
TL;DR: AgentFlow is a trainable agent framework with four modules—Planner, Executor, Verifier, Generator—coordinated by an explicit memory and toolset. The […]
Category: AI Paper Summary

Stanford Researchers Introduced MedAgentBench: A Real-World Benchmark for Healthcare AI Agents
A team of Stanford University researchers have released MedAgentBench, a new benchmark suite designed to evaluate large language model (LLM) […]

NVIDIA AI Open-Sources ViPE (Video Pose Engine): A Powerful and Versatile 3D Video Annotation Tool for Spatial AI
How do you create 3D datasets to train AI for Robotics without expensive traditional approaches? A team of researchers from […]

UT Austin and ServiceNow Research Team Releases AU-Harness: An Open-Source Toolkit for Holistic Evaluation of Audio LLMs
Voice AI is becoming one of the most important frontiers in multimodal AI. From intelligent assistants to interactive agents, the […]

Google AI Releases VaultGemma: The Largest and Most Capable Open Model (1B-parameters) Trained from Scratch with Differential Privacy
Google AI Research and DeepMind have released VaultGemma 1B, the largest open-weight large language model trained entirely with differential privacy […]

Meet mmBERT: An Encoder-only Language Model Pretrained on 3T Tokens of Multilingual Text in over 1800 Languages and 2–4× Faster than Previous Models
Table of contents Why was a new multilingual encoder needed? Understanding the architecture of mmBERT What training data and phases […]
Baidu Releases ERNIE-4.5-21B-A3B-Thinking: A Compact MoE Model for Deep Reasoning
Baidu AI Research team has just released ERNIE-4.5-21B-A3B-Thinking, a new reasoning-focused large language model designed around efficiency, long-context reasoning, and […]

MBZUAI Researchers Release K2 Think: A 32B Open-Source System for Advanced AI Reasoning and Outperforms 20x Larger Reasoning Models
A team of researchers from MBZUAI’s Institute of Foundation Models and G42 released K2 Think, is a 32B-parameter open reasoning […]

ParaThinker: Scaling LLM Test-Time Compute with Native Parallel Thinking to Overcome Tunnel Vision in Sequential Reasoning
Why Do Sequential LLMs Hit a Bottleneck? Test-time compute scaling in LLMs has traditionally relied on extending single reasoning paths. […]
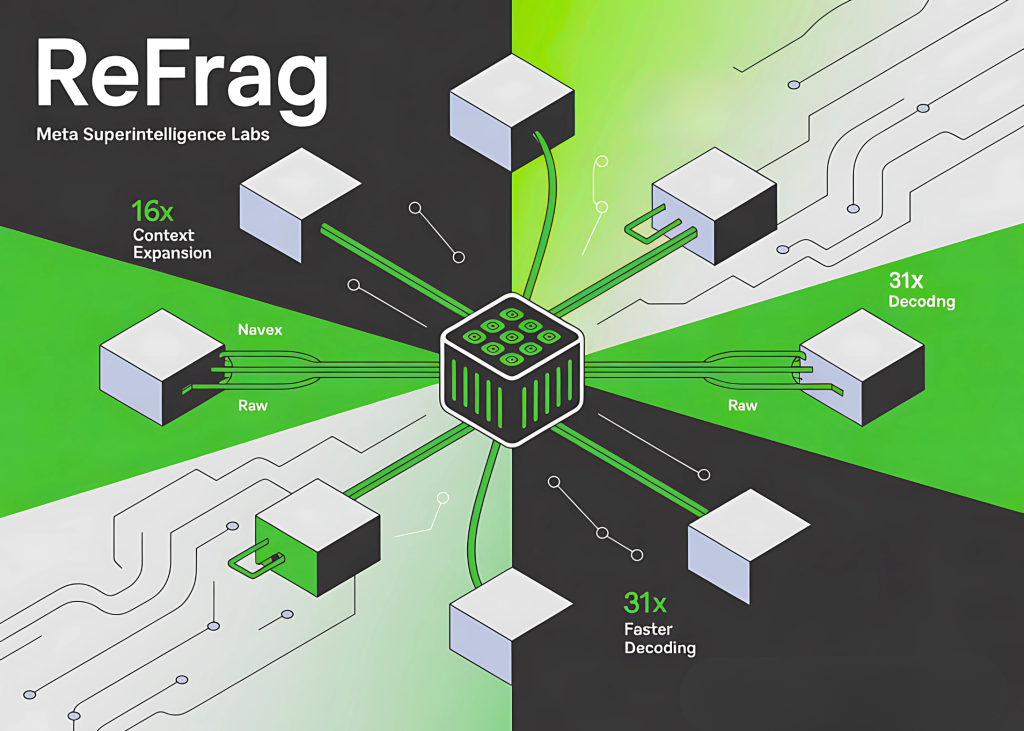
Meta Superintelligence Labs Introduces REFRAG: Scaling RAG with 16× Longer Contexts and 31× Faster Decoding
Table of contents Why is long context such a bottleneck for LLMs? How does REFRAG compress and shorten context? How […]