Introduction to Ultra-Long Text Generation Challenges
Generating ultra-long texts that span thousands of words is becoming increasingly important for real-world tasks such as storytelling, legal writing, and educational materials. However, large language models still face significant challenges, including length limits and quality issues, as their outputs become increasingly longer. Common problems include incoherence, topic drift, repetition, and poor structure. Earlier methods, such as LongWriter, utilize supervised fine-tuning on synthetic data to address this issue; however, this data is costly to create, difficult to generate, and often feels unnatural. Moreover, relying on existing LLMs to create training data limits creativity, and typical training methods don’t effectively improve the overall coherence or formatting of long outputs.
Evolution of Long-Form Text Generation Methods
Recent research into long-form text generation has focused on improving coherence, personalization, and extending output length beyond 2,000 words. Early models, such as Re3 and DOC, used recursive strategies to maintain structure, while LongLaMP and others introduced personalization through reasoning-aware self-training. Suri built a large instruction-following dataset but was limited to outputs under 5,000 tokens due to reliance on back-translation. LongWriter advanced this by generating outputs of 6k–20k tokens using supervised fine-tuning and preference optimization, though it retained biases from its teacher models. On another front, RL has improved reasoning in LLMs like DeepSeek-R1 and QwQ-32B, yet RL remains underexplored for ultra-long text generation.
LongWriter-Zero: Reinforcement Learning Without Synthetic Data
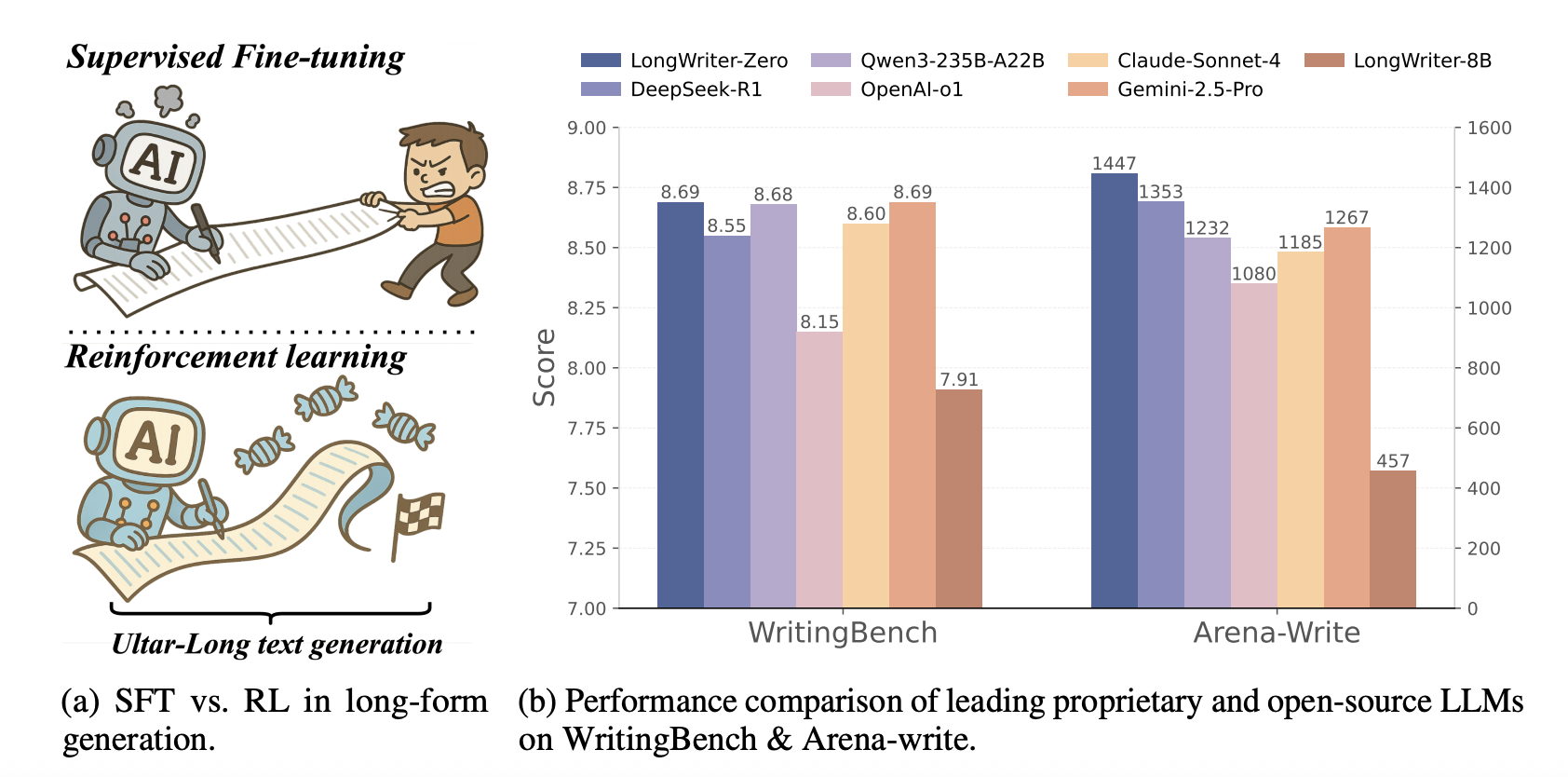
Researchers from Tsinghua University and SUTD introduce LongWriter-Zero. This approach uses RL to train LLMs for ultra-long text generation, without relying on annotated or synthetic data. Starting from the Qwen2.5-32B base model, they apply RL with carefully designed reward models targeting text length, quality, and structure. Their framework draws inspiration from success in math and coding tasks, exploring three key factors: reward design, inference-time scaling, and continual pretraining. LongWriter-Zero surpasses traditional supervised fine-tuning methods, achieving state-of-the-art performance on WritingBench and Arena-Write, even outperforming 100B+ models like DeepSeek-R1.
