
A team of researchers from Google Research, Google DeepMind, and Yale released C2S-Scale 27B, a 27-billion-parameter foundation model for single-cell […]
Category: AI Paper Summary

QeRL: NVFP4-Quantized Reinforcement Learning (RL) Brings 32B LLM Training to a Single H100—While Improving Exploration
What would you build if you could run Reinforcement Learning (RL) post-training on a 32B LLM in 4-bit NVFP4—on a […]

Meta AI’s ‘Early Experience’ Trains Language Agents without Rewards—and Outperforms Imitation Learning
How would your agent stack change if a policy could train purely from its own outcome-grounded rollouts—no rewards, no demos—yet […]

NVIDIA Researchers Propose Reinforcement Learning Pretraining (RLP): Reinforcement as a Pretraining Objective for Building Reasoning During Pretraining
NVIDIA AI has introduced Reinforcement Learning Pretraining (RLP), a training objective that injects reinforcement learning into the pretraining stage rather […]
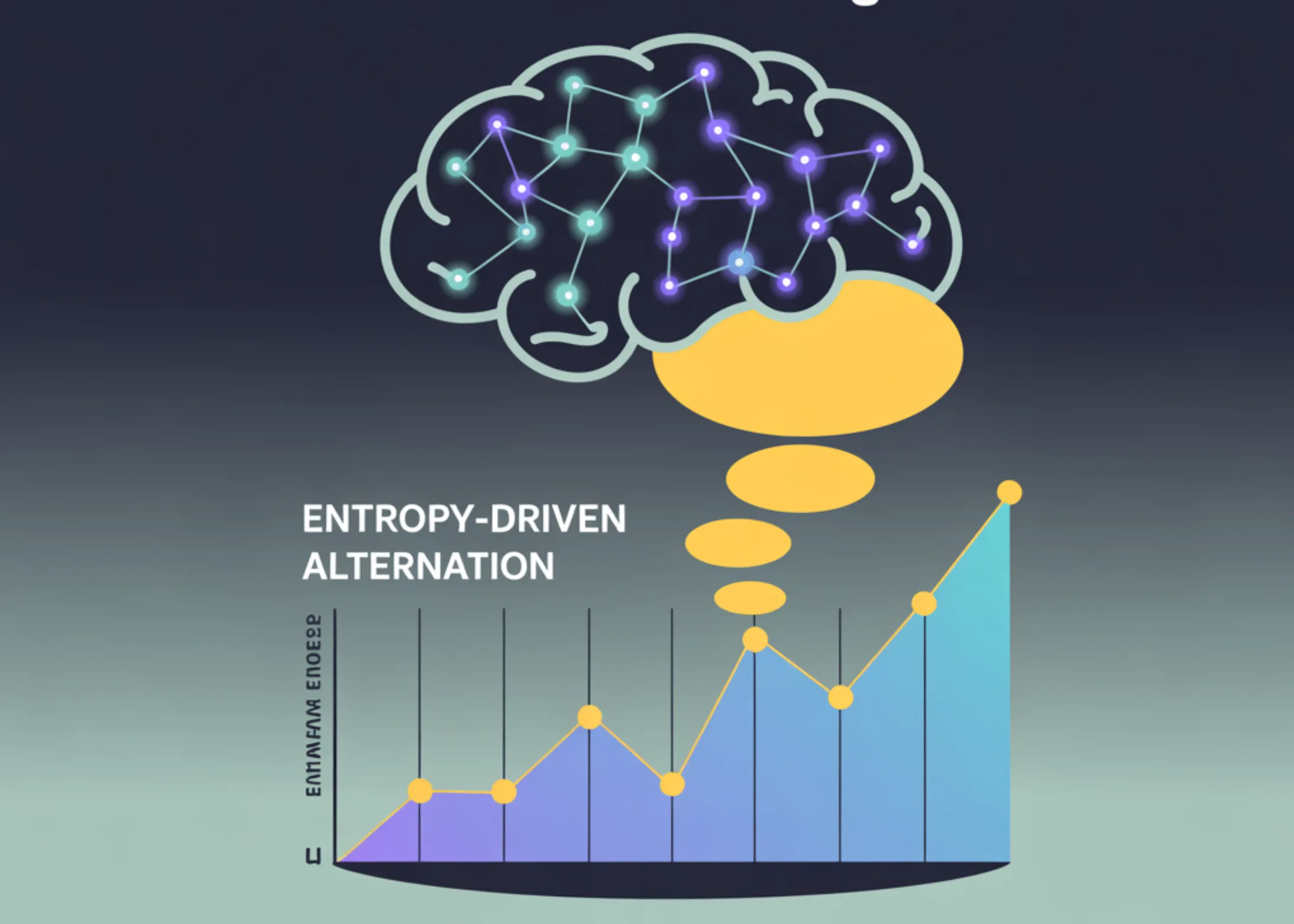
SwiReasoning: Entropy-Driven Alternation of Latent and Explicit Chain-of-Thought for Reasoning LLMs
SwiReasoning is a decoding-time framework that lets a reasoning LLM decide when to think in latent space and when to […]

Meet OpenTSLM: A Family of Time-Series Language Models (TSLMs) Revolutionizing Medical Time-Series Analysis
A significant development is set to transform AI in healthcare. Researchers at Stanford University, in collaboration with ETH Zurich and […]

Agentic Context Engineering (ACE): Self-Improving LLMs via Evolving Contexts, Not Fine-Tuning
TL;DR: A team of researchers from Stanford University, SambaNova Systems and UC Berkeley introduce ACE framework that improves LLM performance […]

Microsoft Research Releases Skala: a Deep-Learning Exchange–Correlation Functional Targeting Hybrid-Level Accuracy at Semi-Local Cost
TL;DR: Skala is a deep-learning exchange–correlation functional for Kohn–Sham Density Functional Theory (DFT) that targets hybrid-level accuracy at semi-local cost, […]

Tiny Recursive Model (TRM): A Tiny 7M Model that Surpass DeepSeek-R1, Gemini 2.5 pro, and o3-mini at Reasoning on both ARG-AGI 1 and ARC-AGI 2
Can an iterative draft–revise solver that repeatedly updates a latent scratchpad outperform far larger autoregressive LLMs on ARC-AGI? Samsung SAIT […]

RA3: Mid-Training with Temporal Action Abstractions for Faster Reinforcement Learning (RL) Post-Training in Code LLMs
TL;DR: A new research from Apple, formalizes what “mid-training” should do before reinforcement learning RL post-training and introduces RA3 (Reasoning […]