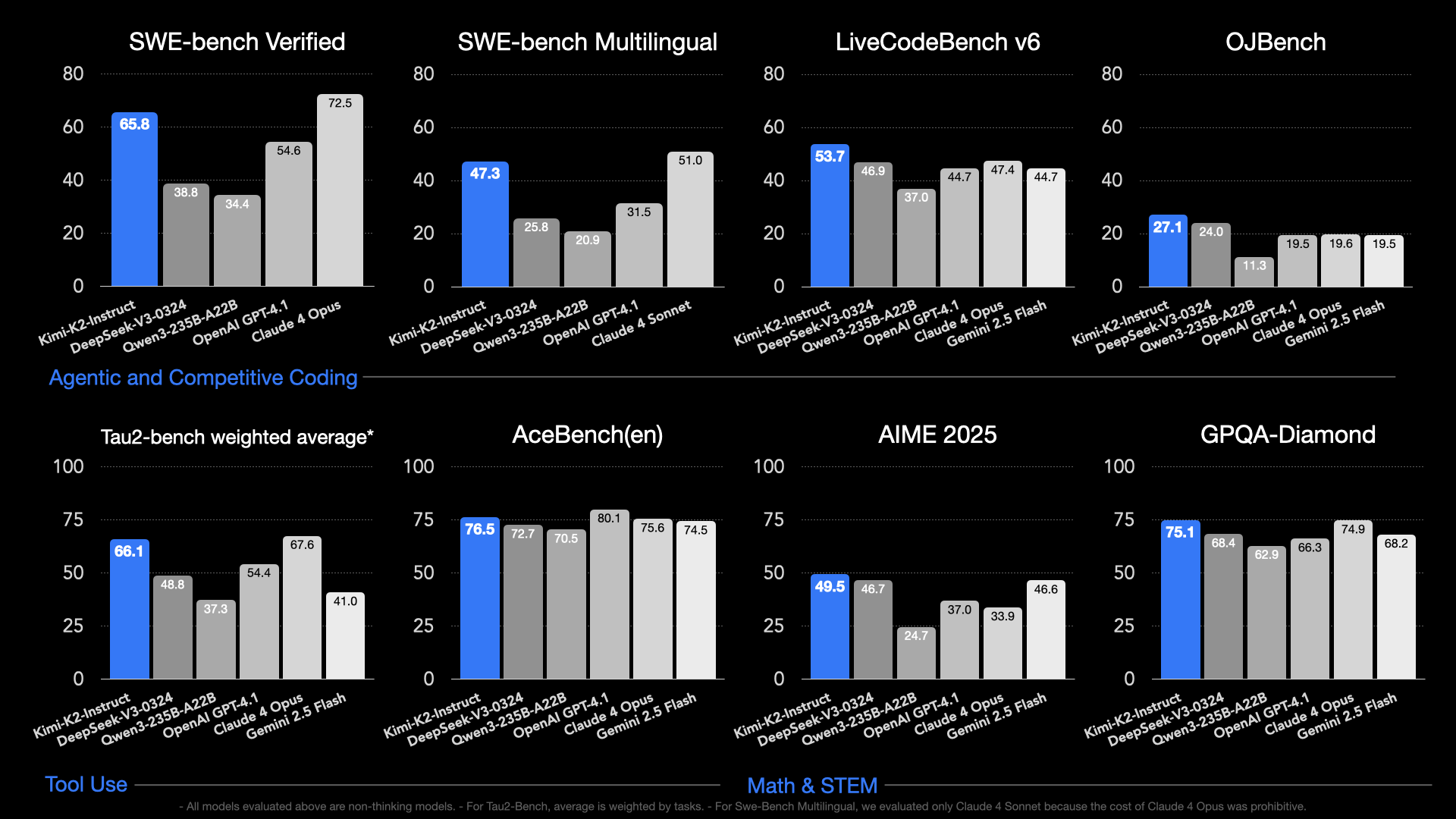
Kimi K2, launched by Moonshot AI in July 2025, is a purpose-built, open-source Mixture-of-Experts (MoE) model—1 trillion total parameters, with 32 billion […]
Category: Large Language Model

Mistral AI Releases Devstral 2507 for Code-Centric Language Modeling
Mistral AI, in collaboration with All Hands AI, has released updated versions