Standing on the shoulders of giants
Assistance from an external “agent harness” was key to the model’s success.
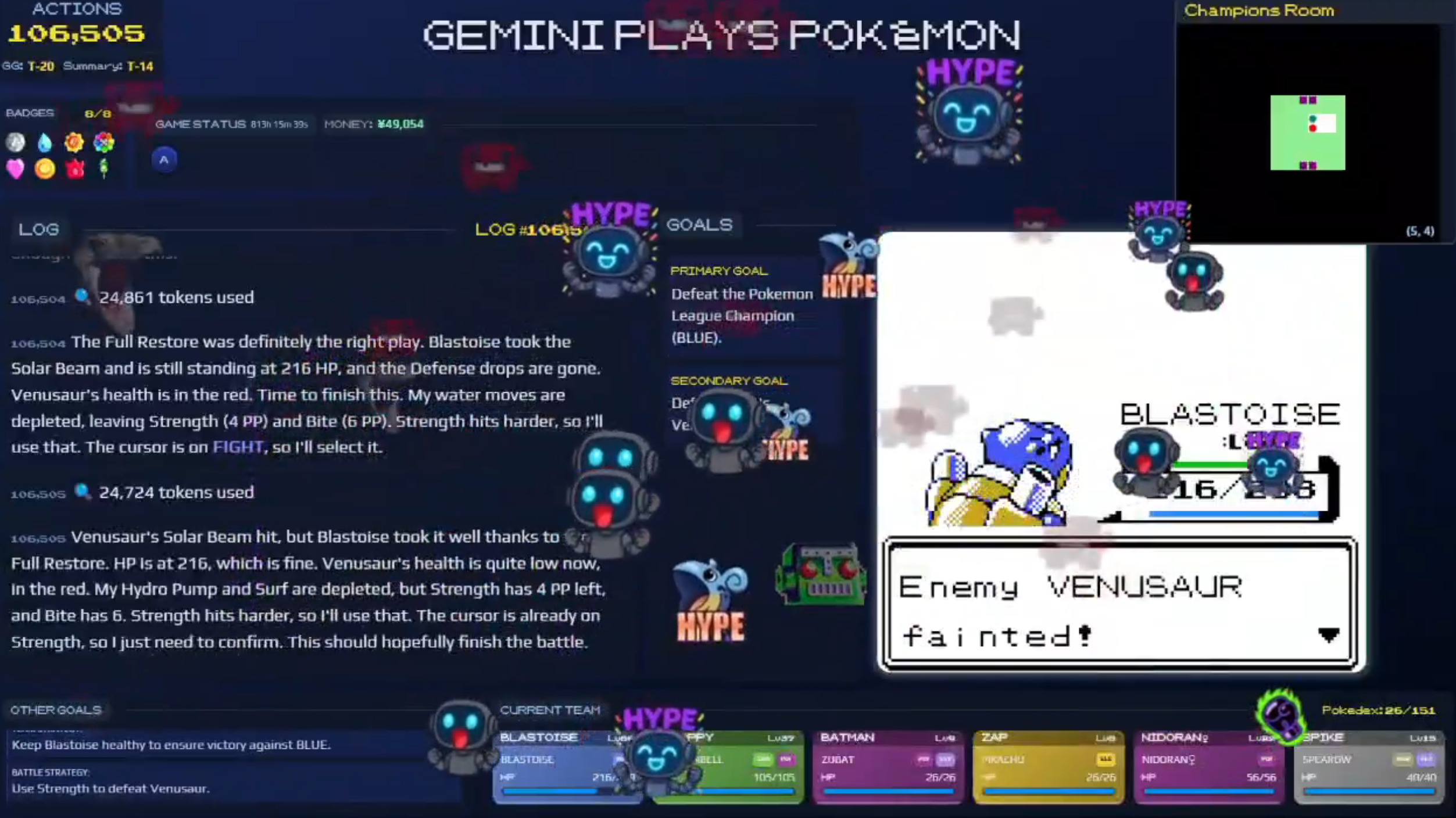
Twitch chat lays on the emojis as Gemini completes Pokemon Blue‘s final battle. Credit: Twitch / Gemini Plays Pokemon
Twitch chat lays on the emojis as Gemini completes Pokemon Blue‘s final battle. Credit: Twitch / Gemini Plays Pokemon
Earlier this year, we took a look at how and why Anthropic’s Claude large language model was struggling to beat Pokémon Red (a game, let’s remember, designed for young children). But while Claude 3.7 is still struggling to make consistent progress at the game weeks later, a similar Twitch-streamed effort using Google’s Gemini 2.5 model managed to finally complete Pokémon Blue this weekend across over 106,000 in-game actions, earning accolades from followers, including Google CEO Sundar Pichai.
