
Large language models (LLMs) have gained prominence for their ability to handle complex reasoning tasks, transforming applications from chatbots to […]
Category: Large Language Model

LLMs Can Be Misled by Surprising Data: Google DeepMind Introduces New Techniques to Predict and Reduce Unintended Knowledge Contamination
Large language models (LLMs) are continually evolving by ingesting vast quantities of text data, enabling them to become more accurate […]

Meta AI Introduces Collaborative Reasoner (Coral): An AI Framework Specifically Designed to Evaluate and Enhance Collaborative Reasoning Skills in LLMs
Rethinking the Problem of Collaboration in Language Models Large language models (LLMs) have demonstrated remarkable capabilities in single-agent tasks such […]

NVIDIA Introduces CLIMB: A Framework for Iterative Data Mixture Optimization in Language Model Pretraining
Challenges in Constructing Effective Pretraining Data Mixtures As large language models (LLMs) scale in size and capability, the choice of […]
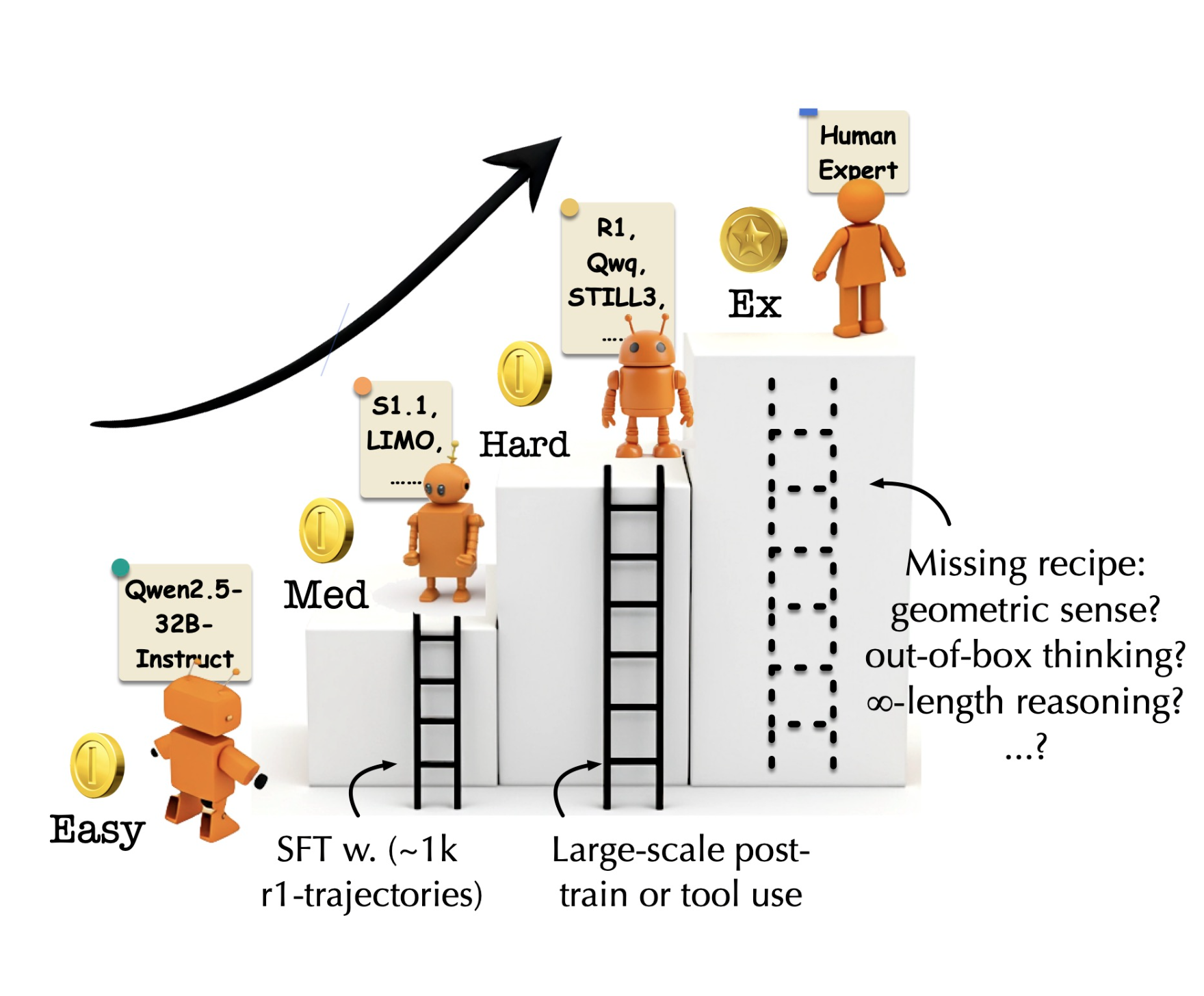
LLMs Can Now Solve Challenging Math Problems with Minimal Data: Researchers from UC Berkeley and Ai2 Unveil a Fine-Tuning Recipe That Unlocks Mathematical Reasoning Across Difficulty Levels
Language models have made significant strides in tackling reasoning tasks, with even small-scale supervised fine-tuning (SFT) approaches such as LIMO […]
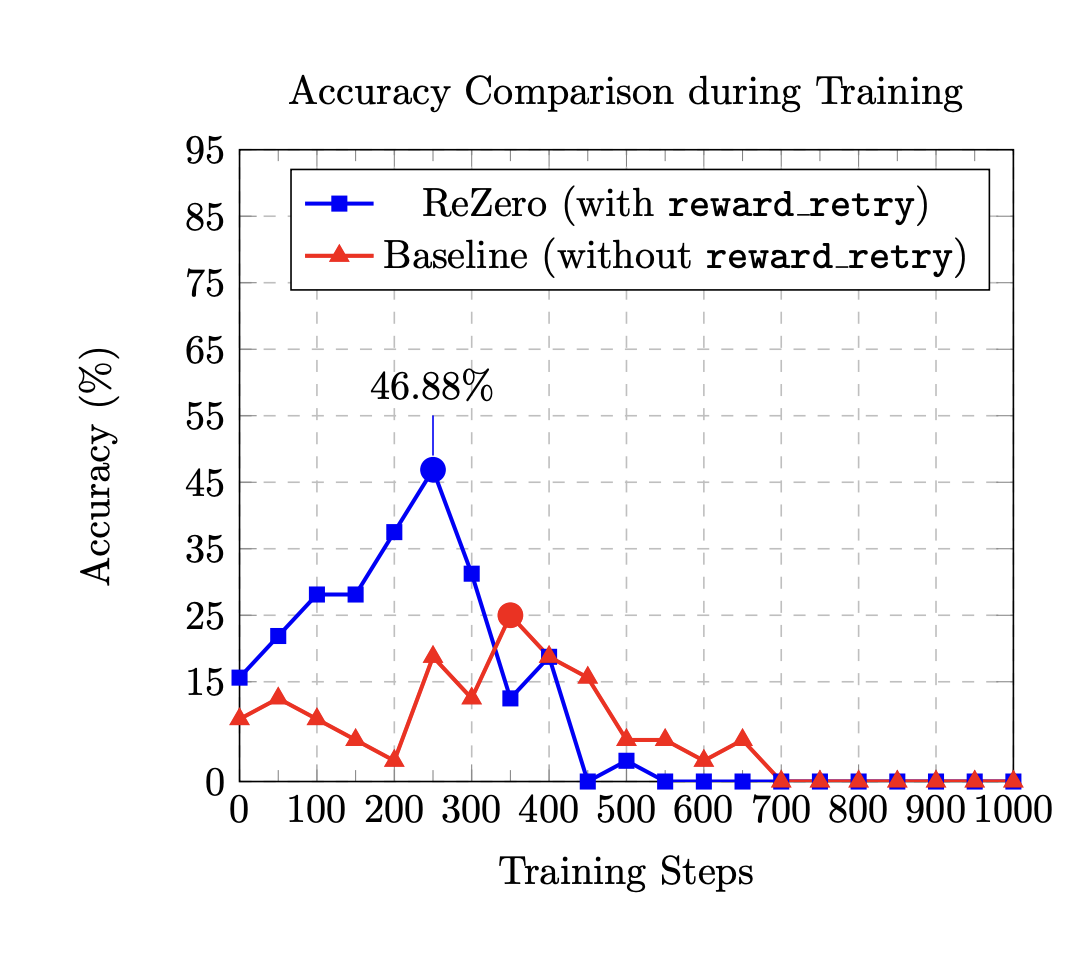
