Groundbreaking AI System Sets New State-of-the-Art Records on BrowseComp, BrowseComp-ZH, and FrontierScience Benchmarks — Outperforming GPT-5.4, Claude-4.6-Opus, and Gemini-3.1-Pro
, /PRNewswire/ — MiroMind announced the release of MiroThinker-1.7 and the flagship system built on it, MiroThinker-H1, representing a fundamental leap forward in AI research agent design. Rather than simply scaling model size or training compute, MiroThinker introduces a paradigm-shifting approach called “Effective Interaction Scaling” — improving the quality and reliability of every reasoning step, rather than blindly increasing the number of steps. MiroThinker-H1 has achieved state-of-the-art results across the most demanding multi-step reasoning and deep research benchmarks in the field, surpassing frontier systems from OpenAI, Anthropic, and Google DeepMind.

The Breakthrough: Verification-Centric Reasoning
At the heart of MiroThinker-H1 lies a novel dual-layer verification system integrated directly into the model’s reasoning process at inference time — a capability absent from conventional LLM training pipelines:
- Local Verifier: Audits intermediate reasoning decisions in real time — including planning steps, tool invocations, and hypothesis updates — correcting errors early before they compound. On the hard subset of the BrowseComp benchmark, the Local Verifier reduced average interaction steps by ~82%, while simultaneously improving accuracy by +26.4 points. This eliminates the “brute-force trial-and-error” pattern endemic to existing agentic systems.
- Global Verifier: After a reasoning trajectory is complete, the Global Verifier audits the entire chain of evidence and compares candidate solution paths. By leveraging the principle of generation-verification asymmetry (verification is easier than generation), it ensures that final answers are only delivered when supported by a fully coherent, well-grounded evidence trail. If evidence is insufficient, the system automatically requests the agent to resample or extend its reasoning — preventing premature or hallucinated conclusions.
This “think, verify locally, verify globally, then answer” paradigm represents a structural departure from standard autoregressive LLM inference.
Technical Architecture: Novel Contribution Training Pipeline
MiroThinker models are trained through an agent-centric, four-stage integrated pipeline that builds capability from the ground up:
Stage 1 — Agentic Mid-Training
Before any standard fine-tuning, models undergo a dedicated stage to strengthen atomic agentic capabilities: structured planning, contextual reasoning, tool interaction, and answer summarization. This involves:
- A large-scale cold-start planning corpus — teaching the model to generate structured plans from a user query alone, filtered by a taxonomy-aware planner–judge pipeline to reject low-quality outputs.
- Context-conditioned reasoning sculpting — isolating individual turns from successful multi-step trajectories and rewriting them into higher-quality reasoning and summarization targets, improving evidence consolidation step by step.
Stage 2 — Supervised Fine-Tuning (SFT)
The model learns structured interaction from expert thought–action–observation triplets, cleaned by a rule-based pipeline to eliminate repetitions and malformed tool calls.
Stage 3 — Preference Optimization (DPO)
Direct Preference Optimization aligns the model using answer correctness as the sole ranking signal — a deliberate design choice that avoids structural biases introduced by rigidly enforcing fixed output patterns.
Stage 4 — Reinforcement Learning with GRPO
The final stage uses Group Relative Policy Optimization (GRPO) for online trial-and-error refinement in live environments, with two critical innovations:
- Targeted Entropy Control: An auxiliary KL penalty is applied specifically to low-probability tokens in unsuccessful rollouts to sustain creative exploration and prevent premature convergence.
- Priority Scheduling: Ensures that difficult, long-tailed rollouts are completed and incorporated into training early — preventing the system from being biased toward easy examples.
