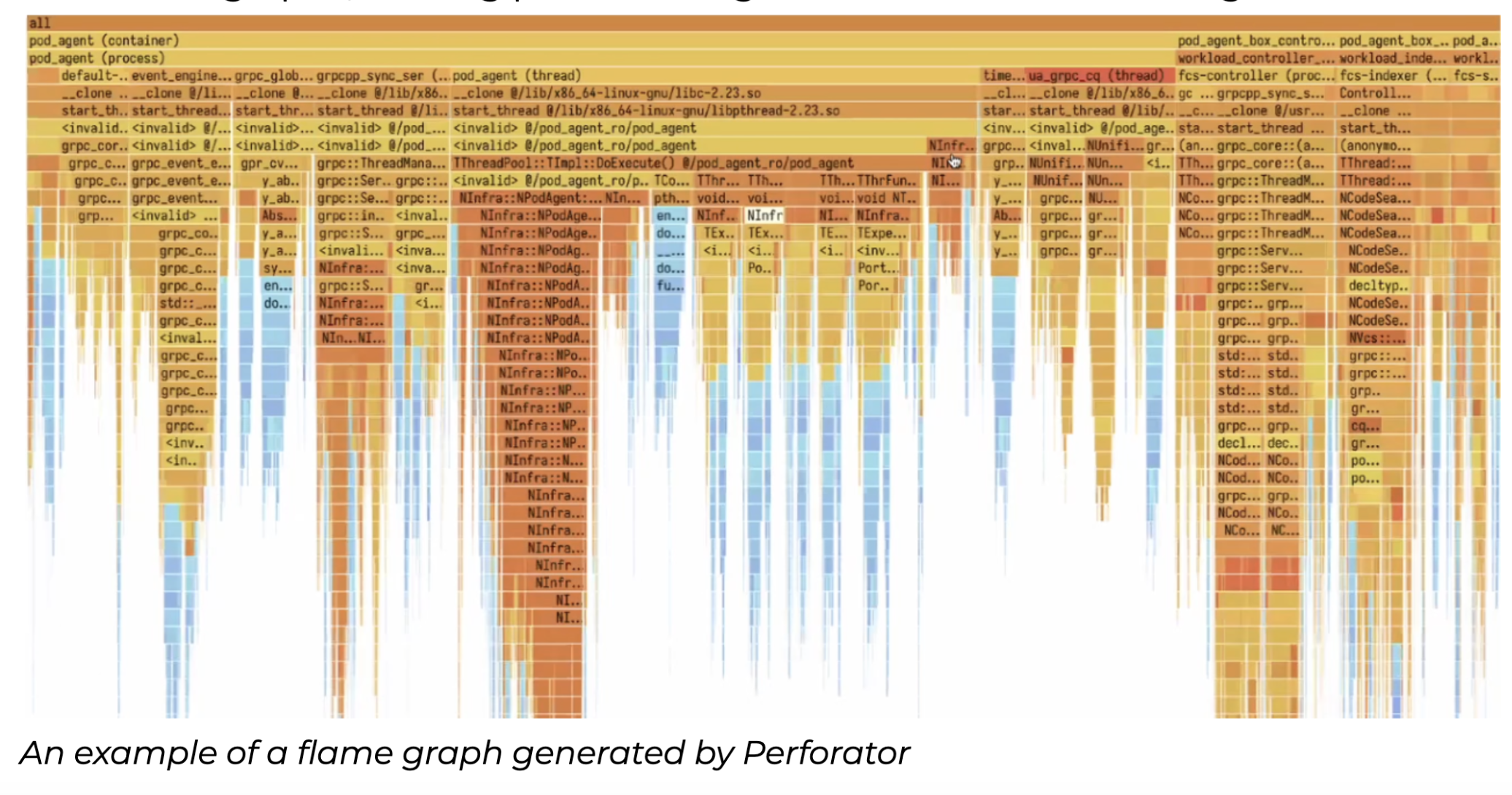
Yandex Develops and Open-Sources Perforator: An Open-Source Tool that can Save Businesses Billions of Dollars a Year on Server Infrastructure
Yandex, a global tech company, develops and open-sources Perforator, an innovative tool for continuous real-time monitoring and analysis of servers […]
Quantization Space Utilization Rate (QSUR): A Novel Post-Training Quantization Method Designed to Enhance the Efficiency of Large Language Models (LLMs)
Post-training quantization (PTQ) focuses on reducing the size and improving the speed of large language models (LLMs) to make them […]

YuE: An Open-Source Music Generation AI Model Family Capable of Creating Full-Length Songs with Coherent Vocals, Instrumental Harmony, and Multi-Genre Creativity
Significant progress has been made in short-form instrumental compositions in AI and music generation. However, creating full songs with lyrics, […]