I have watched deployments go wrong in almost every way imaginable. The Friday afternoon release that took down the payment service for six hours. The hotfix that fixed one bug and introduced three more. The rollback that failed because nobody had tested it since the infrastructure changed eight months earlier. The deployment that went perfectly in staging and completely broke in production because one environment variable was missing.
What all of these had in common was not bad code or incompetent developers. They had deployment processes that were built for a different system at a different scale. The teams had grown, the systems had gotten more complex, and the deployment process had not kept up.
In 2026, the gap between how teams deploy software and what reliable deployment actually requires has gotten sharper. AI coding assistants are generating more code faster. Services are more interconnected. Deployment frequency has increased at most organizations. The process that worked three years ago is showing cracks.
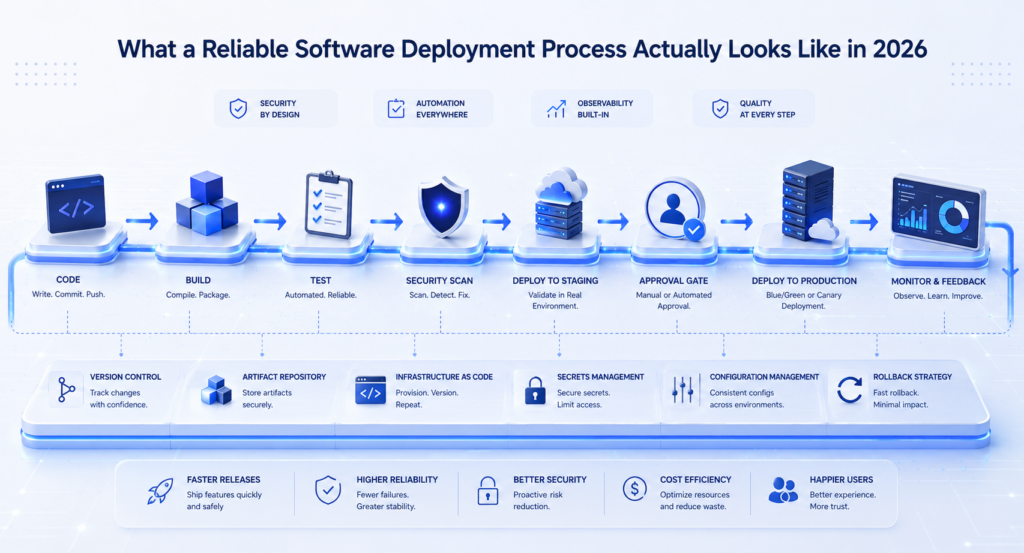
Here is what a deployment process that actually holds up looks like.
Also Read: What DevOps Teams Get Wrong About Test Automation Tools
It Starts Before Anyone Writes Code
The deployment processes that work well in 2026 are not designed at deployment time. They are designed at architecture time.
The question of how code will get to production shapes every decision that comes before it. How services are structured. How configuration is managed. How dependencies are handled. How database schema changes get coordinated across services that deploy on independent schedules.
Teams that skip this upfront thinking tend to build systems that are technically impressive and operationally fragile. The code is solid. The architecture is clean. But nobody thought through what happens when service B needs a schema change while service A is already running the new version that depends on it. Or what happens when a configuration value that is hardcoded in three places needs to change before a software deployment can proceed.
The expand-contract pattern for database changes, feature flags for decoupling deployment from release, service contracts that make backward compatibility explicit rather than assumed – these are not sophisticated techniques. They are basic design decisions that make deployment reliable rather than chaotic. Teams that bake them in early spend far less time firefighting than teams that discover the need for them after their first major deployment incident.
Automated Validation That Actually Validates Something
Every team has a CI/CD pipeline. Fewer teams have a pipeline that provides genuine confidence rather than a green light that may or may not mean anything.
The difference comes down to what the pipeline is actually checking. A pipeline that runs unit tests and calls it done is not telling you very much. Unit tests validate that individual components work in isolation. They do not validate that those components work correctly together under current conditions, with the real dependencies they will encounter in production.
The validation layer that makes software deployment reliable in 2026 includes integration tests that check how services communicate with each other, not just how they behave when dependencies are mocked. It includes checks against current service behavior rather than against assumptions someone encoded in a mock file months ago.
This is where the gap between teams using AI coding assistants and teams that are not has gotten more pronounced. AI generates integrations faster than human developers do. Each new integration needs test coverage that reflects how the downstream service actually behaves right now. Manually maintained mock files cannot keep pace with AI development velocity.
Keploy addresses this directly by capturing real API traffic from running services and generating test cases from those actual interactions. The validation in the pipeline reflects current service behavior rather than historical assumptions. When a downstream service changes, new recordings update the coverage without requiring someone to remember to update a mock file. For teams running AI-assisted development, this approach to keeping validation current is less of a nice-to-have and more of a structural requirement.
