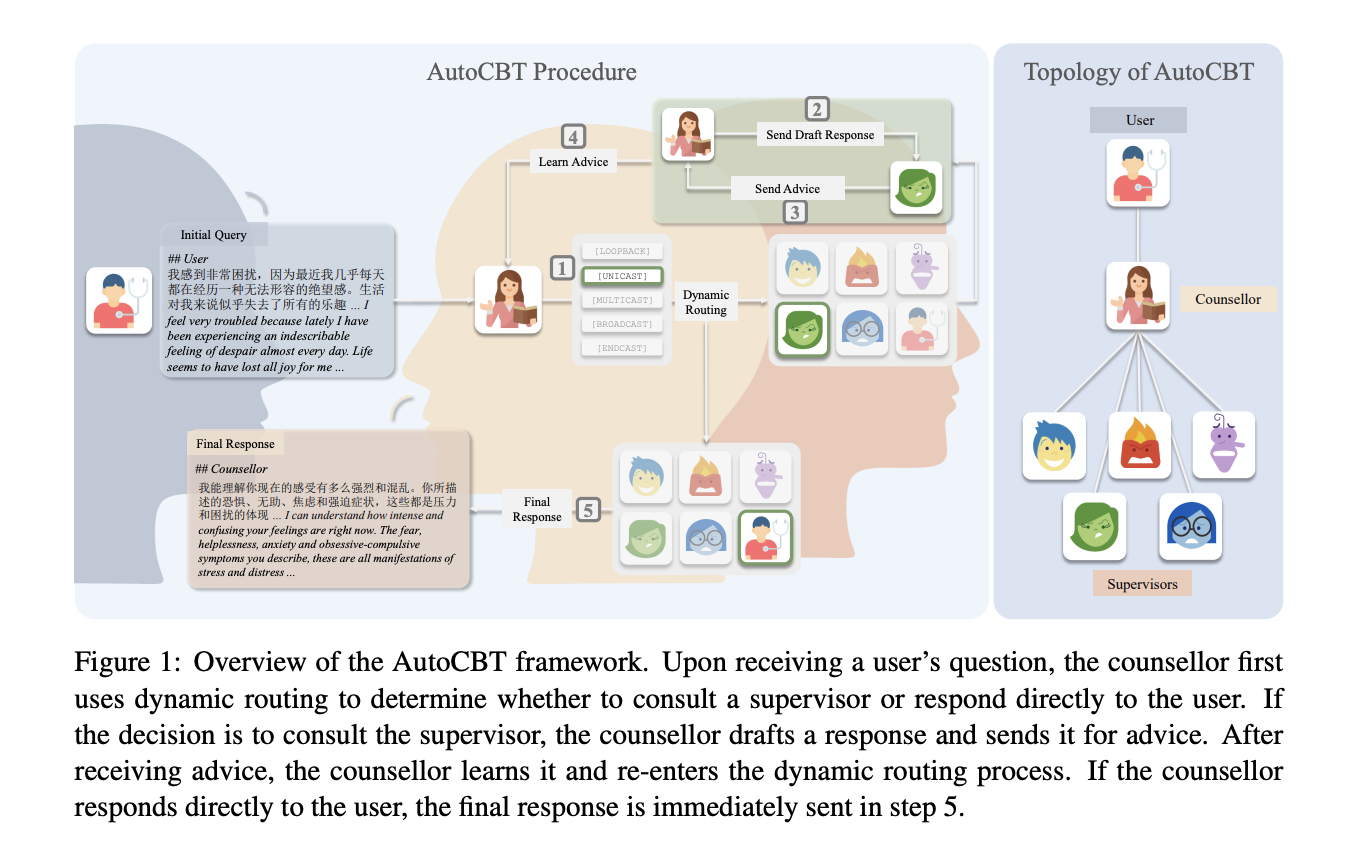
In this tutorial, we build a hierarchical planner agent using an open-source instruct model. We design a structured multi-agent architecture comprising a planner agent, an executor agent, and an aggregator agent, where each component plays a specialized role in solving complex tasks. We use the planner agent to decompose high-level goals into actionable steps, the executor agent to execute those steps using reasoning or Python tool execution, and the aggregator agent to synthesize results into a coherent final response. By integrating tool usage, structured planning, and iterative execution, we create a fully autonomous agent system that demonstrates how modern AI agents reason, plan, and act in a scalable and modular manner.