of its developer-focused large language models under the […]
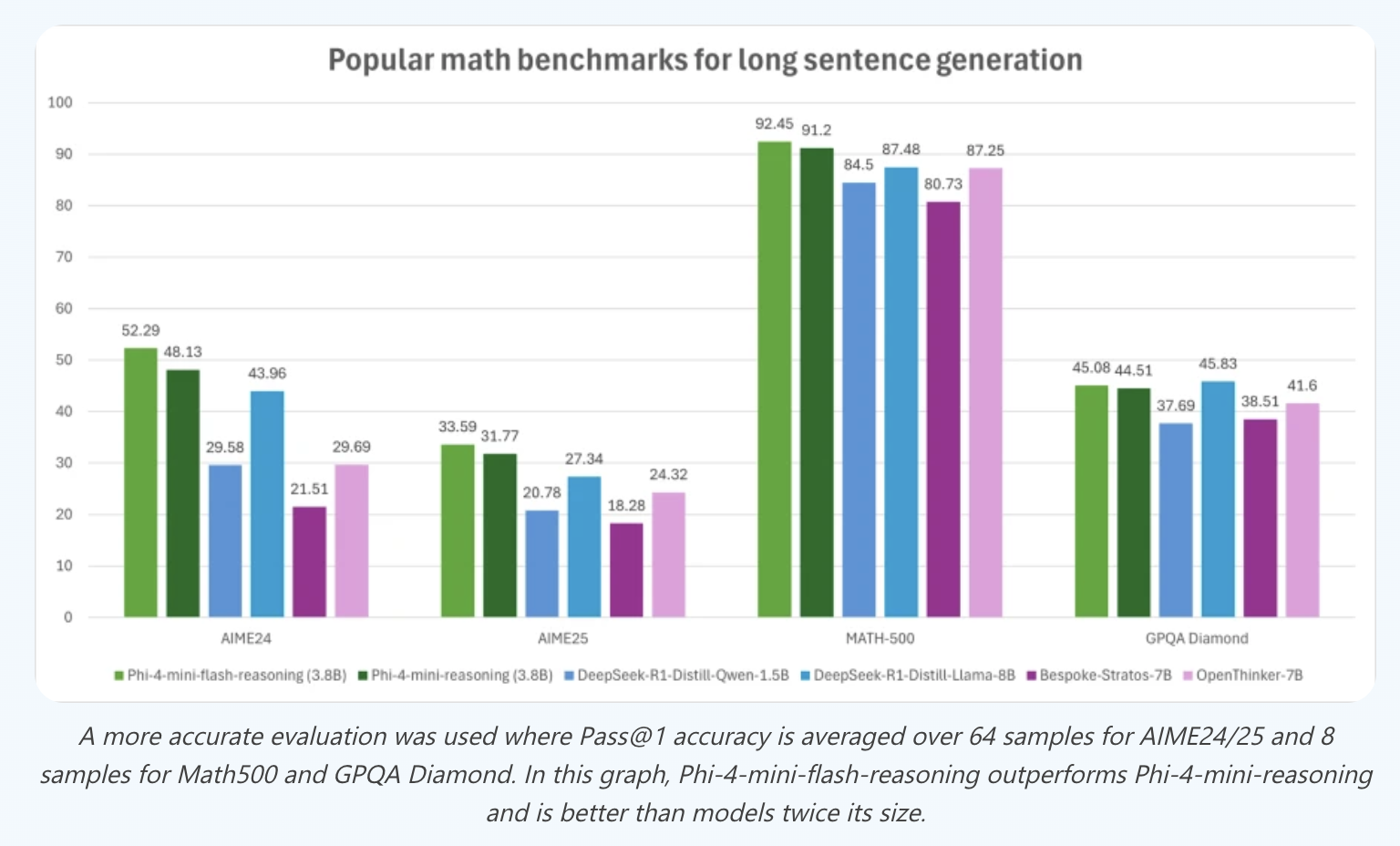
Microsoft Releases Phi-4-mini-Flash-Reasoning: Efficient Long-Context Reasoning with Compact Architecture
Phi-4-mini-Flash-Reasoning, the latest addition to Microsoft’s Phi-4 model family, is an open, lightweight language model designed to excel at long-context […]