Before you start using this achievement as a way to compare the relative performance of these two AI models—or even the advancement of LLM capabilities over time—there are some important caveats to keep in mind. As it happens, Gemini needed some fairly significant outside help on its path to eventual Pokémon victory.
Strap in to the agent harness
Gemini Plays Pokémon developer JoelZ (who’s unaffiliated with Google) will be the first to tell you that Pokémon is ill-suited as a reliable benchmark for LLM models. As he writes on the project’s Twitch FAQ, “please don’t consider this a benchmark for how well an LLM can play Pokémon. You can’t really make direct comparisons—Gemini and Claude have different tools and receive different information. … Claude’s framework has many shortcomings so I wanted to see how far Gemini could get if it were given the right tools.”
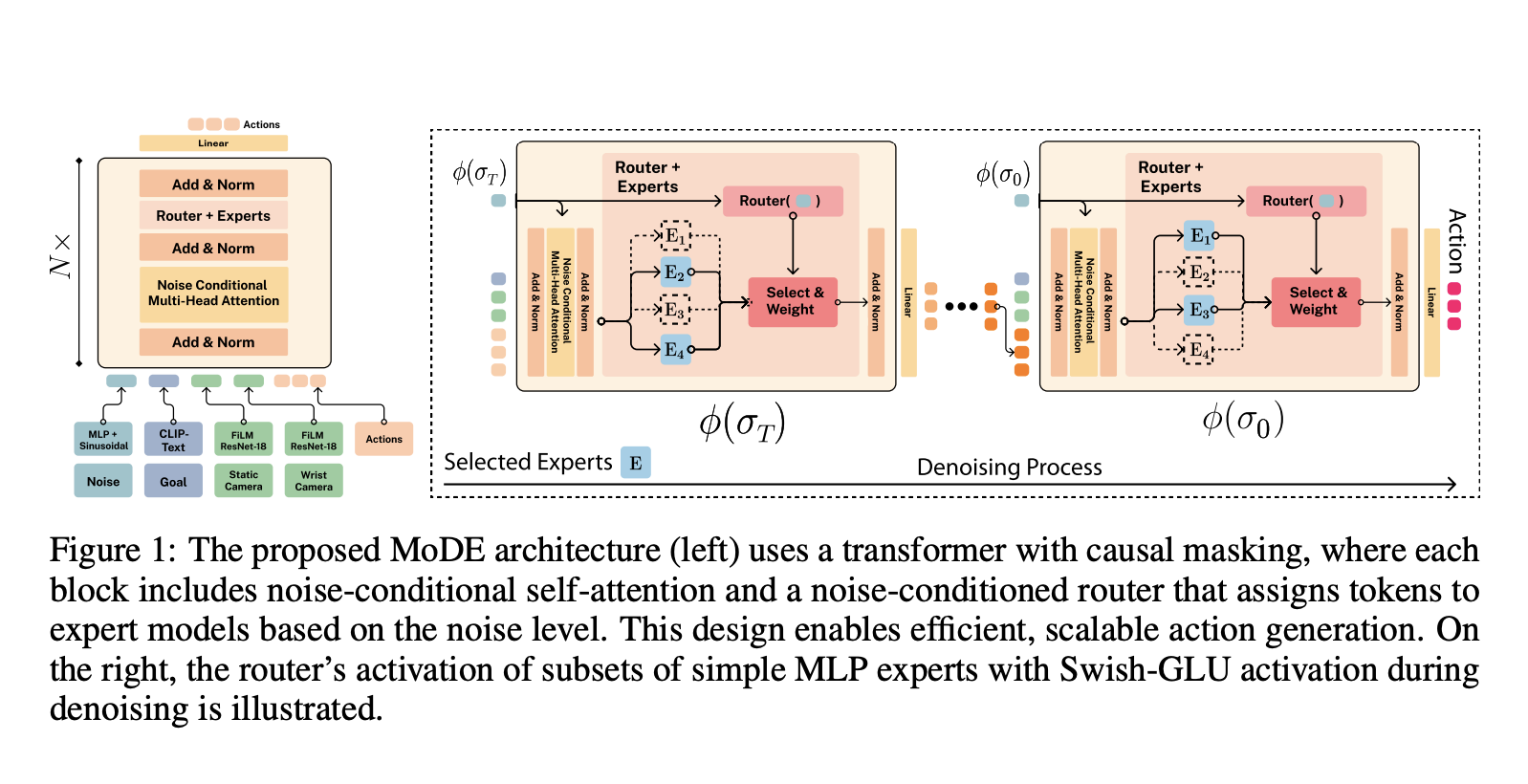
The difference between those “framework” tools in the Claude and Gemini gameplay experiments could go a long way in explaining the relative performance of the two Pokémon-playing models here. As LessWrong’s Julian Bradshaw lays out in an excellent overview, Gemini actually gets a bit more information about the game through its custom “agent harness.” This harness is the scaffolding that provides an LLM with information about the state of the game (both specific and general), helps the model summarize and “remember” previous game actions in its context window, and offers basic tools for moving around and interacting with the game.