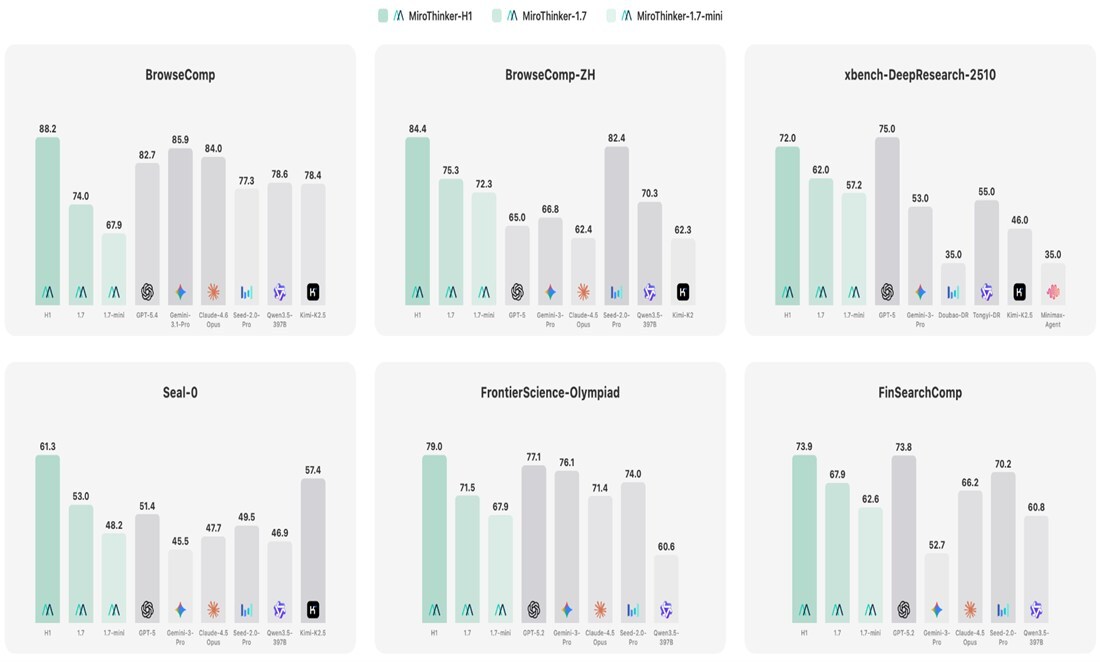
Benchmark Results: Outperforming Global Frontier Models
MiroThinker-H1 achieves state-of-the-art results across the most rigorous real-world research benchmarks:
On BrowseComp, MiroThinker-H1 (88.2) outperforms Gemini-3.1-Pro (85.9), Claude-4.6-Opus (84.0), and GPT-5.4 (82.7). On BrowseComp-ZH, MiroThinker-H1 (84.4) leads all evaluated frontier models, outperforming Seed-2.0-Pro (82.4) and GPT-5 (65.0). On FrontierScience-Olympiad, MiroThinker-H1 (79.0) surpasses GPT-5.2 (77.1) and Gemini-3-Pro (76.1) — establishing new state-of-the-art results across both open-web research and scientific reasoning.
In long-form deep research report generation (DeepResearchEval, 50 complex queries), MiroThinker-1.7 achieves the highest Report Quality score (76.5) among the evaluated deep research agents, surpassing OpenAI Deep Research (76.4) and Gemini-3.1-Pro Deep Research (72.3). It also attains strong Factuality scores, with OpenAI Deep Research leading on overall factuality performance.
Efficiency at Scale: The MiroThinker-1.7-mini Achievement
In a striking demonstration of “effective interaction scaling,” MiroThinker-1.7-mini — our efficient, lightweight research agent— delivers highly competitive performance:
- BrowseComp-ZH: 72.3 — outperforming GPT-5 (65.0) and Claude-4.5-Opus (62.4)
- Seal-0: 48.2 — outperforming Claude-4.5-Opus (47.7) and Gemini-3-Pro (45.5)
Compared to the prior-generation MiroThinker-1.5, MiroThinker-1.7-mini achieves 16.7% better performance with 43% fewer interaction rounds on average over five benchmarks — conclusively demonstrating that improving step quality is more effective than simply generating longer reasoning chains.
Why This Matters: A Shift in AI Research Agent Design
“The key insight behind MiroThinker is that scaling interaction quality — not quantity — is the path to reliable long-horizon reasoning. By verifying decisions at both the local step level and the global trajectory level, we have built a system that reasons more like a careful human expert than a stochastic text predictor.”
— MiroMind Research Team
MiroThinker-H1 addresses the core failure modes of existing research agents: error accumulation in long chains, hallucinated conclusions unsupported by evidence, and computationally wasteful “brute-force” search strategies. Its verification-centric architecture represents a new design template for trustworthy, efficient, and factually grounded AI reasoning systems.
About MiroMind:
MiroMind is a Global AI frontier lab headquartered in Redwood City, CA, with its co-R&D and operational hub in Singapore, building the world’s first General Purpose Solver – a reasoning-first AI system engineered not merely to appear correct, but to be provably right. By pioneering verifiable, long-chain System 2 reasoning, MiroMind delivers AI that is reliable and trusted for the highest-stakes problems spanning software engineering, financial services, healthcare and pharma, legal and compliance, and scientific research. MiroMind was founded by Tianqiao Chen, backed by a team that is 80%+ PhD researchers and led by a world-class scientific leadership team across the globe.
Website:https://www.miromind.ai
Github: https://github.com/MiroMindAI/MiroThinker
HuggingFace: https://huggingface.co/collections/miromind-ai/mirothinker-17
MiroMind is hiring:[email protected]
Download:
App Store:https://apps.apple.com/app/id6759390724
Google Play:https://play.google.com/store/apps/details?id=ai.miromind.app
SOURCE MiroMind.ai



