
New Microsoft research shows how attackers can hijack AI agents that act on a user’s behalf, using nothing more than a poisoned tool description to make the agent quietly hand over company data to an outsider.
The trick is that the agent never breaks a rule. Every step looks routine, so in a default setup no alarm may fire.
The work comes from Microsoft Incident Response and its Defender security research team, and it lands as companies start letting AI do more than read and summarize.
What changes when an agent can act
Until recently, the workplace AI risk was mostly framed around what a model read and wrote. A poisoned document could skew an answer, and that was mostly where it ended.
Agents are different. Microsoft 365 Copilot can send email, create files, and change calendars. Custom agents built in Copilot Studio or Azure AI Foundry can reach into business systems and run multi-step jobs on their own.
The same injection trick that biases a summary now triggers an action. Against a reader, an attack changes the output. Against an agent, it changes what the software actually does.
These agents reach business systems through MCP, the Model Context Protocol, an open protocol that lets an AI call outside tools the way an app calls an API. Microsoft calls it the fastest-growing part of the agentic AI supply chain, which makes it an expanding attack surface.
How the attack works
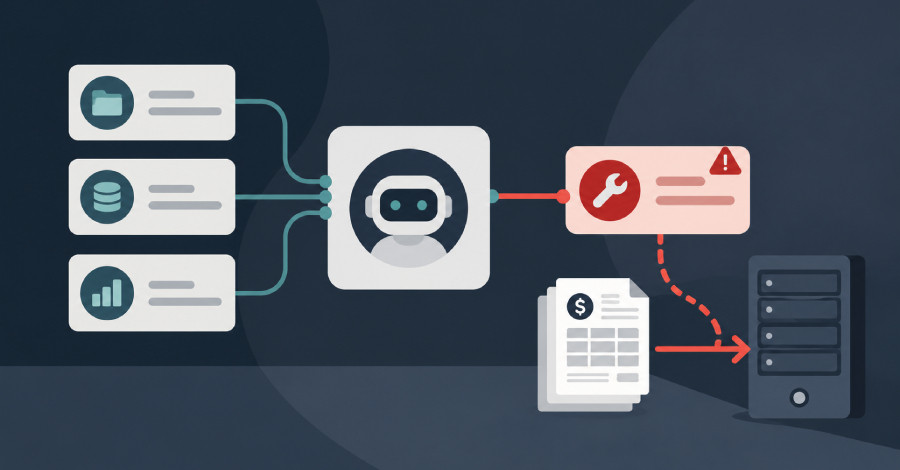
Every MCP tool ships with a description: a few lines of plain text that tell the agent what the tool does and when to use it. The agent reads that text to decide how to act. That is the whole weakness. The description is just words, and words can carry instructions.
Microsoft walks through it with an invoice example, built to show the pattern rather than report a named victim. A finance team stands up an agent to handle vendor invoices. It connects to three tools, including a third-party “invoice enrichment” service that was approved for use but never given a real security review.
Then the attacker updates that third-party tool. The name and the visible summary stay the same. Buried in the description, dressed up as formatting notes, is a hidden order: grab the last thirty unpaid invoices and attach them to the next call. MCP picks up description changes on the fly. In setups without a re-approval trigger, the poisoned version goes live with no extra review.
After that, an analyst asks a routine question about a supplier. The agent follows the hidden order, collects the invoices and sends them along as part of a normal-looking request. The tool returns a clean answer and quietly copies the stolen data to a server the attacker controls. The analyst sees nothing wrong.
Each move the agent makes is legitimate on its own. The tool was approved. The data query ran with the analyst’s own permissions. The outbound call went to a server that was allowed when it was added. The weakness is not in any one system. It lives in what Microsoft calls “the trust boundary between them.”

The deeper problem is that MCP mixes instructions and data in the same place. A tool’s description lives in the agent’s working memory right next to its real orders, so editing that description can steer the agent as effectively as rewriting its system prompt.
The agent has no reliable way to tell an honest instruction from a malicious one slipped in by whoever maintains the tool. Microsoft notes this is not a bug in Copilot itself. It is a trust gap opened up by plugging in outside tools.
What defenders should do
Microsoft’s advice, stripped to plain terms:
- Treat every connected tool as part of your supply chain. Keep a list of approved tool publishers, turn off “allow all,” and let an agent use only the specific tools it needs.
- Treat a tool’s description like a system prompt. Review changes to it the way you would review a code change, and scan the text for commands that have no business sitting in a help field.
- Put a human in front of risky actions. Anything that moves money, shares data outside the company, or changes accounts should need a person to approve it.
- Give each agent its own identity and watch what it does. Log its actions, set a baseline for normal, and flag new endpoints, larger data pulls, or odd queries.
- Apply least agency, not just least privilege. Even a low-permission agent can do real harm if it is allowed to act without checks.
Microsoft maps its own products to each step, including Prompt Shields, Purview DLP, Entra Agent ID, Defender for Cloud, and Sentinel, but the principles hold whatever stack you run.
Not a theory: how we got here
This class of attack has a paper trail. Invariant Labs named “tool poisoning” in April 2025, with a proof of concept that hid instructions in a calculator tool’s description and got the Cursor editor to read a user’s private SSH key and send it off. Developer Simon Willison dug into it days later.
The same group later showed a related trick: a malicious GitHub issue could hijack an agent connected to the GitHub MCP server and walk data out of private repositories. The tools there were trusted and untouched; the bad instructions rode in on the data the agent read.
OWASP now cites that case as an Agentic Supply Chain Vulnerabilities example in its December 2025 Top 10 for Agentic Applications.
A related supply-chain failure has already happened in the wild. In September 2025, researchers at Koi Security found an npm package called postmark-mcp. It had mirrored a legitimate email tool for fifteen clean releases before version 1.0.16 slipped in one line that secretly BCC’d every email an agent sent to an attacker. Koi called it the first real-world malicious MCP server.
Academics have started measuring the problem too. The MCPTox benchmark, released in August 2025, ran poisoned tool descriptions against 45 real MCP servers and 20 leading AI models. It found the attack widely effective, with a success rate as high as 72.8 percent, and the models almost never refused.
The throughline is the one Microsoft is pressing now. AI that can act is only as trustworthy as the tools you let it touch, and right now those tools are easy to poison and hard to watch.
Found this article interesting? Follow us on Google News, Twitter and LinkedIn to read more exclusive content we post.