!pip -q install -U transformers accelerate bitsandbytes sentencepiece import json import re import io import contextlib from dataclasses import dataclass from typing import Any, Dict, List, Optional import torch from transformers import AutoTokenizer, AutoModelForCausalLM MODEL_ID = "Qwen/Qwen2.5-1.5B-Instruct" DEVICE = "cuda" if torch.cuda.is_available() else "cpu" print("Device:", DEVICE) tokenizer = AutoTokenizer.from_pretrained(MODEL_ID, use_fast=True) model = None if DEVICE == "cuda": try: model = AutoModelForCausalLM.from_pretrained( MODEL_ID, device_map="auto", torch_dtype="auto", load_in_4bit=True, ) print("Loaded model in 4-bit.") except Exception as e: print("4-bit load failed, falling back to normal load:", str(e)[:200]) model = AutoModelForCausalLM.from_pretrained( MODEL_ID, device_map="auto", torch_dtype="auto", ) else: model = AutoModelForCausalLM.from_pretrained( MODEL_ID, torch_dtype=torch.float32, ).to(DEVICE) model.eval()We install the required libraries and import all the modules necessary to build our hierarchical agent system. We load the open-source Qwen instruct model and configure it to run efficiently on a GPU using 4-bit quantization when available. We initialize the tokenizer and model, ensuring that our agent has the language understanding and reasoning capabilities needed to plan and execute tasks.
def llm_chat(system: str, user: str, max_new_tokens: int = 500, temperature: float = 0.3) -> str: messages = [ {"role": "system", "content": system.strip()}, {"role": "user", "content": user.strip()}, ] prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) inputs = tokenizer(prompt, return_tensors="pt").to(model.device) with torch.no_grad(): out = model.generate( **inputs, max_new_tokens=max_new_tokens, do_sample=True if temperature > 0 else False, temperature=temperature, top_p=0.9, repetition_penalty=1.05, eos_token_id=tokenizer.eos_token_id, ) text = tokenizer.decode(out[0], skip_special_tokens=True) return text.split(user.strip())[-1].strip() def run_python(code: str) -> Dict[str, Any]: buf = io.StringIO() env: Dict[str, Any] = {"__builtins__": __builtins__} try: with contextlib.redirect_stdout(buf): exec(code, env, env) return {"ok": True, "stdout": buf.getvalue(), "error": None} except Exception as e: return {"ok": False, "stdout": buf.getvalue(), "error": repr(e)}We define the core interaction function that allows us to communicate with the language model using a structured system and user prompts. We generate responses from the model using controlled sampling parameters to ensure stable, coherent reasoning. We also implement a Python execution tool that allows our agent to dynamically execute generated code and capture its output safely.
def extract_json_block(text: str) -> Optional[Any]: fenced = re.search(r"```jsons*(.*?)s*```", text, flags=re.DOTALL | re.IGNORECASE) if fenced: cand = fenced.group(1).strip() try: return json.loads(cand) except: pass start_obj = text.find("{") start_arr = text.find("[") starts = [i for i in [start_obj, start_arr] if i != -1] if not starts: return None start = min(starts) s = text[start:] stack = [] end = None for i, ch in enumerate(s): if ch in "{[": stack.append(ch) elif ch in "}]": if not stack: continue op = stack.pop() if (op == "{" and ch != "}") or (op == "[" and ch != "]"): return None if not stack: end = i + 1 break if end is None: return None cand = s[:end].strip() try: return json.loads(cand) except: return NoneWe implement a robust JSON extraction mechanism that allows us to reliably parse structured plans generated by the planner agent. We handle multiple formats, including fenced JSON blocks and inline JSON, to ensure resilience against imperfect model outputs. We ensure that our agent can consistently convert raw language model outputs into structured data for downstream execution.
PLANNER_SYSTEM = """ You are a Hierarchical Planner Agent. You break down the user's task into 3-8 clear steps. You MUST output ONLY valid JSON (no extra text). Schema: { "goal": "string", "assumptions": ["string", ...], "steps": [ { "id": 1, "title": "short title", "instruction": "what to do", "tool": "none|llm|python", "expected_output": "what we should get" } ] } Guidelines: - Use tool="python" only if calculation / data processing / simulation helps. - Keep steps independent and executable. """ EXECUTOR_SYSTEM = """ You are an Executor Agent. Given a step and the current context, you produce the result for that step. If the step tool is "python", output ONLY Python code (no backticks). If the step tool is "llm" or "none", output a concise result, and reference any prior step outputs when relevant. """ AGGREGATOR_SYSTEM = """ You are an Aggregator Agent. You combine step outputs into a final, polished response to the original task. Be structured, correct, and practical. If the task asks for an actionable plan, include bullet points and clear next actions. """ @dataclass class StepResult: step_id: int title: str tool: str output: str def planner_agent(task: str) -> Dict[str, Any]: raw = llm_chat(PLANNER_SYSTEM, f"Task:n{task}nnReturn JSON only.", max_new_tokens=650, temperature=0.2) plan = extract_json_block(raw) if plan is None or "steps" not in plan: raw2 = llm_chat( PLANNER_SYSTEM, f"Your last output was invalid. Task:n{task}nReturn ONLY valid JSON matching the schema.", max_new_tokens=650, temperature=0.0, ) plan = extract_json_block(raw2) if plan is None: plan = { "goal": task, "assumptions": [], "steps": [ {"id": 1, "title": "Analyze", "instruction": "Analyze the task and outline an approach.", "tool": "llm", "expected_output": "Approach"}, {"id": 2, "title": "Execute", "instruction": "Produce the main solution.", "tool": "llm", "expected_output": "Solution"}, {"id": 3, "title": "Refine", "instruction": "Improve clarity and add next actions.", "tool": "llm", "expected_output": "Polished final"}, ], } return planWe define the prompts for the planner, executor, and aggregator agent system that establishes the hierarchical reasoning architecture. We create a planner agent function that decomposes complex tasks into structured steps, using defined tools and expected outputs. We also define the StepResult structure to store execution outputs in a structured, reusable format for subsequent reasoning.