LLMs Can Now Learn to Try Again: Researchers from Menlo Introduce ReZero, a Reinforcement Learning Framework That Rewards Query Retrying to Improve Search-Based Reasoning in RAG Systems
The domain of LLMs has rapidly evolved to include tools that empower these models to integrate external knowledge into their […]

IBM Releases Granite 3.3 8B: A New Speech-to-Text (STT) Model that Excels in Automatic Speech Recognition (ASR) and Automatic Speech Translation (AST)
As artificial intelligence continues to integrate into enterprise systems, the demand for models that combine flexibility, efficiency, and transparency has […]

Model Performance Begins with Data: Researchers from Ai2 Release DataDecide—A Benchmark Suite to Understand Pretraining Data Impact Across 30K LLM Checkpoints
The Challenge of Data Selection in LLM Pretraining Developing large language models entails substantial computational investment, especially when experimenting with […]

MIT Researchers Introduce DISCIPL: A Self-Steering Framework Using Planner and Follower Language Models for Efficient Constrained Generation and Reasoning
Language models predict sequences of words based on vast datasets and are increasingly expected to reason and perform complex linguistic […]

Transformers Can Now Predict Spreadsheet Cells without Fine-Tuning: Researchers Introduce TabPFN Trained on 100 Million Synthetic Datasets
Tabular data is widely utilized in various fields, including scientific research, finance, and healthcare. Traditionally, machine learning models such as […]