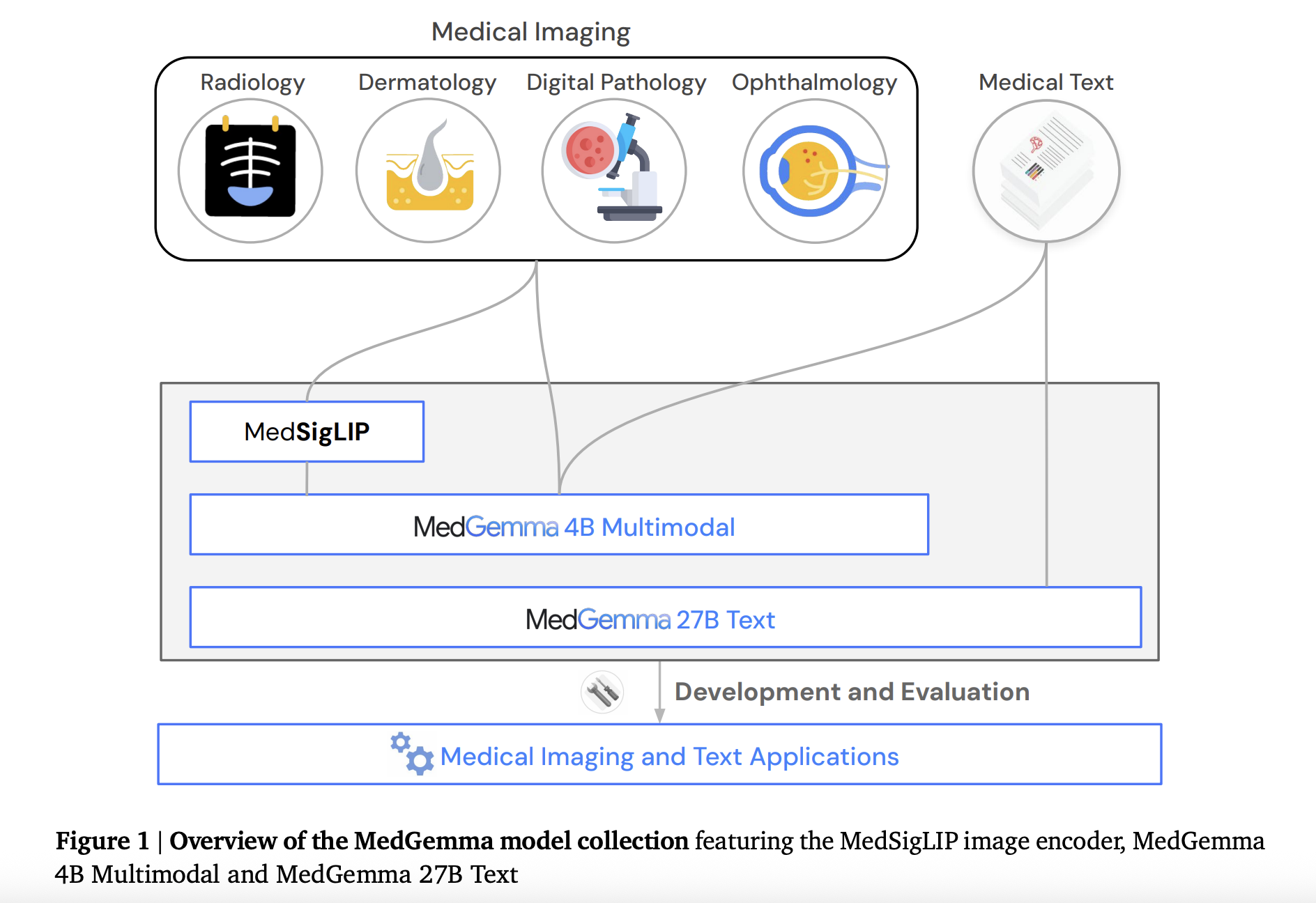
Google AI Open-Sourced MedGemma 27B and MedSigLIP for Scalable Multimodal Medical Reasoning
In a strategic move to advance open-source development in medical AI, Google DeepMind and Google Research have introduced two new […]
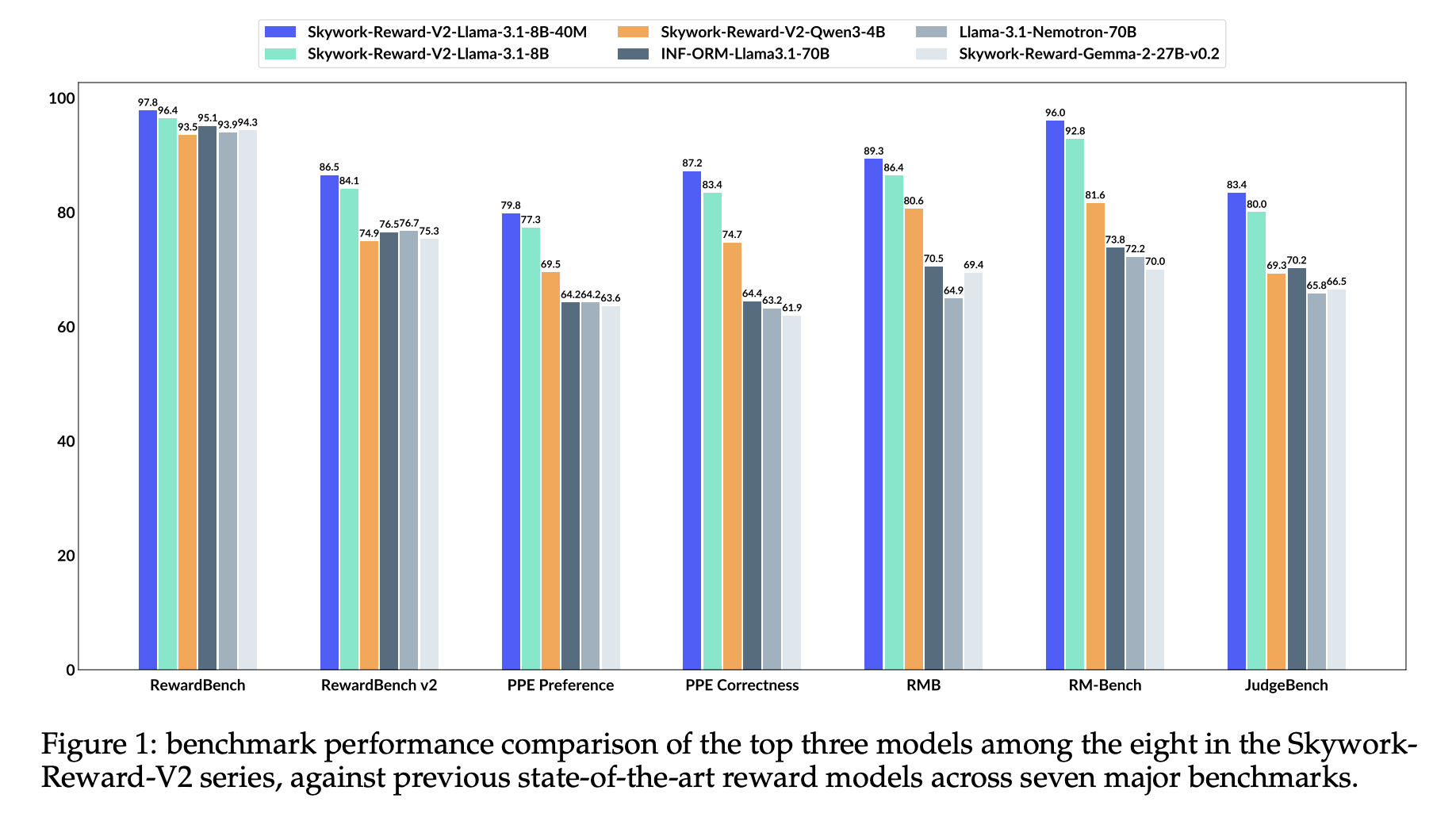
SynPref-40M and Skywork-Reward-V2: Scalable Human-AI Alignment for State-of-the-Art Reward Models