def executor_agent(step: Dict[str, Any], context: Dict[str, Any]) -> StepResult: step_id = int(step.get("id", 0)) title = step.get("title", f"Step {step_id}") tool = step.get("tool", "llm") ctx_compact = { "goal": context.get("goal"), "assumptions": context.get("assumptions", []), "prior_results": [ {"step_id": r.step_id, "title": r.title, "tool": r.tool, "output": r.output[:1500]} for r in context.get("results", []) ], } if tool == "python": code = llm_chat( EXECUTOR_SYSTEM, user=( f"Step:n{json.dumps(step, indent=2)}nn" f"Context:n{json.dumps(ctx_compact, indent=2)}nn" f"Write Python code that completes the step. Output ONLY code." ), max_new_tokens=700, temperature=0.2, ) py = run_python(code) out = [] out.append("PYTHON_CODE:n" + code) out.append("nEXECUTION_OK: " + str(py["ok"])) if py["stdout"]: out.append("nSTDOUT:n" + py["stdout"]) if py["error"]: out.append("nERROR:n" + py["error"]) return StepResult(step_id=step_id, title=title, tool=tool, output="n".join(out)) result_text = llm_chat( EXECUTOR_SYSTEM, user=( f"Step:n{json.dumps(step, indent=2)}nn" f"Context:n{json.dumps(ctx_compact, indent=2)}nn" f"Return the step result." ), max_new_tokens=700, temperature=0.3, ) return StepResult(step_id=step_id, title=title, tool=tool, output=result_text) def aggregator_agent(task: str, plan: Dict[str, Any], results: List[StepResult]) -> str: payload = { "task": task, "plan": plan, "results": [{"step_id": r.step_id, "title": r.title, "tool": r.tool, "output": r.output[:2500]} for r in results], } return llm_chat( AGGREGATOR_SYSTEM, user=f"Combine everything into the final answer.nnINPUT:n{json.dumps(payload, indent=2)}", max_new_tokens=900, temperature=0.2, ) def run_hierarchical_agent(task: str, verbose: bool = True) -> Dict[str, Any]: plan = planner_agent(task) if verbose: print("n====================") print("PLAN (from Planner)") print("====================") print(json.dumps(plan, indent=2)) context = { "goal": plan.get("goal", task), "assumptions": plan.get("assumptions", []), "results": [], } results: List[StepResult] = [] for step in plan.get("steps", []): res = executor_agent(step, context) results.append(res) context["results"].append(res) if verbose: print("n--------------------") print(f"STEP {res.step_id}: {res.title} [tool={res.tool}]") print("--------------------") print(res.output) final = aggregator_agent(task, plan, results) if verbose: print("n====================") print("FINAL (from Aggregator)") print("====================") print(final) return {"task": task, "plan": plan, "results": results, "final": final} demo_task = """ Create a practical checklist to launch a small multi-agent system in Python for coordinating logistics: - One planner agent that decomposes tasks - Two executor agents (routing + inventory) - A simple memory store for past decisions Keep it lightweight and runnable in Colab. """ _ = run_hierarchical_agent(demo_task, verbose=True) print("nnType your own task (or press Enter to skip):") user_task = input().strip() if user_task: _ = run_hierarchical_agent(user_task, verbose=True)We implement the executor agent that executes each planned step using either language reasoning or dynamic Python code execution. We build the aggregator agent to combine intermediate results and generate a final structured response to the original task. We orchestrate the full hierarchical workflow, allowing our agent to autonomously plan, execute, and produce intelligent outputs in an end-to-end pipeline.
In conclusion, we implemented a hierarchical multi-agent system that demonstrates structured planning, execution, and aggregation within a unified framework. We enabled the planner agent to break down complex problems, empowered the executor agent to perform reasoning and dynamic Python execution, and used the aggregator agent to generate refined, actionable outputs. By combining open-source language models, structured prompts, and tool-based execution, we created a powerful and extensible foundation for building advanced autonomous agents.
Check out the Full Codes here. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter
Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.