Novel Optimization Strategy and Benchmarking
The study introduces a reinforcement learning approach to improve ultra-long text generation using LLMs. The researchers build on PPO with a method called Group Relative Policy Optimization, training a 32B parameter model on instruction-following data with a 14k-token output limit. They evaluate outputs using a new benchmark, Arena-Write, and design a reward system that balances text length, fluency, coherence, and format. A key insight is that having the model “think” before writing using intermediate reasoning steps leads to better structure and control. Further gains are achieved through pretraining on writing-heavy data, underscoring the importance of a robust, writing-focused foundation.
Results on Long-Form Generation Benchmarks
LongWriter-Zero is evaluated through a two-step process: continual pretraining on long books using 30 billion tokens, followed by reinforcement learning fine-tuning over 150 steps with “Think” prompts to encourage reasoning. It scores 8.69 on WritingBench, outperforming GPT-4o (8.16), Qwen2.5-Max (8.37), and DeepSeek-R1 (8.55), leading in five out of six domains. In Arena-Write, it attains the highest Elo score of 1447. Removing “Think” prompts or pretraining results in major performance drops, confirming their importance. The model also achieves a win rate of 98.2 percent in GPT-4.1-based comparisons, with human evaluations validating its strength in long-form writing.
Conclusion and Future Outlook on Reward Design
In conclusion, LongWriter-Zero proposes a reinforcement learning approach to ultra-long text generation, thereby avoiding the need for synthetic or labeled datasets. Built on Qwen2.5-32B and trained from scratch, it utilizes reward models that target length control, writing quality, and formatting. It achieves top scores on WritingBench (8.69) and Arena-Write (Elo 1447), outperforming GPT-4o (8.16), DeepSeek-R1 (8.55), and Qwen3-235B-A22B (Elo 1343). Human and GPT-4.1-based evaluations show win rates as high as 98.2%. However, it faces reward model hacking, such as inflating length through repetition or inserting keywords like “quantum entanglement” for higher scores. Addressing these limitations will require a better design of rewards and human-in-the-loop strategies.
Check out the Paper and Dataset Card. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.

Sana Hassan
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.