Understanding Limitations of Current Reward Models Although reward models play a crucial role in Reinforcement Learning from Human Feedback (RLHF), […]
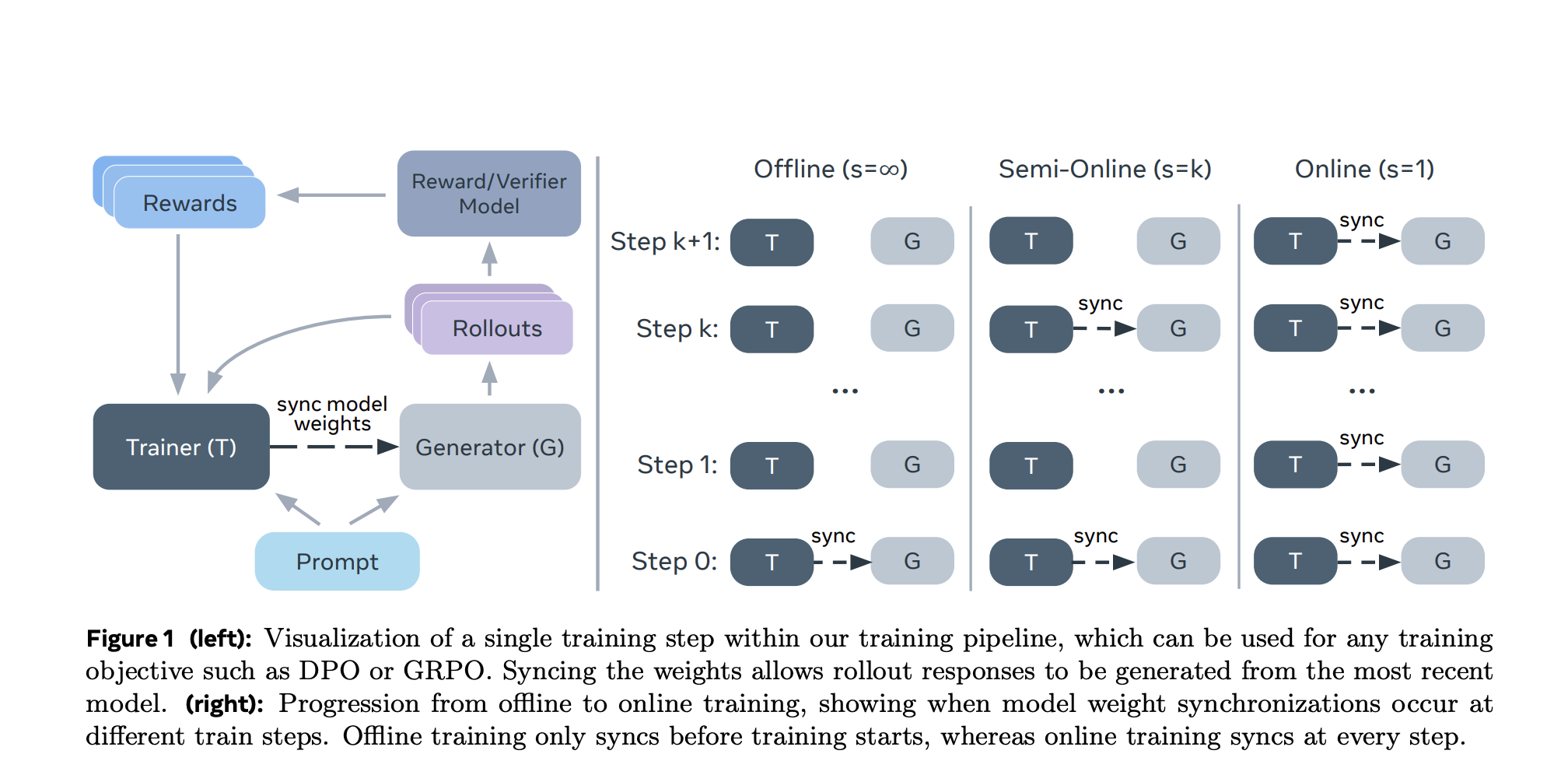
New AI Method From Meta and NYU Boosts LLM Alignment Using Semi-Online Reinforcement Learning
Optimizing LLMs for Human Alignment Using Reinforcement Learning