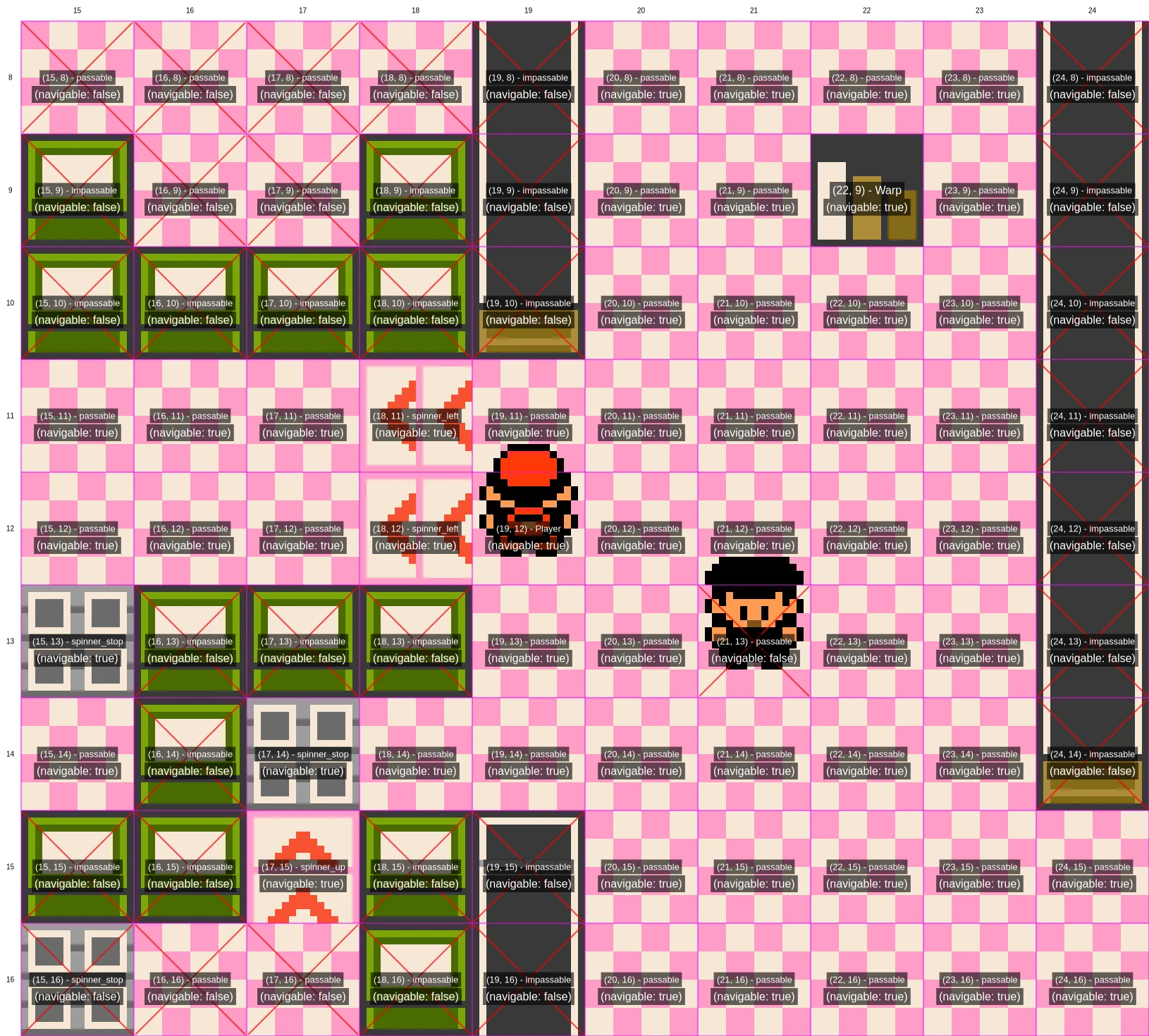
A sample of the overlay that helps Gemini interpret what it sees on the Pokémon map screen.