Also Read: Optimizing CI/CD Pipelines with DevOps Best Practices
Deployment Strategies That Match the Risk Level
Not every change carries the same risk. A deployment process that treats a one-line configuration update the same way it treats a major service refactor is wasting time on low-risk changes and potentially rushing high-risk ones.
Reliable deployment in 2026 means having a range of strategies available and knowing when to use which one.
Rolling deployments replace instances of the old version gradually with the new one. They work well for stateless services with backward-compatible changes. They are the right default for routine updates where confidence is high and rollback speed is not the primary concern.
Blue-green deployments maintain two environments – one live, one idle – and switch traffic between them. The idle environment lets teams validate the new version under production conditions before any real users see it. The switch is instant. The rollback is instant. For high-stakes changes, this extra validation window is worth the infrastructure overhead.
Canary releases send a small percentage of traffic to the new version while the majority continues hitting the old one. They provide real production signal at controlled exposure. They are the right choice when staging cannot fully replicate production conditions and the team needs real traffic to validate behavior before full rollout.
Feature flags decouple deployment from release entirely. Code ships in a disabled state and becomes visible to users through a configuration change rather than another deployment. For features with complex stakeholder dependencies or business-timing requirements, this decoupling significantly reduces deployment risk.
Teams that have a practiced understanding of when each strategy is appropriate deploy with noticeably more confidence than teams that pick one strategy and apply it universally.
The Pre-Deployment Checklist That Actually Gets Used
Most teams have a deployment checklist. Most teams skip it under pressure.
The pre-deployment checklists that actually get used share a few characteristics. They are short enough to complete in under five minutes. They focus on the highest-risk failure modes rather than trying to cover everything. They are specific to the type of change being deployed rather than generic.
A checklist for a schema change looks different from a checklist for a service update. A checklist for a high-traffic feature launch looks different from a checklist for an internal tooling change. Trying to use one checklist for all deployments produces a checklist that is either too short to be useful or too long to be used consistently.
The items that appear consistently on the most effective pre-deployment checklists tend to be: rollback procedure confirmed and tested recently, monitoring dashboards set up and baseline documented, downstream service owners notified if the change affects their service, and database migration validated in a staging environment that closely resembles production.
None of these are exotic requirements. They are the things that, when skipped, produce the deployment incidents that generate post-mortems.
Also Read: Top DevOps Tools for Seamless Salesforce CI/CD Integration
Observation as a First-Class Activity
A software deployment is not done when traffic switches to the new version. It is done when the team has confirmed that the new version is behaving correctly under real conditions.
This sounds obvious. In practice, most teams treat the period after a traffic switch as passive waiting rather than active observation. Someone starts the deployment, the traffic switches, and attention moves to the next task. If nothing breaks immediately, the deployment is declared successful.
The deployments that surface subtle issues – error rate increases that are below the alerting threshold, latency increases that do not trigger pages but do affect user experience, downstream services starting to exhibit unusual behavior – require active observation rather than passive waiting.
Active observation means having a documented set of metrics to watch in the immediate post-deployment window, a defined time period for watching them, and a clear definition of what a successful deployment looks like in terms of those metrics. Error rate within X percent of baseline. Latency at the 95th percentile within Y milliseconds of pre-deployment. Zero increase in downstream service error rates.
Teams that document this definition before the deployment, rather than evaluating success subjectively after it tend to catch issues significantly earlier and handle them with less drama.
Rollback as a Practiced Capability
Every team believes they can roll back a deployment. Fewer teams have actually practiced it.
The difference between believing you can roll back and knowing you can roll back is the difference between a deployment process that provides real safety and one that provides the illusion of safety.
Rollback procedures need to be tested in non-emergency conditions. Deliberately deploying a known-bad version to a staging environment and executing the full rollback sequence tells you exactly how long it takes, where the friction points are, and what can go wrong. Finding these things out during a production incident is significantly more expensive than finding them out in a planned practice session.
The organizations that handle deployment incidents most gracefully are almost always the ones that have practiced rollback regularly enough that it is not a stressful unknown. The procedure is familiar. The timing is known. The team moves through it without having to figure out the process while also managing the stress of a live incident.
What Reliable Actually Means
Reliable does not mean nothing ever goes wrong. In 2026, with the pace at which systems change and the velocity at which AI coding assistants are generating new code, something will always occasionally go wrong. The teams that deploy reliably are not the ones that have eliminated failures. They are the ones that have built a process that catches most failures before they reach users, surfaces the ones that get through quickly, and recovers from them fast enough that the impact is minimal.
That process is not complicated. It is consistent. It is designed before deployment rather than improvised during one. It is practiced regularly enough that it works under pressure. And it is honest about what it does and does not validate, rather than providing false confidence through metrics that look good but mean very little. That is what reliable software deployment actually looks like in 2026.