Large language models often require a further alignment phase to optimize them […]
What Is Context Engineering in AI? Techniques, Use Cases, and Why It Matters
Introduction: What is Context Engineering? Context engineering refers to the discipline of designing, organizing, and manipulating the context that is […]
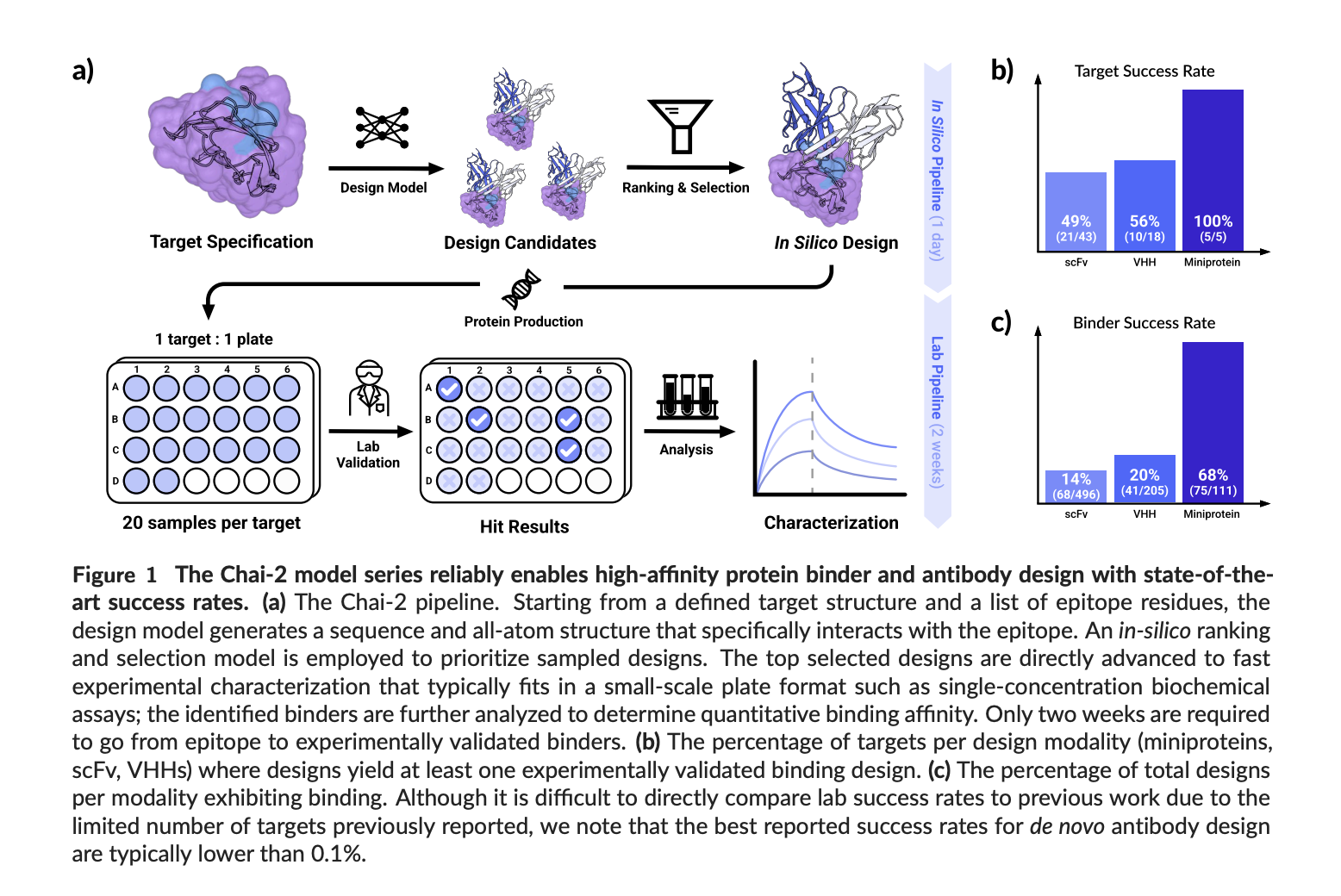