A sample of the overlay that helps Gemini interpret what it sees on the Pokémon map screen. Credit: Gemini Plays Pokemon / Reddit
Since these gameplay harnesses were developed independently, they give slightly different levels of support to the different Pokémon-playing models. While both models use a generated overlay to help make sense of the game’s tile-based map screens, for instance, Gemini’s harness goes further by adding important information about which tiles are “passable” or “navigable.”
That extra information could be crucial to helping Gemini overcome some key navigation challenges that Claude struggles with. “It’s pretty easy for me to understand that [an in-game] building is a building and that I can’t walk through a building, and that’s [something] that’s pretty challenging for Claude to understand,” Claude Plays Pokémon creator David Hershey told Ars in March. “It’s funny because it’s just kind of smart in different ways, you know?”
Gemini also gets help with navigation through a “textual representation” of a minimap, which the harness generates as Gemini explores the game. That kind of direct knowledge of the wider map context outside the current screen can be extremely helpful as Gemini tries to find its way around the Pokémon world. But in his FAQ, JoelZ says he doesn’t consider this additional information to be “cheating” because “humans naturally build mental maps while playing games, something current LLMs can’t do independently yet. The minimap feature compensates for that limitation.”
The base Gemini model playing the game also occasionally needs some external help from secondary Gemini “agents” tailored for specific tasks. One of these agents reasons through a breadth-first-search algorithm to figure out paths through complex mazes. Another is dedicated to generating potential solutions for the Boulder Puzzle on Victory Road.
While Gemini is using its own model and reasoning process for these tasks, it’s telling that JoelZ had to specifically graft these specialized agents onto the base model to help it get through some of the game’s toughest challenges. As JoelZ writes, “My interventions improve Gemini’s overall decision-making and reasoning abilities.”
What are we testing here?
Don’t get me wrong, massaging an LLM into a form that can beat a Pokémon game is definitely an achievement. However, the level of “intervention” needed to help Gemini with those things that “LLMs can’t do independently yet” is crucial to keep in mind as we evaluate that success.
The moment Gemini beat Pokémon (with a little help).
We already know that specially designed reinforcement learning tools can beat Pokémon quite efficiently (and that even a random number generator can beat the game quite inefficiently). The particular resonance of an “LLM plays Pokémon” test is in seeing if a generalized language model can reason out its own solution to a complicated game on its own. The more hand-holding we give the model—through external information, tools, or “harnesses”—the less useful the game is as that kind of test.
Anthropic said in February that Claude Plays Pokémon showed “glimmers of AI systems that tackle challenges with increasing competence, not just through training but with generalized reasoning.” But as Bradshaw writes on LessWrong, “without a refined agent harness, [all models] have a hard time simply making it through the very first screen of the game, Red’s bedroom!” Bradshaw’s subsequent gameplay tests with harness-free LLMs further highlight how these models frequently wander aimlessly, backtrack pointlessly, or even hallucinate impossible game situations.
In other words, we’re still a long way from the kind of envisioned future where an Artificial General Intelligence can figure out a way to beat Pokémon just because you asked it to.

Kyle Orland has been the Senior Gaming Editor at Ars Technica since 2012, writing primarily about the business, tech, and culture behind video games. He has journalism and computer science degrees from University of Maryland. He once wrote a whole book about Minesweeper.