
Is it clean “reverse engineering” or just an LLM-filtered “derivative work”?
Meet your new open source coding team! Credit: Getty Images
Computer engineers and programmers have long relied on reverse engineering as a way to copy the functionality of a computer program without copying that program’s copyright-protected code directly. Now, AI coding tools are raising new issues with how that “clean room” rewrite process plays out both legally, ethically, and practically.
Those issues came to the forefront last week with the release of a new version of chardet, a popular open source python library for automatically detecting character encoding. The repository was originally written by coder Mark Pilgrim in 2006 and released under an LGPL license that placed strict limits on how it could be reused and redistributed.
Dan Blanchard took over maintenance of the repository in 2012 but waded into some controversy with the release of version 7.0 of chardet last week. Blanchard described that overhaul as “a ground-up, MIT-licensed rewrite” of the entire library built with the help of Claude Code to be “much faster and more accurate” than what came before.
Speaking to The Register, Blanchard said that he has long wanted to get chardet added to the Python standard library but that he didn’t have the time to fix problems with “its license, its speed, and its accuracy” that were getting in the way of that goal. With the help of Claude Code, though, Blanchard said he was able to overhaul the library “in roughly five days” and get a 48x performance boost to boot.
Not everyone has been happy with that outcome, though. A poster using the name Mark Pilgrim surfaced on GitHub to argue that this new version amounts to an illegitimate relicensing of Pilgrim’s original code under a more permissive MIT license (which, among other things, allows for its use in closed-source projects). As a modification of his original LGPL-licensed code, Pilgrim argues this new version of chardet must also maintain the same LGPL license.
“Their claim that it is a ‘complete rewrite’ is irrelevant, since they had ample exposure to the originally licensed code (i.e., this is not a ‘clean room’ implementation),” Pilgrim wrote. “Adding a fancy code generator into the mix does not somehow grant them any additional rights. I respectfully insist that they revert the project to its original license.”
Whose code is it, anyway?
In his own response to Pilgrim, Blanchard admits that he has had “extensive exposure to the original codebase,” meaning he didn’t have the traditional “strict separation” usually used for “clean room” reverse engineering. But that tradition was set up for human coders as a way “to ensure the resulting code is not a derivative work of the original,” Blanchard argues.
In this case, Blanchard said that the new AI-generated code is “qualitatively different” from what came before it and “is structurally independent of the old code.” As evidence, he cites JPlag similarity statistics showing that a maximum of 1.29 percent of any chardet version 7.0.0 file is structurally similar to the corresponding file in version 6.0.0. Comparing version 5.2.0 to version 6.0.0, on the other hand, finds up to 80 percent similarity in some corresponding files.
“No file in the 7.0.0 codebase structurally resembles any file from any prior release,” Blanchard writes. “This is not a case of ‘rewrote most of it but carried some files forward.’ Nothing was carried forward.”
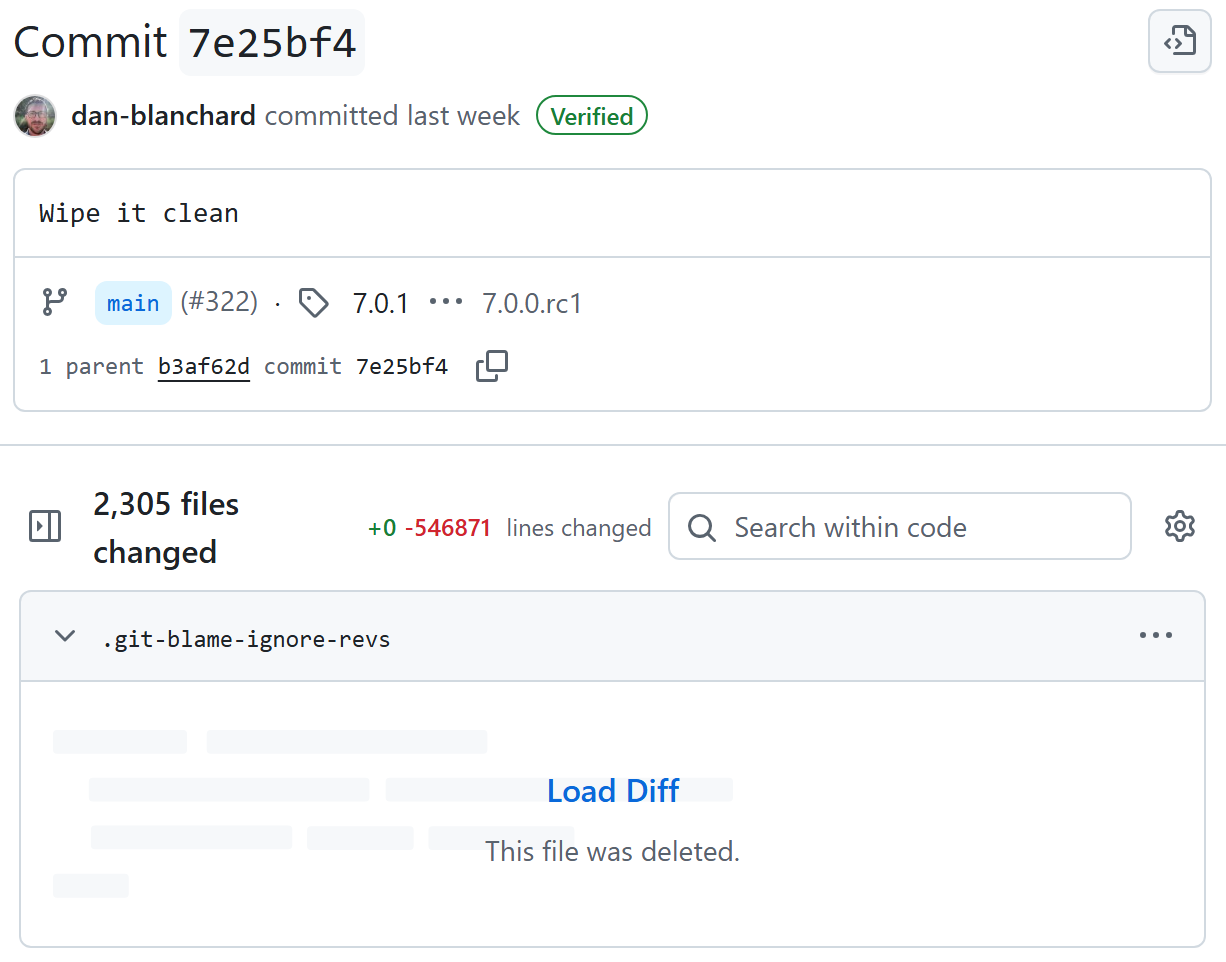
Blanchard says starting with a “wipe it clean” commit and a fresh repository was key in crafting fresh, non-derivative code from the AI.
Blanchard says starting with a “wipe it clean” commit and a fresh repository was key in crafting fresh, non-derivative code from the AI. Credit: Dan Blanchard / Github
Blanchard says he was able to accomplish this “AI clean room” process by first specifying an architecture in a design document and writing out some requirements to Claude Code. After that, Blanchard “started in an empty repository with no access to the old source tree and explicitly instructed Claude not to base anything on LGPL/GPL-licensed code.”