Chai Discovery Team Releases Chai-2: AI Model Achieves 16% Hit Rate in De Novo Antibody Design
TLDR: Chai Discovery Team introduces Chai-2, a multimodal AI model that enables zero-shot de novo antibody design. Achieving a 16% […]

AbstRaL: Teaching LLMs Abstract Reasoning via Reinforcement to Boost Robustness on GSM Benchmarks
Recent research indicates that LLMs, particularly smaller ones, frequently struggle with robust reasoning. They tend to perform well on familiar […]
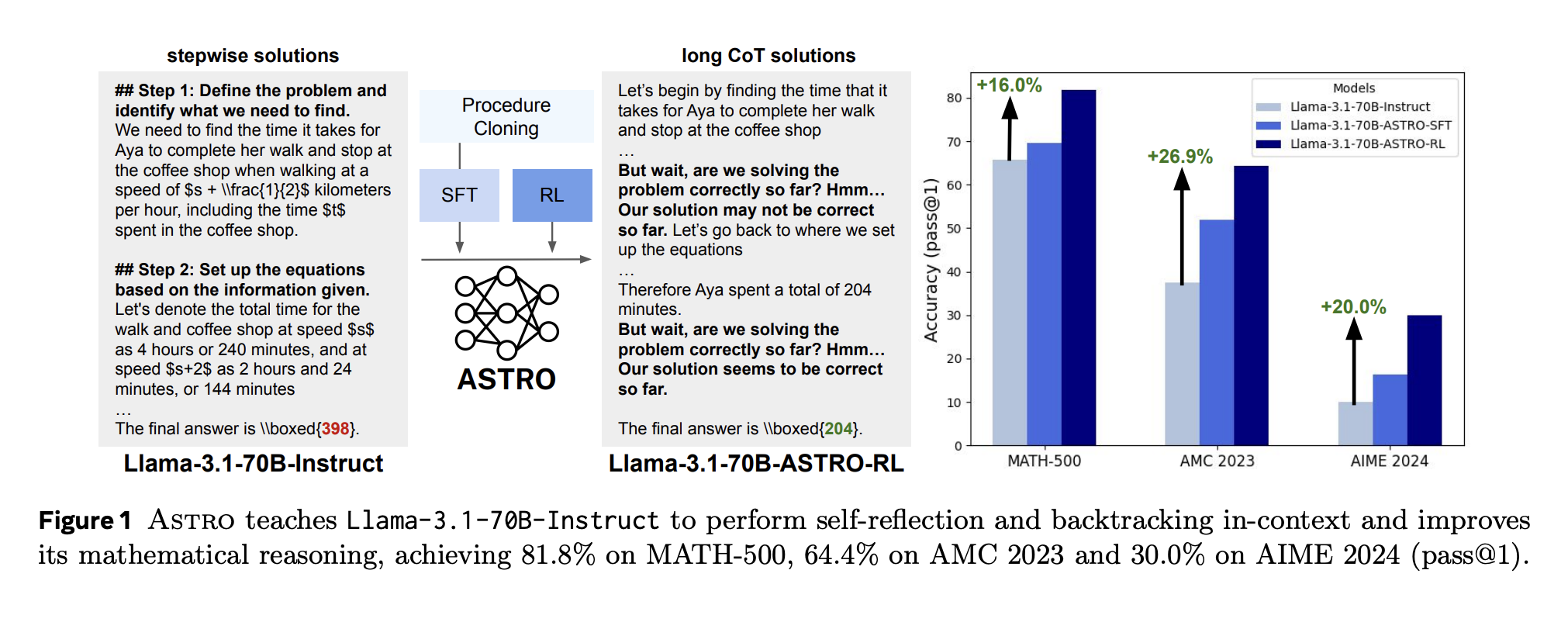
Can We Improve Llama 3’s Reasoning Through Post-Training Alone? ASTRO Shows +16% to +20% Benchmark Gains
Improving the reasoning capabilities of large language models (LLMs) without architectural changes is a core challenge in advancing AI alignment […]