There are a few complicating factors to this straightforward story, though. For one, Claude explicitly relied on some metadata files from previous versions of chardet, raising direct questions about whether this version is actually “derivative.”
For another, Claude’s models are trained on reams of data pulled from the public Internet, which means it’s overwhelmingly likely that Claude has ingested the open source code of previous chardet versions in its training. Whether that prior “knowledge” means that Claude’s creation is a “derivative” of Pilgrim’s work is an open question, even if the new code is structurally different from the old.
And then there’s the remaining human factor. While the code for this new version was generated by Claude, Blanchard said he “reviewed, tested, and iterated on every piece of the result using Claude. … I did not write the code by hand, but I was deeply involved in designing, reviewing, and iterating on every aspect of it.” Having someone with intimate knowledge of earlier chardet code take such a heavy hand in reviewing the new code could also have an impact on whether this version can be considered a wholly new project.
Brave new world
All of these issues have predictably led to a huge debate over legalities of chardet version 7.0.0 across the open source community. “There is nothing ‘clean’ about a Large Language Model which has ingested the code it is being asked to reimplement,” Free Software Foundation Executive Director Zoë Kooyman told The Register.
But others think the “Ship of Theseus”-style arguments that can often emerge in code licensing dust-ups don’t apply as much here. “If you throw away all code and start from scratch, even if the end result behaves the same, it’s a new ship,” Open source developer Armin Ronacher said in a blog post analyzing the situation.

The legal status of AI-generated code is still largely unsettled.
Credit: Getty Images
The legal status of AI-generated code is still largely unsettled. Credit: Getty Images
Old code licenses aside, using AI to create new code from whole cloth could also create its own legal complications going forward. Courts have already said that AI can’t be the author on a patent or the copyright holder on a piece of art but have yet to rule on what that means for the licensing of software created in whole or in part by AI. The issues surrounding potential “tainting” of an open source license with this kind of generated code can get remarkably complex remarkably quickly.
Whatever the outcome here, the practical impact of being able to use AI to quickly rewrite and relicense many open source projects—without nearly as much effort on the part of human programmers—is likely to have huge knock-on effects throughout the community.
“Now the process of rewriting is so simple to do, and many people are disturbed by this,” Italian coder Salvatore “antirez” Sanfilippo wrote on his blog. “There is a more fundamental truth here: the nature of software changed; the reimplementations under different licenses are just an instance of how such nature was transformed forever. Instead of combating each manifestation of automatic programming, I believe it is better to build a new mental model and adapt.”
Others put the sea change in more alarming terms. “I’m breaking the glass and pulling the fire alarm!” open source evangelist Bruce Perens told The Register. “The entire economics of software development are dead, gone, over, kaput! … We have been there before, for example when the printing press happened and resulted in copyright law, when the scientific method proliferated and suddenly there was a logical structure for the accumulation of knowledge. I think this one is just as large.”

Kyle Orland has been the Senior Gaming Editor at Ars Technica since 2012, writing primarily about the business, tech, and culture behind video games. He has journalism and computer science degrees from University of Maryland. He once wrote a whole book about Minesweeper.



